目錄
- 一、解析PDF(簡歷內推)
- 二、發送郵件
- 三、操作execl
- 1. 關聯公式:Vlookup
- 2. 數據透視表
- 3. 對比兩列差異
- 4. 去除重復值
- 5. 缺失值處理
- 6. 多條件篩選
- 7. 模糊篩選數據
- 8. 分類匯總
- 9. 條件計算
- 10. 刪除數據間的空格
- 四、畫圖分析
- 五、解析word(docx、doc)
- 六、計算器
- 總結
一、解析PDF(簡歷內推)
應用場景:簡歷內推(解析內容:包括不限于姓名、郵箱、電話號碼、學歷等信息)
輸入:要解析的文件路徑
輸出:需要解析的內容(點我主頁,詳見歷史文章)
環境準備:python 3.6 、mac(下文中doc轉docx是mac寫法,windows更簡單,導入win32的包即可)
依賴包:
# encoding: utf-8
import os, sys
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
二、發送郵件
有幾個模塊用于訪問互聯網以及處理網絡通信協議。其中最簡單的兩個是用于處理從 urls 接收的數據的 urllib.request 以及用于發送電子郵件的 smtplib:
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
參數說明:
host: SMTP 服務器主機。 你可以指定主機的ip地址或者域名如: runoob.com,這個是可選參數。
port: 如果你提供了 host 參數, 你需要指定 SMTP 服務使用的端口號,一般情況下 SMTP 端口號為25。
local_hostname: 如果 SMTP 在你的本機上,你只需要指定服務器地址為 localhost 即可。
Python SMTP 對象使用 sendmail 方法發送郵件,語法如下:
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options])
參數說明:
- from_addr: 郵件發送者地址。
- to_addrs: 字符串列表,郵件發送地址。
- msg: 發送消息
案例:
#!/usr/bin/python# -*- coding: UTF-8 -*-
import smtplibfrom email.mime.text
import MIMETextfrom email.header
import Header sender = 'from@runoob.com'
# 西紅柿微:ZPYDWXYreceivers = ['1221121@qq.com']
# 接收郵件,可設置為你的QQ郵箱或者其他郵箱
# 三個參數:第一個為文本內容,第二個 plain 設置文本格式,第三個 utf-8 設置編碼message = MIMEText('Python 郵件發送測試...', 'plain', 'utf-8')message['From'] = Header("不吃西紅柿", 'utf-8')
# 發送者message['To'] = Header("測試", 'utf-8')
# 接收者 subject = 'Python SMTP 郵件測試'message['Subject'] = Header(subject, 'utf-8')
try: smtpObj = smtplib.SMTP('localhost') smtpObj.sendmail(sender, receivers, message.as_string())
print "郵件發送成功"except smtplib.SMTPException:
print "Error: 無法發送郵件"
三、操作execl
1. 關聯公式:Vlookup
vlookup是excel幾乎最常用的公式,一般用于兩個表的關聯查詢等。所以我先把這張表分為兩個表。
#查看訂單明細號是否重復,結果是沒。
df1["訂單明細號"].duplicated().value_counts()
df2["訂單明細號"].duplicated().value_counts()
df_c=pd.merge(df1,df2,on="訂單明細號",how="left")
2. 數據透視表
需求:想知道每個地區的業務員分別賺取的利潤總和與利潤平均數。
pd.pivot_table(sale,index="地區名稱",columns="業務員名稱",values="利潤",aggfunc=[np.sum,np.mean])
3. 對比兩列差異
需求:比較訂單明細號與訂單明細號2的差異并顯示出來。
sale["訂單明細號2"]=sale["訂單明細號"]
#在訂單明細號2里前10個都+1.
sale["訂單明細號2"][1:10]=sale["訂單明細號2"][1:10]+1
#差異輸出
result=sale.loc[sale["訂單明細號"].isin(sale["訂單明細號2"])==False]
4. 去除重復值
需求:去除業務員編碼的重復值
sale.drop_duplicates("業務員編碼",inplace=True)
5. 缺失值處理
#用0填充缺失值
sale["客戶名稱"]=sale["客戶名稱"].fillna(0)
#刪除有客戶編碼缺失值的行
sale.dropna(subset=["客戶編碼"])
6. 多條件篩選
需求:想知道業務員張愛,在北京區域賣的商品訂單金額大于6000的信息。
sale.loc[(sale["地區名稱"]=="北京")(sale["業務員名稱"]=="張愛")(sale["訂單金額"]>5000)]
7. 模糊篩選數據
需求:篩選存貨名稱含有"三星"或則含有"索尼"的信息。
sale.loc[sale["存貨名稱"].str.contains("三星|索尼")]
8. 分類匯總
需求: 北京區域各業務員的利潤總額。
sale.groupby(["地區名稱","業務員名稱"])["利潤"].sum()
9. 條件計算
需求:存貨名稱含“三星字眼”并且稅費高于1000的訂單有幾個?這些訂單的利潤總和和平均利潤是多少?(或者最小值,最大值,四分位數,標注差)
sale.loc[sale["存貨名稱"].str.contains("三星")(sale["稅費"]>=1000)][["訂單明細號","利潤"]].describe()
10. 刪除數據間的空格
需求:刪除存貨名稱兩邊的空格。
sale["存貨名稱"].map(lambda s :s.strip(""))
四、畫圖分析
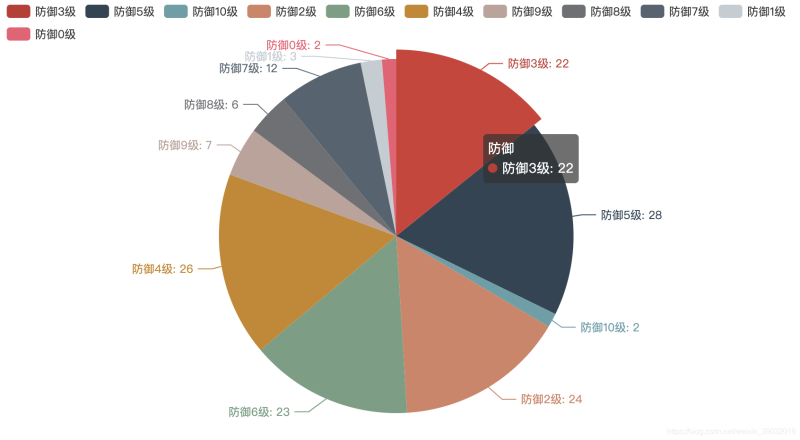
英雄聯盟防御力:
防御能力最低的英雄(1級): 暗夜獵手,魔法貓咪,萬花通靈
防御能力最高的英雄(10級): 正義巨像,披甲龍龜
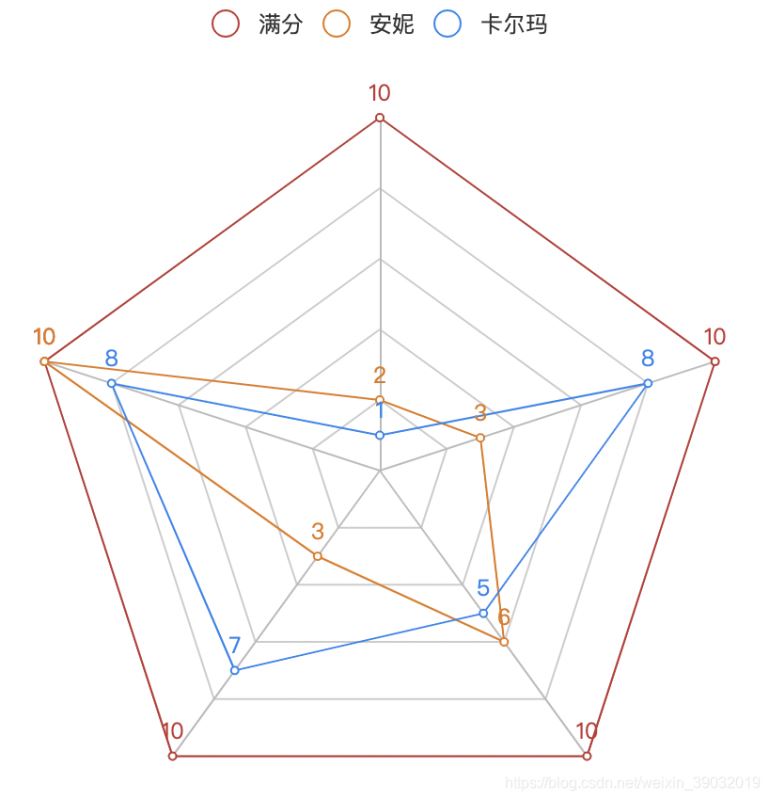
安妮、卡爾瑪能力矩陣:
代碼示例:
# encoding: utf-8
import json
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.charts import Radar
def draw_Radar():
from pyecharts.charts import Radar
radar = Radar()
# //由于雷達圖傳入的數據得為多維數據,所以這里需要做一下處理
radar_data = [[10, 10, 10, 10, 10]]
radar_data1 = [[2, 10, 3, 6, 3]]
radar_data2 = [[1, 8, 7, 5, 8]]
# //設置column的最大值,為了雷達圖更為直觀,這里的月份最大值設置有所不同
schema = [
("物理", 100), ("魔法", 10), ("防御", 10),("難度", 10),("喜好", 10)
]
# //傳入坐標
radar.add_schema(schema)
radar.add("滿分", radar_data)
# //一般默認為同一種顏色,這里為了便于區分,需要設置item的顏色
radar.add("安妮", radar_data1, color="#E37911")
radar.add("卡爾瑪", radar_data2, color="#1C86EE")
radar.render()
if __name__ == '__main__':
draw_Radar()
五、解析word(docx、doc)
依賴包:
# encoding: utf-8
import os, sys
import docx
def word_reader(file):
try:
# docx 直接讀
if 'docx' in file:
res = ''
f = docx.Document(file)
for para in f.paragraphs:
res = res + '\n' +para.text
else:
# 先轉格式doc>docx
os.system("textutil -convert docx '%s'"%file)
word_reader(file+'x')
res = ''
f = docx.Document(file+'x')
for para in f.paragraphs:
res = res + '\n' +para.text
return res
except:
# print(file, 'read failed')
return ''
六、計算器
math模塊為浮點運算提供了對底層函數庫的訪問:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
總結
本篇文章就到這里了,希望能給你帶來幫助,也希望您能夠多多關注腳本之家的更多內容!
您可能感興趣的文章:- python對驗證碼降噪的實現示例代碼
- 爬蟲Python驗證碼識別入門
- Python機器學習入門(一)序章
- Python機器學習入門(三)之Python數據準備
- 用python寫個顏值評分器篩選最美主播
- Python反射機制實例講解
- Python代碼實現粒子群算法圖文詳解
- 我用Python做個AI出牌器斗地主把把贏
- python通過PyQt5實現登錄界面的示例代碼
- Python圖片驗證碼降噪和8鄰域降噪
