目錄
- 背景介紹
- 一��、模擬登陸
- 二、爬取商品信息
- 1. 定義相關參數
- 2. 分析并定義正則
- 3. 數據爬取
- 三����、簡單數據分析
- 1.導入庫
- 2.中文顯示
- 3.讀取數據
- 4.分析價格分布
- 5.分析銷售地分布
- 6.詞云分析
- 寫在最后
Tip:本文僅供學習與交流����,切勿用于非法用途?��。�。?/p>
背景介紹
有個同學問我:“XXX�,有沒有辦法搜集一下淘寶的商品信息啊�����,我想要做個統計”。于是乎�����,閑來無事的我�����,又開始琢磨起這事…

一�、模擬登陸
興致勃勃的我��,沖進淘寶就準備一頓亂搜:

在搜索欄里填好關鍵詞:“顯卡”����,小手輕快敲擊著回車鍵(小樣~看我的)
心情愉悅的我等待著返回滿滿的商品信息���,結果苦苦的等待換了的卻是302,于是我意外地來到了登陸界面�。
情況基本就是這么個情況了…
然后我查了一下,隨著淘寶反爬手段的不斷加強���,很多小伙伴應該已經發現,淘寶搜索功能是需要用戶登陸的����!
關于淘寶模擬登陸��,有大大已經利用requests成功模擬登陸(感興趣的小伙伴請往這邊>>>requests登陸淘寶)
這個方法得先分析淘寶登陸的各種請求,并模擬生成相應的參數��,相對來說有一定的難度����。于是我決定換一種思路,通過selenium+二維碼的方式:
# 打開圖片
def Openimg(img_location):
img=Image.open(img_location)
img.show()
# 登陸獲取cookies
def Login():
driver = webdriver.PhantomJS()
driver.get('https://login.taobao.com/member/login.jhtml')
try:
driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
except:
pass
time.sleep(3)
# 執行JS獲得canvas的二維碼
JS = 'return document.getElementsByTagName("canvas")[0].toDataURL("image/png");'
im_info = driver.execute_script(JS) # 執行JS獲取圖片信息
im_base64 = im_info.split(',')[1] #拿到base64編碼的圖片信息
im_bytes = base64.b64decode(im_base64) #轉為bytes類型
time.sleep(2)
with open('./login.png','wb') as f:
f.write(im_bytes)
f.close()
t = threading.Thread(target=Openimg,args=('./login.png',))
t.start()
print("Logining...Please sweep the code!\n")
while(True):
c = driver.get_cookies()
if len(c) > 20: #登陸成功獲取到cookies
cookies = {}
for i in range(len(c)):
cookies[c[i]['name']] = c[i]['value']
driver.close()
print("Login in successfully!\n")
return cookies
time.sleep(1)
通過webdriver打開淘寶登陸界面�����,把二維碼下載到本地并打開等待用戶掃碼(相應的元素大家通過瀏覽器的F12元素分析很容易就能找出)��。待掃碼成功后��,將webdriver里的cookies轉為DICT形式,并返回���。(這里是為了后續requests爬取信息的時候使用)
二、爬取商品信息
當我拿到cookies之后�,便能對商品信息進行爬取了��。
(小樣 ~我來啦)
1. 定義相關參數
定義相應的請求地址,請求頭等等:
# 定義參數
headers = {'Host':'s.taobao.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate, br',
'Connection':'keep-alive'}
list_url = 'http://s.taobao.com/search?q=%(key)sie=utf8s=%(page)d'
2. 分析并定義正則
當請求得到HTML頁面后����,想要得到我們想要的數據就必須得對其進行提取����,這里我選擇了正則的方式�����。通過查看頁面源碼:
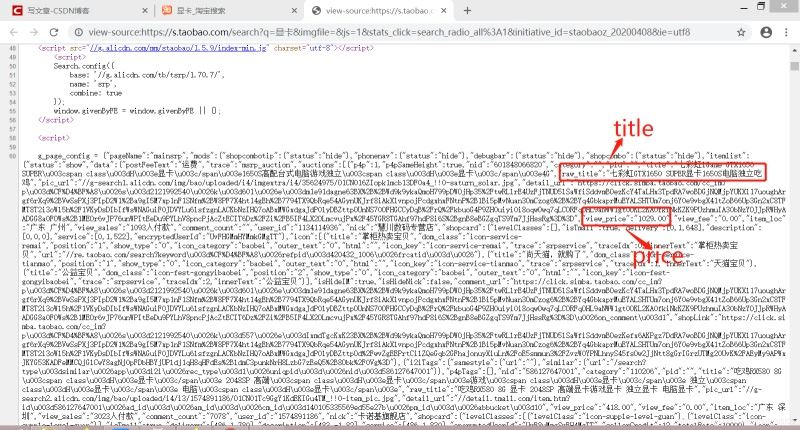
偷懶的我上面只標志了兩個數據,不過其他也是類似的����,于是得到以下正則:
# 正則模式
p_title = '"raw_title":"(.*?)"' #標題
p_location = '"item_loc":"(.*?)"' #銷售地
p_sale = '"view_sales":"(.*?)人付款"' #銷售量
p_comment = '"comment_count":"(.*?)"'#評論數
p_price = '"view_price":"(.*?)"' #銷售價格
p_nid = '"nid":"(.*?)"' #商品唯一ID
p_img = '"pic_url":"(.*?)"' #圖片URL
(ps.聰明的小伙伴應該已經發現了��,其實商品信息是被保存在了g_page_config變量里面,所以我們也可以先提取這個變量(一個字典)�,然后再讀取數據���,也可?���。?/p>
3. 數據爬取
完事具備�,只欠東風。于是,東風來了:
# 數據爬取
key = input('請輸入關鍵字:') # 商品的關鍵詞
N = 20 # 爬取的頁數
data = []
cookies = Login()
for i in range(N):
try:
page = i*44
url = list_url%{'key':key,'page':page}
res = requests.get(url,headers=headers,cookies=cookies)
html = res.text
title = re.findall(p_title,html)
location = re.findall(p_location,html)
sale = re.findall(p_sale,html)
comment = re.findall(p_comment,html)
price = re.findall(p_price,html)
nid = re.findall(p_nid,html)
img = re.findall(p_img,html)
for j in range(len(title)):
data.append([title[j],location[j],sale[j],comment[j],price[j],nid[j],img[j]])
print('-------Page%s complete!--------\n\n'%(i+1))
time.sleep(3)
except:
pass
data = pd.DataFrame(data,columns=['title','location','sale','comment','price','nid','img'])
data.to_csv('%s.csv'%key,encoding='utf-8',index=False)
上面代碼爬取20也商品信息�����,并將其保存在本地的csv文件中�,效果是這樣的:
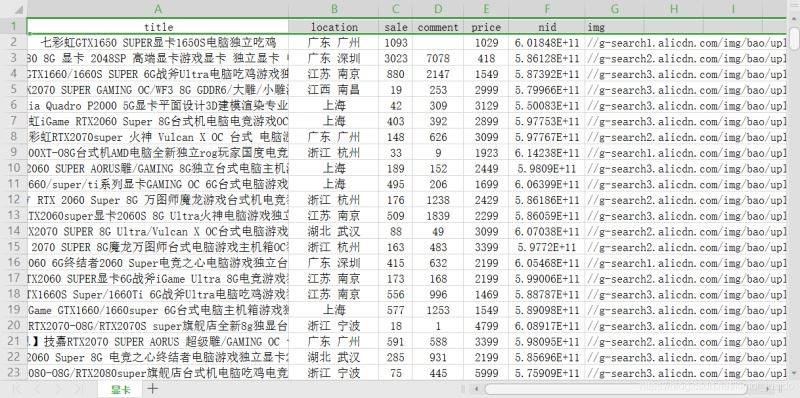
三、簡單數據分析
有了數據,放著豈不是浪費���,我可是社會主義好青年,怎能做這種事? 那么,就讓我們來簡單看看這些數據叭:
(當然��,數據量小�,僅供娛樂參考)
1.導入庫
# 導入相關庫
import jieba
import operator
import pandas as pd
from wordcloud import WordCloud
from matplotlib import pyplot as plt
相應庫的安裝方法(其實基本都能通過pip解決):
- jieba
- pandas
- wordcloud
- matplotlib
2.中文顯示
# matplotlib中文顯示
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
不設置可能出現中文亂碼等鬧心的情況哦~
3.讀取數據
# 讀取數據
key = '顯卡'
data = pd.read_csv('%s.csv'%key,encoding='utf-8',engine='python')
4.分析價格分布
# 價格分布
plt.figure(figsize=(16,9))
plt.hist(data['price'],bins=20,alpha=0.6)
plt.title('價格頻率分布直方圖')
plt.xlabel('價格')
plt.ylabel('頻數')
plt.savefig('價格分布.png')
價格頻率分布直方圖:

5.分析銷售地分布
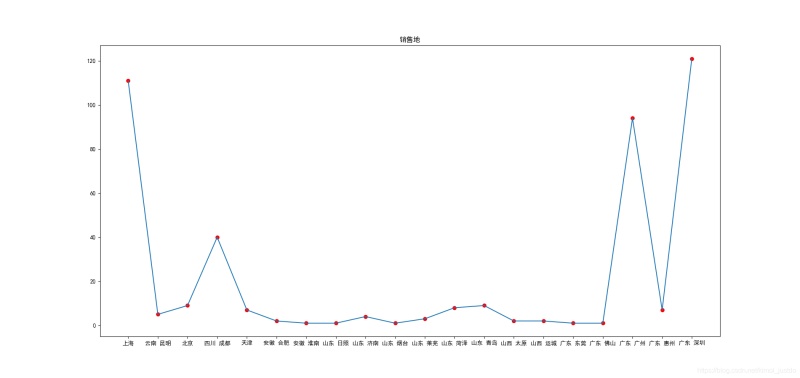
# 銷售地分布
group_data = list(data.groupby('location'))
loc_num = {}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
plt.figure(figsize=(19,9))
plt.title('銷售地')
plt.scatter(list(loc_num.keys())[:20],list(loc_num.values())[:20],color='r')
plt.plot(list(loc_num.keys())[:20],list(loc_num.values())[:20])
plt.savefig('銷售地.png')
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1),reverse=True)#排序
loc_num_10 = sorted_loc_num[:10] #取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16,9))
plt.title('銷售地TOP10')
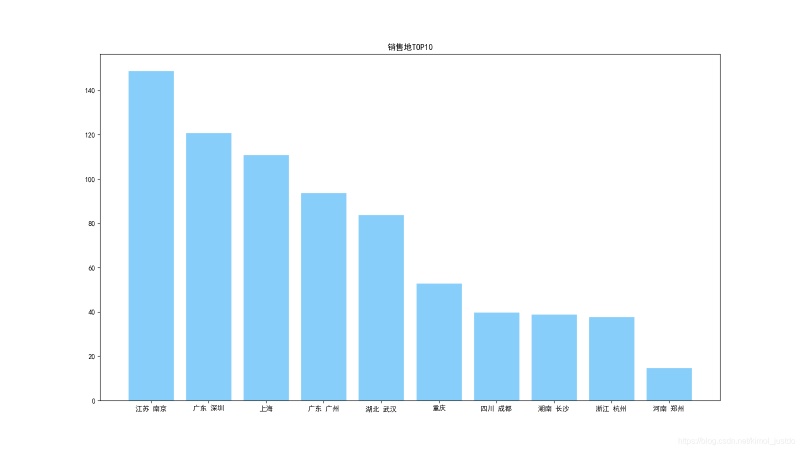
plt.bar(loc_10,num_10,facecolor = 'lightskyblue',edgecolor = 'white')
plt.savefig('銷售地TOP10.png')
銷售地分布:
銷售地TOP10:
6.詞云分析
# 制作詞云
content = ''
for i in range(len(data)):
content += data['title'][i]
wl = jieba.cut(content,cut_all=True)
wl_space_split = ' '.join(wl)
wc = WordCloud('simhei.ttf',
background_color='white', # 背景顏色
width=1000,
height=600,).generate(wl_space_split)
wc.to_file('%s.png'%key)
淘寶商品”顯卡“的詞云:

寫在最后
感謝各位大大的耐心閱讀~
到此這篇關于用python爬取分析淘寶商品信息詳解技術篇的文章就介紹到這了,更多相關python爬取淘寶商品信息內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Unity打開淘寶app并跳轉到商品頁面功能的實現方法
- 備戰618!用Python腳本幫你實現淘寶秒殺
- python淘寶準點秒殺搶單的實現示例
- python 利用百度API進行淘寶評論關鍵詞提取
- Python 爬取淘寶商品信息欄目的實現
- Python實現淘寶秒殺功能的示例代碼
