我們在編寫Python爬蟲時,有時會遇到網站拒絕訪問等反爬手段,比如這么我們想爬取螞蟻短租數據,它則會提示“當前訪問疑似黑客攻擊,已被網站管理員設置為攔截”提示,如下圖所示。此時我們需要采用設置Cookie來進行爬取,下面我們進行詳細介紹。非常感謝我的學生承峰提供的思想,后浪推前浪啊!
一. 網站分析與爬蟲攔截
當我們打開螞蟻短租搜索貴陽市,反饋如下圖所示結果。
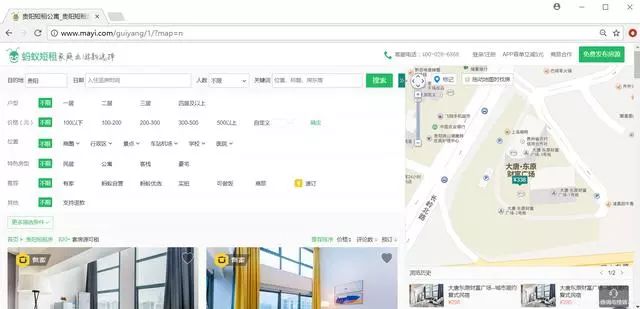
我們可以看到短租房信息呈現一定規律分布,如下圖所示,這也是我們要爬取的信息。
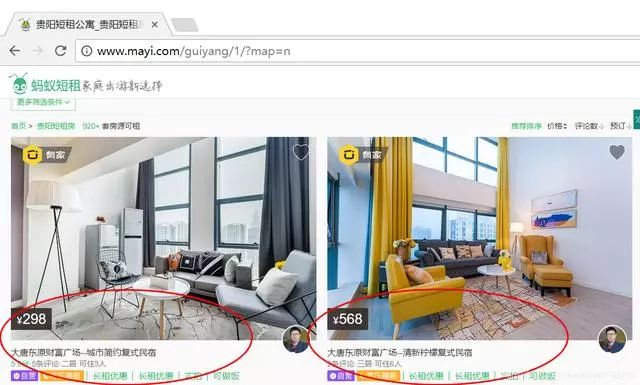
通過瀏覽器審查元素,我們可以看到需要爬取每條租房信息都位于dd>/dd>節點下。

很多人學習python,不知道從何學起。
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手。
很多已經做案例的人,卻不知道如何去學習更加高深的知識。
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!
QQ群:810735403
在定位房屋名稱,如下圖所示,位于div class="room-detail clearfloat">/div>節點下。

接下來我們寫個簡單的BeautifulSoup進行爬取。
# -*- coding: utf-8 -*-
import urllib
import re
from bs4 import BeautifulSoup
import codecs
url = 'http://www.mayi.com/guiyang/?map=no'
response=urllib.urlopen(url)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
print soup.title
print soup
#短租房名稱
for tag in soup.find_all('dd'):
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名稱]', fname.replace('\n','').strip()
但很遺憾,報錯了,說明螞蟻金服防范措施還是挺到位的。

二. 設置Cookie的BeautifulSoup爬蟲
添加消息頭的代碼如下所示,這里先給出代碼和結果,再教大家如何獲取Cookie。
# -*- coding: utf-8 -*-
import urllib2
import re
from bs4 import BeautifulSoup
#爬蟲函數
def gydzf(url):
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers={"User-Agent":user_agent}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag in soup.find_all('dd'):
#短租房名稱
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名稱]', fname.replace('\n','').strip()
#短租房價格
for price in tag.find_all(attrs={"class":"moy-b"}):
string = price.find('p').get_text()
fprice = re.sub("[¥]+".decode("utf8"), "".decode("utf8"),string)
fprice = fprice[0:5]
print u'[短租房價格]', fprice.replace('\n','').strip()
#評分及評論人數
for score in name.find('ul'):
fscore = name.find('ul').get_text()
print u'[短租房評分/評論/居住人數]', fscore.replace('\n','').strip()
#網頁鏈接url
url_dzf = tag.find(attrs={"target":"_blank"})
urls = url_dzf.attrs['href']
print u'[網頁鏈接]', urls.replace('\n','').strip()
urlss = 'http://www.mayi.com' + urls + ''
print urlss
#主函數
if __name__ == '__main__':
i = 1
while i10:
print u'頁碼', i
url = 'http://www.mayi.com/guiyang/' + str(i) + '/?map=no'
gydzf(url)
i = i+1
else:
print u"結束"
輸出結果如下圖所示:
頁碼 1
[短租房名稱] 大唐東原財富廣場--城市簡約復式民宿
[短租房價格] 298
[短租房評分/評論/居住人數] 5.0分·5條評論·二居·可住3人
[網頁鏈接] /room/851634765
http://www.mayi.com/room/851634765
[短租房名稱] 大唐東原財富廣場--清新檸檬復式民宿
[短租房價格] 568
[短租房評分/評論/居住人數] 2條評論·三居·可住6人
[網頁鏈接] /room/851634467
http://www.mayi.com/room/851634467
...
頁碼 9
[短租房名稱] 【高鐵北站公園旁】美式風情+超大舒適安逸
[短租房價格] 366
[短租房評分/評論/居住人數] 3條評論·二居·可住5人
[網頁鏈接] /room/851018852
http://www.mayi.com/room/851018852
[短租房名稱] 大營坡(中大國際購物中心附近)北歐小清新三室
[短租房價格] 298
[短租房評分/評論/居住人數] 三居·可住6人
[網頁鏈接] /room/851647045
http://www.mayi.com/room/851647045

接下來我們想獲取詳細信息
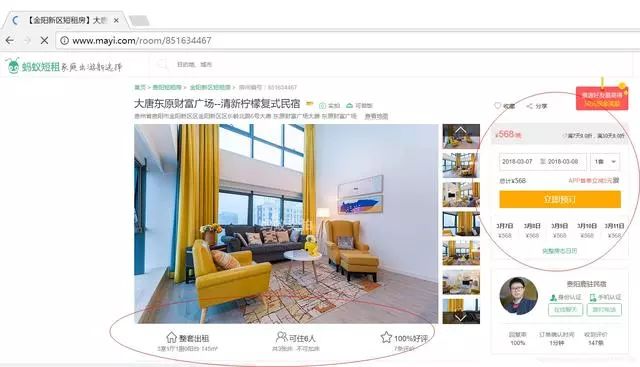
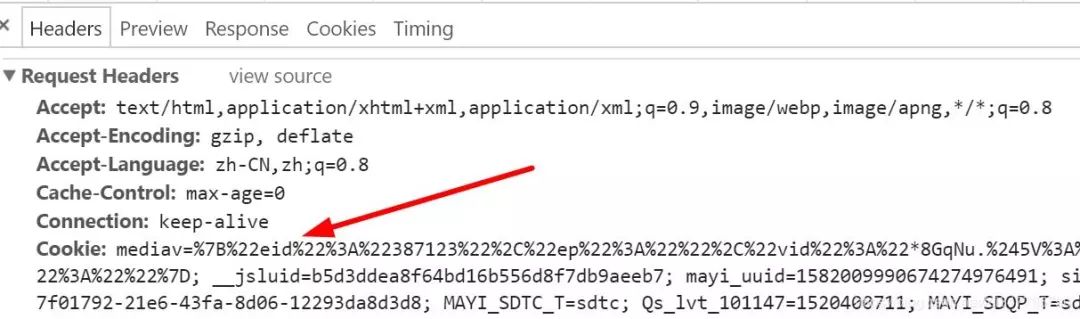
這里作者主要是提供分析Cookie的方法,使用瀏覽器打開網頁,右鍵“檢查”,然后再刷新網頁。在“NetWork”中找到網頁并點擊,在彈出來的Headers中就隱藏這這些信息。
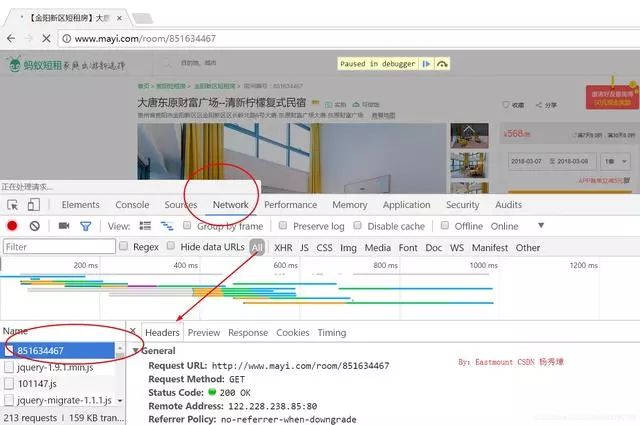
最常見的兩個參數是Cookie和User-Agent,如下圖所示:
然后在Python代碼中設置這些參數,再調用Urllib2.Request()提交請求即可,核心代碼如下:
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ... Chrome/61.0.3163.100 Safari/537.36"
cookie="mediav=%7B%22eid%22%3A%22387123...b3574ef2-21b9-11e8-b39c-1bc4029c43b8"
headers={"User-Agent":user_agent,"Cookie":cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag1 in soup.find_all(attrs={"class":"main"}):
注意,每小時Cookie會更新一次,我們需要手動修改Cookie值即可,就是上面代碼的cookie變量和user_agent變量。完整代碼如下所示:
import urllib2
import re
from bs4 import BeautifulSoup
import codecs
import csv
c = open("ycf.csv","wb") #write 寫
c.write(codecs.BOM_UTF8)
writer = csv.writer(c)
writer.writerow(["短租房名稱","地址","價格","評分","可住人數","人均價格"])
#爬取詳細信息
def getInfo(url,fname,fprice,fscore,users):
#通過瀏覽器開發者模式查看訪問使用的user_agent及cookie設置訪問頭(headers)避免反爬蟲,且每隔一段時間運行要根據開發者中的cookie更改代碼中的cookie
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
cookie="mediav=%7B%22eid%22%3A%22387123%22eb7; mayi_uuid=1582009990674274976491; sid=42200298656434922.85.130.130"
headers={"User-Agent":user_agent,"Cookie":cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
#短租房地址
for tag1 in soup.find_all(attrs={"class":"main"}):
print u'短租房地址:'
for tag2 in tag1.find_all(attrs={"class":"desWord"}):
address = tag2.find('p').get_text()
print address
#可住人數
print u'可住人數:'
for tag4 in tag1.find_all(attrs={"class":"w258"}):
yy = tag4.find('span').get_text()
print yy
fname = fname.encode("utf-8")
address = address.encode("utf-8")
fprice = fprice.encode("utf-8")
fscore = fscore.encode("utf-8")
fpeople = yy[2:3].encode("utf-8")
ones = int(float(fprice))/int(float(fpeople))
#存儲至本地
writer.writerow([fname,address,fprice,fscore,fpeople,ones])
#爬蟲函數
def gydzf(url):
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers={"User-Agent":user_agent}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag in soup.find_all('dd'):
#短租房名稱
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名稱]', fname.replace('\n','').strip()
#短租房價格
for price in tag.find_all(attrs={"class":"moy-b"}):
string = price.find('p').get_text()
fprice = re.sub("[¥]+".decode("utf8"), "".decode("utf8"),string)
fprice = fprice[0:5]
print u'[短租房價格]', fprice.replace('\n','').strip()
#評分及評論人數
for score in name.find('ul'):
fscore = name.find('ul').get_text()
print u'[短租房評分/評論/居住人數]', fscore.replace('\n','').strip()
#網頁鏈接url
url_dzf = tag.find(attrs={"target":"_blank"})
urls = url_dzf.attrs['href']
print u'[網頁鏈接]', urls.replace('\n','').strip()
urlss = 'http://www.mayi.com' + urls + ''
print urlss
getInfo(urlss,fname,fprice,fscore,user_agent)
#主函數
if __name__ == '__main__':
i = 0
while i33:
print u'頁碼', (i+1)
if(i==0):
url = 'http://www.mayi.com/guiyang/?map=no'
if(i>0):
num = i+2 #除了第一頁是空的,第二頁開始按2順序遞增
url = 'http://www.mayi.com/guiyang/' + str(num) + '/?map=no'
gydzf(url)
i=i+1
c.close()
輸出結果如下,存儲本地CSV文件:
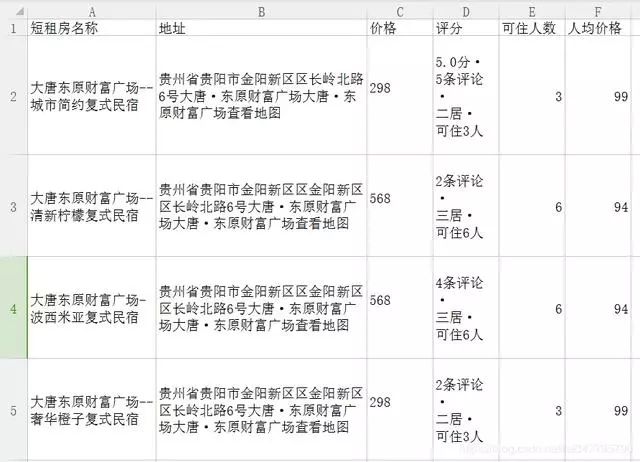
同時,大家可以嘗試Selenium爬取螞蟻短租,應該也是可行的方法。
到此這篇關于Python爬蟲設置Cookie解決網站攔截并爬取螞蟻短租的文章就介紹到這了,更多相關Python爬蟲爬取螞蟻短租內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Django操作cookie的實現
- 利用Selenium添加cookie實現自動登錄的示例代碼(fofa)
- 如何使用會話Cookie和Java實現JWT身份驗證
- Python Selenium操作Cookie的實例方法
- Http Cookie機制及Cookie的實現原理
