目錄
- 1.數據導入
- 1.1使用標準Python類庫導入數據
- 1.2使用Numpy導入數據
- 1.3使用Pandas導入數據
- 2.數據理解
- 2.1數據基本屬性
- 2.1.1查看前10行數據
- 2.1.2查看數據維度,數據屬性和類型:
- 2.1.3查看數據描述性統計
- 2.2數據相關性和分布分析
- 3.數據可視化
- 總結
統計學是什么?概率與數學。用概率與數學來分析人,分析的永遠不是人。用永遠不是人的結論指導人實在是一種偏誤。在這個意義上講,解讀強于技術。
——劉德寰
1.數據導入
在訓練機器學習的模型時,需要大量的數據,最常用的方法是利用歷史數據來訓練模型。這些歷史數據通常是以csv文件儲存,或者能夠方便地轉化為csv文件。在開始機器學習時,我們首先要導入csv數據文件。
csv文件是用逗號(,)分隔的文本文件。在csv文件中注釋是以(#)開頭。
在接下來的文章中,將使用Pima Indians數據集,它是從UCI機器學習倉庫(https://archive.ics.uci.edu/ml/index.php)中獲取的。也可到網盤中下載(https://pan.baidu.com/s/1nv2xuVpXWHC1HUdS1c5QaQ)提取碼:d4im。
Pima Indians是一個分類問題的數據集,主要記錄了印第安人最近五年內是否患有糖尿病的醫療數據。
1.1使用標準Python類庫導入數據
Python提供了一個標準的類庫CSV,用來處理CSV文件。
from csv import reader
#python標準庫導入數據
filename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:
readers = reader(raw_data, delimiter=",")
x = list(readers)
data = np.array(x).astype('float')
print(data.shape)
代碼比較簡單,此處不做過多贅述。
運行結果:
(768, 9)
1.2使用Numpy導入數據
使用numpy的loadtxt()方法導入數據。使用這個函數處理的數據沒有文件頭,并且所有的數據結構都一樣,也就是說,數據類型都一樣。
import numpy as np
#使用Numpy導入數據
from numpy import loadtxt
filename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:
data = loadtxt(raw_data, delimiter=',')
print(data.shape)
loadtxt中的第一個參數為數據實例,第二個參數為分隔符。
輸出結果同上
(768, 9)
1.3使用Pandas導入數據
通過Pandas來導入CSV文件要使用pandas.read_csv()函數。這個函數的返回值使Data Frame。在機器學習的項目中,經常利用pandas來做數據處理和準備工作。因此,推薦使用Pandas來導入數據。
#推薦使用!!!!
#使用Pandas導入數據
from pandas import read_csv
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
#設置文件頭
data = read_csv(filename, names=names)
print(data.shape)
print(data.head(10))
使用Pandas導入數據可以設置文件頭,便于后續數據理解。read_csv()方法有兩個參數,一個是文件名,一個是文件頭數組。
輸出結果同上
(768, 9)
2.數據理解
為了得到更準確的結果,必須理解數據的特征、分布情況,以及需要解決的問題,一邊建立相關的算法模型并進行優化。
2.1數據基本屬性
對數據的簡單審視,是加強對數據理解最有效的方法之一。通過對數據的觀察,可以發現數據的內在關系。這些發現有助于對數據進行整理。
2.1.1查看前10行數據
使用的數據集依然是Pima Indians數據集:
from pandas import read_csv
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass', 'pedi','age','class']
data = read_csv(filename,names=names)
#查看前十行數據
print(data.head(10))
先使用pandas導入數據集,再使用print函數數據data的head屬性以查看前10行數據。
輸出結果:
preg plas pres skin test mass pedi age class
0 6 148 72 35 0 33.6 0.63 50 1
1 1 85 66 29 0 26.6 0.35 31 0
2 8 183 64 0 0 23.3 0.67 32 1
3 1 89 66 23 94 28.1 0.17 21 0
4 0 137 40 35 168 43.1 2.29 33 1
5 5 116 74 0 0 25.6 0.20 30 0
6 3 78 50 32 88 31.0 0.25 26 1
7 10 115 0 0 0 35.3 0.13 29 0
8 2 197 70 45 543 30.5 0.16 53 1
9 8 125 96 0 0 0.0 0.23 54 1
2.1.2查看數據維度,數據屬性和類型:
'''
數據維度
'''
#查看數據維度
#通過DATa Frame的shape屬性來查看數據集中有多少行多少列
print(data.shape)
'''
數據屬性和類型
'''
#查看數據屬性和類型
#通過DATa Frame的Type屬性來查看每一個字段的數據類型
print(data.dtypes)
運行結果:
(768, 9)
preg int64
plas int64
pres int64
skin int64
test int64
mass float64
pedi float64
age int64
class int64
dtype: object
2.1.3查看數據描述性統計
通過DataFrame的describe()方法來查看描述性統計的內容。包括:數據數量、平均值、標準方差、最小值、下四分位數、中位數、上四分位數、最大值。(省略前方讀取數據部分)
from pandas import set_option
'''
描述性統計
'''
#通過DATa frame的describe()方法來查看描述性統計
#數據記錄數、平均住、標準方差、最小值、下四分位數、中位數、上四分位數、最大值
set_option('display.width',100)
#設置數據的精確度
set_option('precision',2)
print("數據描述性分析:")
print(data.describe())
運行結果:
數據描述性分析:
preg plas pres skin test mass pedi age class
count 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00
mean 3.85 120.89 69.11 20.54 79.80 31.99 0.47 33.24 0.35
std 3.37 31.97 19.36 15.95 115.24 7.88 0.33 11.76 0.48
min 0.00 0.00 0.00 0.00 0.00 0.00 0.08 21.00 0.00
25% 1.00 99.00 62.00 0.00 0.00 27.30 0.24 24.00 0.00
50% 3.00 117.00 72.00 23.00 30.50 32.00 0.37 29.00 0.00
75% 6.00 140.25 80.00 32.00 127.25 36.60 0.63 41.00 1.00
max 17.00 199.00 122.00 99.00 846.00 67.10 2.42 81.00 1.00
2.2數據相關性和分布分析
2.2.1數據相關矩陣
數據屬性的相關性是指數據的兩個屬性是否相互影響,以及這種影響是何種方式。常用皮爾遜相關系數來表示兩個屬性之間的關聯性,它介于(-1,1)。當數據的關聯性比較高時,有些算法(如Liner、邏輯回歸算法等)的性能會降低。所以需要查看一下算法的關聯性。使用Data Frame的corr()方法來計算數據屬性之間的相關矩陣。
print("數據屬性的相關性:")
print(data.corr(method='pearson'))
結果如下:
數據屬性的相關性:
preg plas pres skin test mass pedi age class
preg 1.00 0.13 0.14 -0.08 -0.07 0.02 -0.03 0.54 0.22
plas 0.13 1.00 0.15 0.06 0.33 0.22 0.14 0.26 0.47
pres 0.14 0.15 1.00 0.21 0.09 0.28 0.04 0.24 0.07
skin -0.08 0.06 0.21 1.00 0.44 0.39 0.18 -0.11 0.07
test -0.07 0.33 0.09 0.44 1.00 0.20 0.19 -0.04 0.13
mass 0.02 0.22 0.28 0.39 0.20 1.00 0.14 0.04 0.29
pedi -0.03 0.14 0.04 0.18 0.19 0.14 1.00 0.03 0.17
age 0.54 0.26 0.24 -0.11 -0.04 0.04 0.03 1.00 0.24
class 0.22 0.47 0.07 0.07 0.13 0.29 0.17 0.24 1.00
2.2.2數據分布分析
通過分析數據的高斯分布情況來確認數據的偏離情況。使用Data Frame的skew()方法來計算所有數據屬性的高斯分布偏離情況。
print("數據的高斯分布偏離情況:")
print(data.skew())
結果如下:
數據的高斯分布偏離情況:
preg 0.90
plas 0.17
pres -1.84
skin 0.11
test 2.27
mass -0.43
pedi 1.92
age 1.13
class 0.64
dtype: float64
3.數據可視化
對數據進行理解最快、最有效的方式是通過數據的可視化。我們將使用Matplotlib來可視化數據以更好地理解數據。
3.1單一圖表
3.1.1直方圖
直方圖使用較多,此處不做過多介紹。
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass', 'pedi','age','class']
data = read_csv(filename,names=names)
'''
直方圖
'''
data.hist()
plt.show()

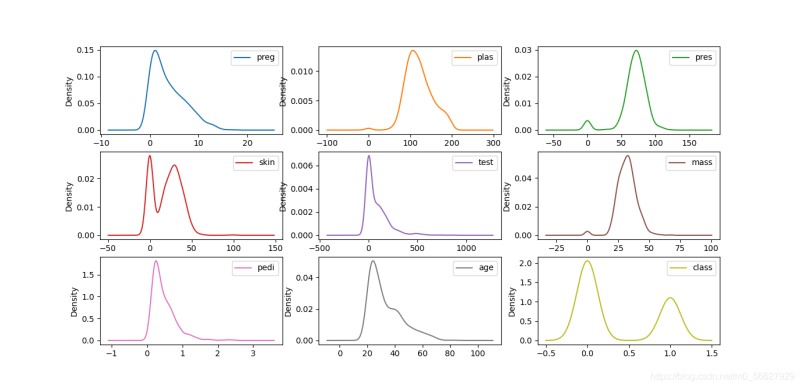
3.1.2密度圖
密度圖是一種表現與數據值對應的邊界或域對象的圖形表示方法,一般用于呈現連續變量。密度圖類似于對直方圖進行抽象,用平滑的線來描述數據的分布。
'''
密度圖
'''
data.plot(kind='density',subplots=True,layout=(3,3),sharex=False,sharey=False)
plt.show()
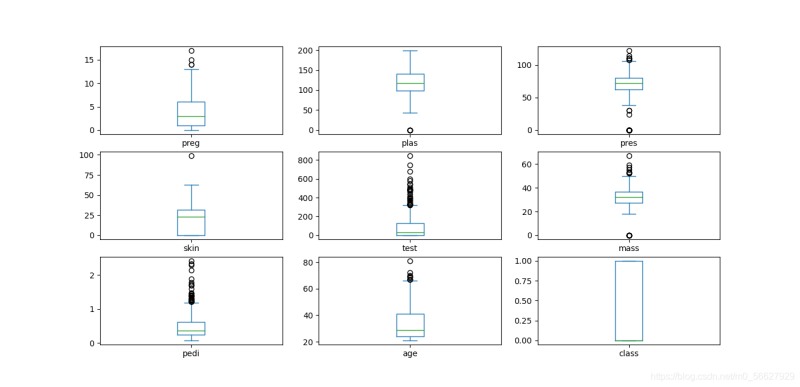
3.1.3箱線圖
箱線圖又稱盒須圖、盒式圖或箱行圖,是一種用于顯示一組數據分散情況的統計圖。
'''
箱線圖
'''
data.plot(kind='box',subplots=True,layout=(3,3),sharex=False,sharey=False)
plt.show()
3.2多重圖表
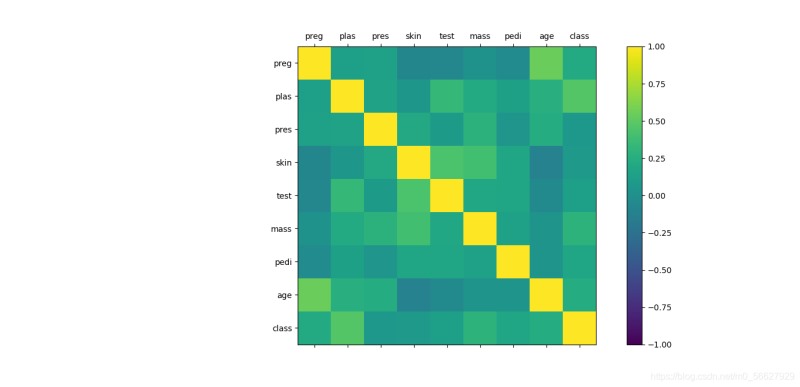
3.2.1相關矩陣圖
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
data = read_csv(filename,names=names)
#相關矩陣圖
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = np.arange(0,9,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
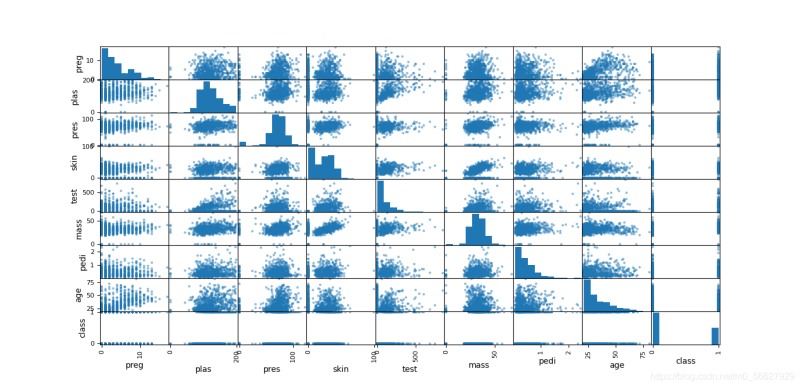
3.2.2散點矩陣圖
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
from pandas.plotting import scatter_matrix
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
data = read_csv(filename,names=names)
scatter_matrix(data)
plt.show()
總結
本文主要講了機器學習項目開始前的一些準備工作:導入數據,數據理解和數據可視化。導入數據有三種方法:Python庫函數,Numpy和Pandas導入,推薦使用Panads導入CSV文件。數據理解包括查看數據的一些基本屬性以及查看數據相關矩陣和高斯分布情況。數據可視化主要介紹了Matplotlib的一些常用方法。
到此這篇關于Python機器學習(二)數據理解的文章就介紹到這了,更多相關Python機器學習(二)內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 詳解python數據結構之隊列Queue
- 詳解python數據結構之棧stack
- python數據類型相關知識擴展
- Python數據類型最全知識總結
- python數據處理——對pandas進行數據變頻或插值實例
- python入門課程第四講之內置數據類型有哪些
