python2中的unicode()函數在python3中會報錯:
NameError: name 'unicode' is not defined
There is no such name in Python 3, no. You are trying to run Python 2 code in Python 3. In Python 3, unicode has been renamed to str.
翻譯過來就是:Python 3中沒有這樣的名字,沒有。 您正在嘗試在Python 3中運行Python 2代碼。在Python 3中,unicode已重命名為str。
函數轉換:unicode()到 str()為:
//python2:
unicode(nn,'utf-8')
//python3:
str(nn)
補充:根本解決Python2中unicode編碼問題
Python2中編碼問題
因為計算機只識別01這要的二進制,所以在計算機存儲我們的文件時,要使用二進制數來表示。所以編碼就是哪個二進制數表示哪個字符:
編碼原由系統編碼、文件編碼與python系統編碼Python字符編碼python中的字典、數組轉字符串中的中文編碼
編碼原由
ASCII編碼
最早出現的是ASCII碼,使用8位二進制數組合表示128種字符。因為ASCII編碼是美國人發明的,當初沒考慮給別的國家用,所以,它僅僅表示了所有美式英語的語言字符。但是沒有使用完。
ISO 8859-1/windows-1252
128位字符滿足了美國人的需求,但是隨之歐洲人加入互聯網,為了滿足歐洲人的需求,8位二進制后面還有128位。這一段編碼我們稱之擴展字符集,即ISO 8859-1編碼標準,后來歐洲的需求變更,即規定了windows-1252代替了ISO 8859-1
GB2312
然后當我國加入后,8位二進制(即一個字節)用完了,于是我們保留ASCII編碼即前128位,后面的全部刪除。因為我國得語言博大精深,所以需要2個字節,即16位才能滿足我們得需求,所以當計算機遇到大于127的字節時,就一次性讀取兩個字節,將他解碼成漢字。即GB2312編碼
GBK
相當于GB2312的改進版,增添了中文字符。但還是2個字節表示漢字
GB18030
為了滿足日韓和我國的少數民族的需求,對GBK的改進,使用變長編碼,要么使用兩個字節,要么使用四個字節。
Unicode
雖然每種編碼都兼容ASCII編碼,但是各個國家是不兼容的。于是出現了Unicode,它將所有的編碼進行了統一。它不能算是一種具體的編碼標準,只是將全世界的字符進行了編號,并沒有指定他們具體在計算機種以什么樣的形式存儲。
它的具體實現有UTF-8,UTF-16,UTF-32等。
系統編碼、文件編碼與python系統編碼
在linux中獲取系統編碼結果:
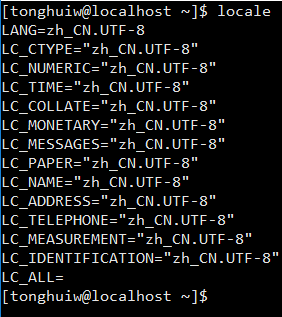
Windows系統的編碼,代碼頁936表示GBK編碼

可以看到linux系統默認使用UTF-8編碼,windows默認使用GBK編碼。Linux環境下,文件默認使用UTF-8編碼。當然你也可以指定文件編碼方式。
Python解釋器內部默認使用的ASCII編碼方式去解讀python源文件。
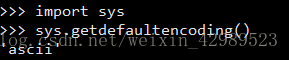
所以當文件內存在非ASCII字符時,python解釋器無 法識別,就會出現編碼錯誤。

So,這個時候需要告訴python解釋器用utf-8去解讀python源文件
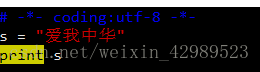

Python字符編碼
Python2中有兩類字符串,分別是str與unicode。這兩類字符串都派生自抽象類basestring。 Str即普通字符串類型
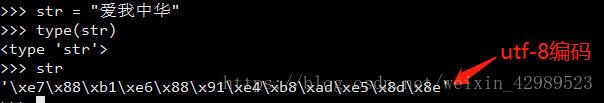
在字符串前加上u即unicode編碼

在代碼中通常用到的是unicode,文件保存的是utf-8編碼。Unicode編碼是固定2個字節代表一個字符。Utf-8是對英文只用一個字節,對中文是3個字節。所以unicode運行效率高,utf-8運行效率相比要低,但是空間存儲要小。
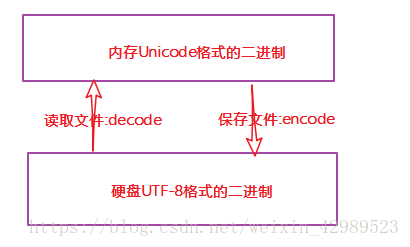
Python中str與unicode轉換
Unicode轉str

str轉unicode

其函數中參數UTF-8是,以utf-8編碼對unicode對象解碼,或編碼。
python中的字典、數組轉字符串中的中文編碼
當字典中的中文字符是unicode類型時
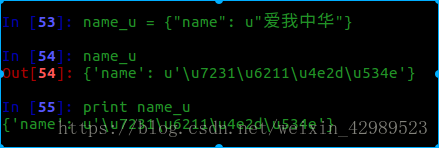
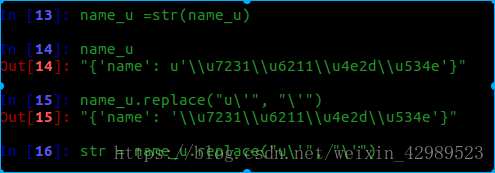

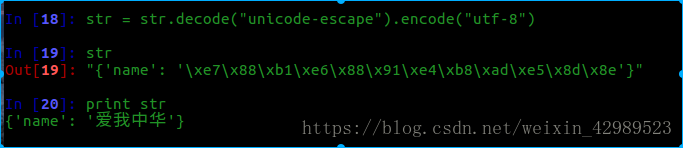
decode(“unicode-escape”)相當是反向編碼.然后再進行utf-8編碼即可
當字典中的字符串是string類型時
name = {"name": "中國"}
name = str(name)
print name.decode("string-escape")

當數組進行字符串化時

最后總結
不管是數組還是字典,在進行字符串轉換是,即是又一次編碼,所以,對于本身還有的中文字符串又一次編碼,所以要進行一次反編碼,才能看到原有的編碼。
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- python中的內置函數max()和min()及mas()函數的高級用法
- python print()函數的end參數和sep參數的用法說明
- python處理emoji表情(兩個函數解決兩者之間的聯系)
- python繪圖subplots函數使用模板的示例代碼
- python-opencv中的cv2.inRange函數用法說明
- Python input()函數用法大全
- python Pool常用函數用法總結
- python 如何用map()函數創建多線程任務
- Python函數參數中的*與**運算符
- 詳解python函數傳參傳遞dict/list/set等類型的問題
- Python3去除頭尾指定字符的函數strip()、lstrip()、rstrip()用法詳解
- Python進階之高級用法詳細總結
