在python中,用pandas處理數據非常方便。
但是有時候從其他地方讀取數據時,會有異常值需要處理。
比如,我們要從excel讀取數據然后調用接口寫入數據庫時,讀取到的空值是NaN,但是,接口接收的對應單元格數據應該是None,這時候怎么處理呢?當然,用pandas做這個事也是非常容易的。
示例如下:
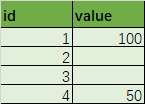
原始數據:
示例代碼:
import pandas as pd
df = pd.read_excel('data/test_data.xlsx')
# 將非空數據保留,空數據用None替換
df = df.where(df.notnull(), None)
print(df)
輸出結果:
id value
0 1 100
1 2 None
2 3 None
3 4 50
補充:Pandas Nan None 處理
在處理數據的時候遇到這個問題。
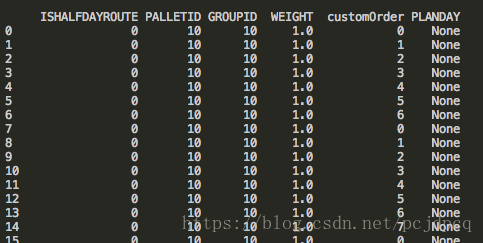
數據庫里的值 是null
然后讀取數據庫后得到的dataframe 里顯示的事None.
想把這些None 裝換成0.0 但是試過很多方法都不奏效。
使用過
df['PLANDAY'].replace('None',0)
未奏效
這個判斷句是生效的
df.loc[0,'PLANDAY'] is None:
后來發現這個數據類型是Nan 不是None
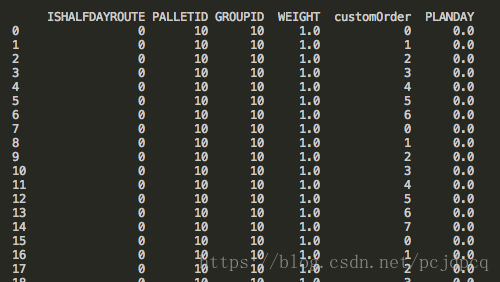
因此使用解決了上訴問題。
df['PLANDAY'] = df['PLANDAY'].fillna(0.0)
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- 在Pandas中處理NaN值的方法
- pandas 缺失值與空值處理的實現方法
- Python Pandas對缺失值的處理方法
