一��、 Pandas簡介
1�����、Python Data Analysis Library 或 pandas 是基于NumPy 的一種工具,該工具是為了解決數據分析任務而創建的。Pandas 納入了大量庫和一些標準的數據模型����,提供了高效地操作大型數據集所需的工具��。pandas提供了大量能使我們快速便捷地處理數據的函數和方法。你很快就會發現��,它是使Python成為強大而高效的數據分析環境的重要因素之一���。
2��、Pandas 是python的一個數據分析包��,最初由AQR Capital Management于2008年4月開發,并于2009年底開源出來����,目前由專注于Python數據包開發的PyData開發team繼續開發和維護�����,屬于PyData項目的一部分。Pandas最初被作為金融數據分析工具而開發出來����,因此�,pandas為時間序列分析提供了很好的支持��。 Pandas的名稱來自于面板數據(panel data)和python數據分析(data analysis)���。panel data是經濟學中關于多維數據集的一個術語�,在Pandas中也提供了panel的數據類型�����。
3����、數據結構:
Series:一維數組���,與Numpy中的一維array類似����。二者與Python基本的數據結構List也很相近�����,其區別是:List中的元素可以是不同的數據類型�����,而Array和Series中則只允許存儲相同的數據類型,這樣可以更有效的使用內存,提高運算效率��。
Time- Series:以時間為索引的Series���。
DataFrame:二維的表格型數據結構����。很多功能與R中的data.frame類似�����。可以將DataFrame理解為Series的容器����。以下的內容主要以DataFrame為主�。
Panel :三維的數組�����,可以理解為DataFrame的容器。
Pandas 有兩種自己獨有的基本數據結構。讀者應該注意的是,它固然有著兩種數據結構���,因為它依然是 Python 的一個庫,所以,Python 中有的數據類型在這里依然適用����,也同樣還可以使用類自己定義數據類型��。只不過,Pandas 里面又定義了兩種數據類型:Series 和 DataFrame,它們讓數據操作更簡單了����。
二��、Python Pandas的使用
修改列數據:
df['price']=df['price'].str.replace('人均','') # 刪除多余文字
df['price']=df['price'].str.split("¥").str[-1] # 分割文本串
df['price']=df['price'].str.replace('-','0') # 替換文本
df['price']=df['price'].astype(int) # 文本轉整型
把pandas轉換int型為str型的方法
切分列數據:
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("環境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服務",'')
注意:pandas中操作如果不明確指定參數,則不會修改原數據,而是返回一個新對象�。
刪除列數據:
排序列數據:
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
注意:排序前先用astype轉換正確的類型�����,如str、int或float
重新設置索引列標簽順序:
df.columns=['類型','店鋪名稱','點評數量','星級','人均消費','店鋪地址','口味','環境','服務']
打印前幾行數據:
print(df.loc[:,['店鋪名稱','口味','人均消費']].head(6))
# 或者 # print(df.iloc[0:6,[1,6,4]]) # 前6行(整數)
# 但不能是 # print(df.loc[0:6,['店鋪名稱','口味','人均消費']]) # 從索引0到索引6的行(對象)
https://www.jb51.net/article/155602.htm
綜合示例:
圖例:
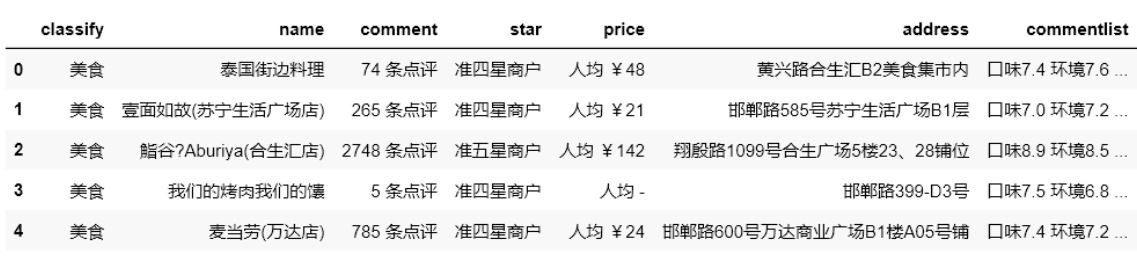
結果:
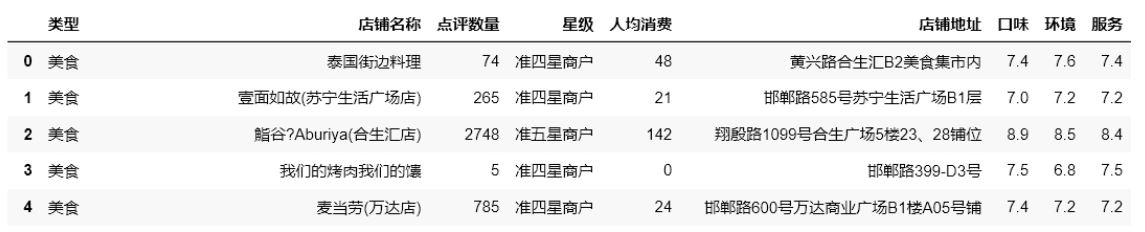
要求:
(1)對該數據中的comment、price進行數據清洗整理�,
(2)將commentlist數據拆分為“口味”��、“環境”和“服務”三列后再進行數據清洗整理,
(3)去除commentlist列數據
(4)將此數據按“口味”降序、“人均消費”升序進行排序,
(5)輸出排序后前6條數據中的“店鋪名稱”、“口味”和“人均消費”三列數據��。
代碼:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk') #讀入文件�����,編碼為gbk # 注意編碼�,重要
#對數據進行清洗
df['comment']=df['comment'].str.replace('條點評','')
df['price']=df['price'].str.replace('人均','')
df['price']=df['price'].str.split("¥").str[-1]
df['price']=df['price'].str.replace('-','0')
df['price']=df['price'].astype(int)
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("環境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服務",'')
del df['commentlist']
#按口味降序�����,人均消費升序進行排序
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
#重新設置列索引標簽
df.columns=['類型','店鋪名稱','點評數量','星級','人均消費','店鋪地址','口味','環境','服務']
print(df.loc[:,['店鋪名稱','口味','人均消費']].head(6))
方法二:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk')
df['comment']=df['comment'].str.replace('條點評','')
df['price']=df['price'].str.replace('人均','').str.replace('¥','').str.replace('-','0').str.replace(' ','').astype(int)
df[['kw','hj','fw']]=df['commentlist'].str.replace('口味','').str.replace('環境','').str.replace('服務','').str.split(expand=True).astype(float) # expand將普通的列表轉為DataFrame對象
del df['commentlist']
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True) # 注意inplace=True
df.columns=['類型','店鋪名稱','點評數量','星級','人均消費','店鋪地址','口味','環境','服務']
print(df[['店鋪名稱','口味','人均消費']].head(6))
注意:df.str.split是列表,加了expand=True之后才是DataFrame對象�,或者用.str[x]提取某一列�,注意不是df.str.split()[x]而是df.str.split().str[x]��,前者是對list(二維)操作�,后者是對DataFrame操作(取某一列)
到此這篇關于Python Pandas的簡單使用教程的文章就介紹到這了,更多相關Python Pandas使用內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- Python Pandas分組聚合的實現方法
- python中pandas對多列進行分組統計的實現
- 詳解python pandas 分組統計的方法
- Python Pandas實現數據分組求平均值并填充nan的示例
- Python學習筆記之pandas索引列����、過濾�����、分組�����、求和功能示例
- Python pandas入門系列之眾數和分位數
- Python pandas求方差和標準差的方法實例
- python geopandas讀取、創建shapefile文件的方法
- 使用Python pandas讀取CSV文件應該注意什么?
- 利用python Pandas實現批量拆分Excel與合并Excel
- python pandas分組聚合詳細
