目錄
- 一��、前言
- 二、同步代碼演示
- 三�����、異步�,線程池代碼
- 四、同步爬蟲爬取圖片
- 五�����、使用線程池的異步爬蟲爬取4K美女圖片
一��、前言
學到現在,我們可以說已經學習了爬蟲的基礎知識��,如果沒有那些奇奇怪怪的反爬蟲機制��,基本上只要有時間分析�����,一般的數據都是可以爬取的,那么到了這個時候我們需要考慮的就是爬取的效率了,關于提高爬蟲效率���,也就是實現異步爬蟲,我們可以考慮以下兩種方式:一是線程池的使用(也就是實現單進程下的多線程),一是協程的使用(如果沒有記錯,我所使用的協程模塊是從python3.4以后引入的,我寫博客時使用的python版本是3.9)。
今天我們先來講講線程池���。
二、同步代碼演示
我們先用普通的同步的形式寫一段代碼
import time
def func(url):
print("正在下載:", url)
time.sleep(2)
print("下載完成:", url)
if __name__ == '__main__':
start = time.time() # 開始時間
url_list = [
"a", "b", "c"
]
for url in url_list:
func(url)
end = time.time() # 結束時間
print(end - start)
對于代碼運行的結果我們心里都有數,但還是讓我們來看一下吧

不出所料��。運行時間果然是六秒
三����、異步,線程池代碼
那么如果我們使用線程池運行上述代碼又會怎樣呢���?
import time
from multiprocessing import Pool
def func(url):
print("正在下載:", url)
time.sleep(2)
print("下載完成:", url)
if __name__ == '__main__':
start = time.time() # 開始時間
url_list = [
"a", "b", "c"
]
pool = Pool(len(url_list)) # 實例化一個線程池對象,并且設定線程池的上限數量為列表長度��。不設置上限也可以�����。
pool.map(func, url_list)
end = time.time() # 結束時間
print(end - start)
下面就是見證奇跡的時候了����,讓我們運行程序

我們發現這次我們的運行時間只用2~3秒��。其實我們可以將線程池簡單的理解為將多個任務同時進行。
注意:
1.我使用的是 pycharm����,如果使用的是 VS 或者說是 python 自帶的 idle����,在運行時我們只能看到最后時間的輸出。
2.我們輸出結果可能并不是按 abc 的順序輸出的。
四�����、同步爬蟲爬取圖片
因為我們的重點是線程池的爬取效率提高���,我們就簡單的爬取一頁的圖片�����。
import requests
import time
import os
from lxml import etree
def save_photo(url, title):
# UA偽裝
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 發送請求
photo = requests.get(url=url, headers=header).content
# 創建路徑�,避免重復下載
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\同步爬蟲爬取4K美女圖片\\" + title + ".jpg"):
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\同步爬蟲爬取4K美女圖片\\" + title + ".jpg", "wb") as fp:
print(title, "開始下載?���。?��!")
fp.write(photo)
print(title, "下載完成!!�����!")
if __name__ == '__main__':
start = time.time()
# 創建文件夾
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\同步爬蟲爬取4K美女圖片"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\同步爬蟲爬取4K美女圖片")
# UA偽裝
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 指定url
url = "https://pic.netbian.com/4kmeinv/"
# 發送請求�����,獲取源碼
page = requests.get(url = url, headers = header).text
# xpath 解析,獲取圖片的下載地址的列表
tree = etree.HTML(page)
url_list = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href')
# 通過下載地址獲取高清圖片的地址和圖片名稱
for href in url_list:
new_url = "https://pic.netbian.com" + href
# 再一次發送請求
page = requests.get(url = new_url, headers = header).text
# 再一次 xpath 解析
new_tree = etree.HTML(page)
src = "https://pic.netbian.com" + new_tree.xpath('//*[@id="img"]/img/@src')[0]
title = new_tree.xpath('//*[@id="img"]/img/@title')[0].split(" ")[0]
# 編譯文字
title = title.encode("iso-8859-1").decode("gbk")
# 下載����,保存
save_photo(src, title)
end = time.time()
print(end - start)
讓我們看看同步爬蟲需要多長時間
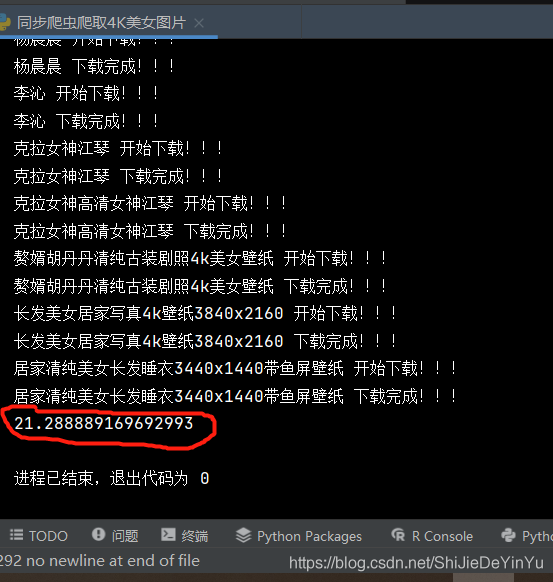
然后再讓我們看看使用線程池的異步爬蟲爬取這些圖片需要多久
五�、使用線程池的異步爬蟲爬取4K美女圖片
import requests
import time
import os
from lxml import etree
from multiprocessing import Pool
def save_photo(src_title):
# UA偽裝
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 發送請求
url = src_title[0]
title = src_title[1]
photo = requests.get(url=url, headers=header).content
# 創建路徑��,避免重復下載
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\異步爬蟲爬取4K美女圖片\\" + title + ".jpg"):
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\異步爬蟲爬取4K美女圖片\\" + title + ".jpg", "wb") as fp:
print(title, "開始下載?�。?�!")
fp.write(photo)
print(title, "下載完成?。?!")
if __name__ == '__main__':
start = time.time()
# 創建文件夾
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\異步爬蟲爬取4K美女圖片"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能異步爬蟲\\線程池\\異步爬蟲爬取4K美女圖片")
# UA偽裝
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 指定url
url = "https://pic.netbian.com/4kmeinv/"
# 發送請求���,獲取源碼
page = requests.get(url = url, headers = header).text
# xpath 解析�����,獲取圖片的下載地址的列表
tree = etree.HTML(page)
url_list = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href')
# 存儲最后的網址和標題的列表
src_list = []
title_list = []
# 通過下載地址獲取高清圖片的地址和圖片名稱
for href in url_list:
new_url = "https://pic.netbian.com" + href
# 再一次發送請求
page = requests.get(url = new_url, headers = header).text
# 再一次 xpath 解析
new_tree = etree.HTML(page)
src = "https://pic.netbian.com" + new_tree.xpath('//*[@id="img"]/img/@src')[0]
src_list.append(src)
title = new_tree.xpath('//*[@id="img"]/img/@title')[0].split(" ")[0]
# 編譯文字
title = title.encode("iso-8859-1").decode("gbk")
title_list.append(title)
# 下載,保存��。使用線程池
pool = Pool()
src_title = zip(src_list, title_list)
pool.map(save_photo, list(src_title))
end = time.time()
print(end - start)
讓我們來看看運行的結果
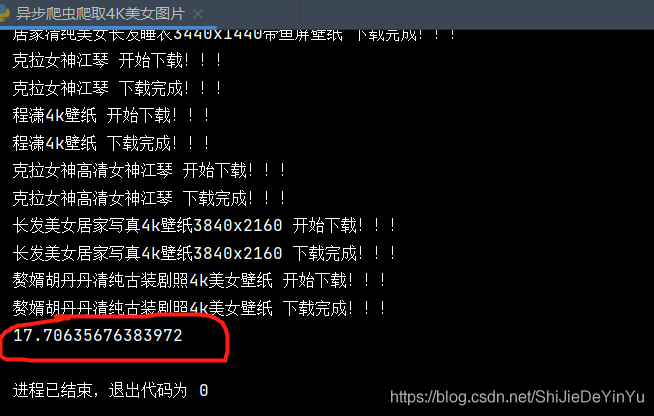
只用了 17 秒����,可不要小瞧這幾秒,如果數據太大���,這些差距后來就會更大了。
注意
不過我們必須要明白 線程池 是有上限的���,這就是說數據太大,線程池的效率也會降低���,所以這就要用到協程模塊了����。
到此這篇關于Python爬蟲之線程池的使用的文章就介紹到這了,更多相關Python線程池的使用內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python 線程池模塊之多線程操作代碼
- python線程池的四種好處總結
- python爬蟲線程池案例詳解(梨視頻短視頻爬取)
- python線程池 ThreadPoolExecutor 的用法示例
- 實例代碼講解Python 線程池
- Python 如何創建一個線程池
- python線程池如何使用
- 解決python ThreadPoolExecutor 線程池中的異常捕獲問題
- Python定時器線程池原理詳解
- Python 使用threading+Queue實現線程池示例
- Python線程池的正確使用方法
