網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自動索引、模擬程序或者蠕蟲。
上面關于爬蟲可以做什么,定義了一個前提,是瀏覽器可以訪問到的任何資源,特別是對于知曉web請求生命周期的學者來說,爬蟲的本質就更簡單了。爬蟲的本質就是模擬瀏覽器打開網頁,獲取網頁中我們想要的那部分數據。
# -*- coding=UTF-8 -*-
#!usr/bin/env python
import os
import time
import requests
from lxml import etree
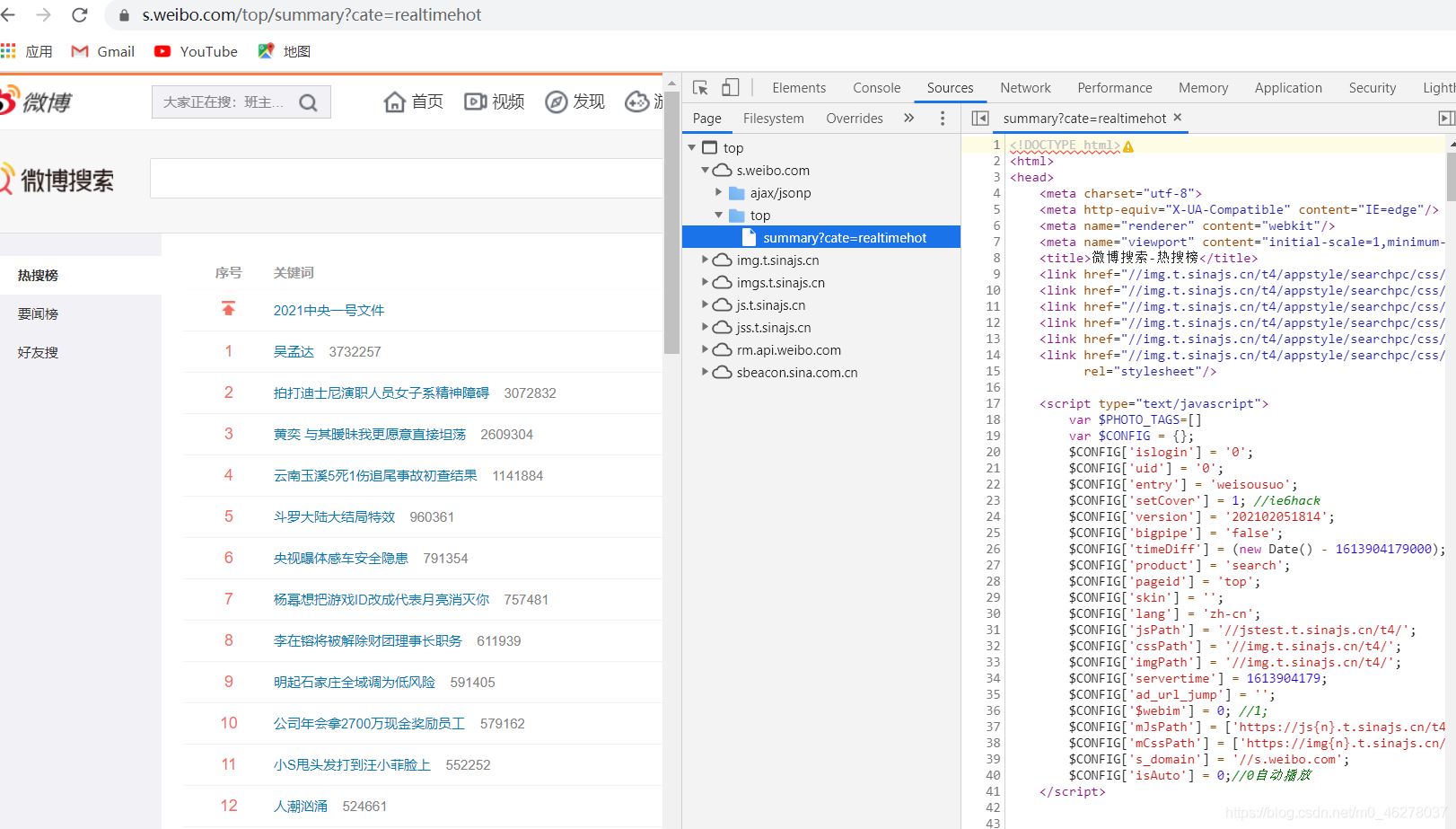
url = "https://s.weibo.com/top/summary?cate=realtimehot"
headers={
'Host': 's.weibo.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
r = requests.get(url,headers=headers)
print(r.status_code)
html_xpath = etree.HTML(r.text)
data = html_xpath.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]')
num = -1
# # 解決存儲路徑
# time_path = time.strftime('%Y{y}%m{m}%d1l717j5',time.localtime()).format(y='年', m='月', d='日')
# time_name = time.strftime('%Y{y}%m{m}%d1h5ljhj%H{h}',time.localtime()).format(y='年', m='月', d='日',h='點')
# root = "./" + time_path + "/"
# path = root + time_name + '.md'
# if not os.path.exists(root):
# os.mkdir(root)
# 解決存儲路徑
time_path = time.strftime('%Y{y}%m{m}%d77j111h',time.localtime()).format(y='年', m='月', d='日')
time_name = time.strftime('%Y{y}%m{m}%dljljjjj%H{h}',time.localtime()).format(y='年', m='月', d='日',h='點')
year_path = time.strftime('%Y{y}',time.localtime()).format(y='年')
month_path = time.strftime('%m{m}',time.localtime()).format(m='月')
day_month = time.strftime('%dljljhlh',time.localtime()).format(d='日')
all_path = "./" + year_path + '/'+ month_path + '/' + day_month
if not os.path.exists(all_path):
# 創建多層路徑
os.makedirs(all_path)
# 最終文件存儲位置
root = all_path + "/"
path = root + time_name + '.md'
print(path)
# 文件頭部信息
with open(path,'a') as f:
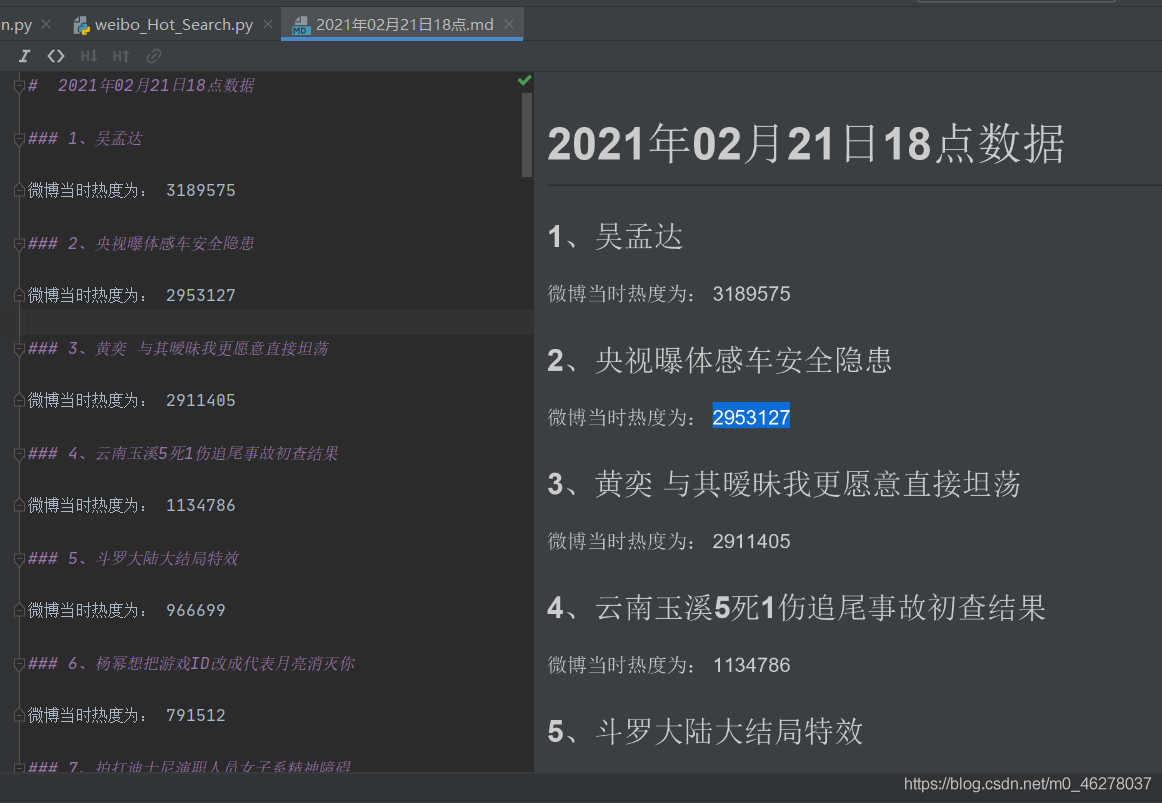
f.write('{} {}\n\n'.format('# ',time_name+'數據'))
f.close()
for tr in (data):
title = tr.xpath('./a/text()')
hot_score = tr.xpath('./span/text()')
num += 1
# 過濾第 0 條
if num == 0:
pass
else:
with open(path,'a') as f:
f.write('{} {}、{}\n\n'.format('###',num,title[0]))
f.write('{} {}\n\n'.format('微博當時熱度為:',hot_score[0]))
f.close()
print(num,title[0],'微博此時的熱度為:',hot_score[0])
到此這篇關于Python爬蟲爬取微博熱搜保存為 Markdown 文件的文章就介紹到這了,更多相關Python爬蟲爬取微博熱搜保存內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!