開發環境說明:
Python 35
Pytorch 0.2
CPU/GPU均可
1、LSTM簡介
人類在進行學習時,往往不總是零開始,學習物理你會有數學基礎、學習英語你會有中文基礎等等。
于是對于機器而言,神經網絡的學習亦可不再從零開始,于是出現了Transfer Learning,就是把一個領域已訓練好的網絡用于初始化另一個領域的任務,例如會下棋的神經網絡可以用于打德州撲克。
我們這講的是另一種不從零開始學習的神經網絡——循環神經網絡(Recurrent Neural Network, RNN),它的每一次迭代都是基于上一次的學習結果,不斷循環以得到對于整體序列的學習,區別于傳統的MLP神經網絡,這種神經網絡模型存在環型結構,
具體下所示:
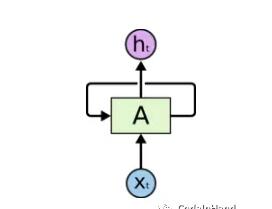
上圖是RNN的基本單元,通過不斷循環迭代展開模型如下所示,圖中ht是神經網絡的在t時刻的輸出,xt是t時刻的輸入數據。
這種循環結構對時間序列數據能夠很好地建模,例如語音識別、語言建模、機器翻譯等領域。
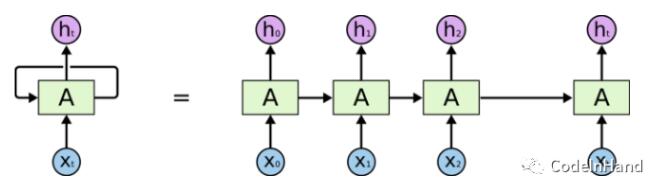
但是普通的RNN對于長期依賴問題效果比較差,當序列本身比較長時,由于神經網絡模型的訓練是采用backward進行,在梯度鏈式法則中容易出現梯度消失和梯度爆炸的問題,需要進一步改進RNN的模型結構。
針對Simple RNN存在的問題,LSTM網絡模型被提出,LSTM的核心是修改了增添了Cell State,即加入了LSTM CELL,通過輸入門、輸出門、遺忘門把上一時刻的hidden state和cell state傳給下一個狀態。
如下所示:
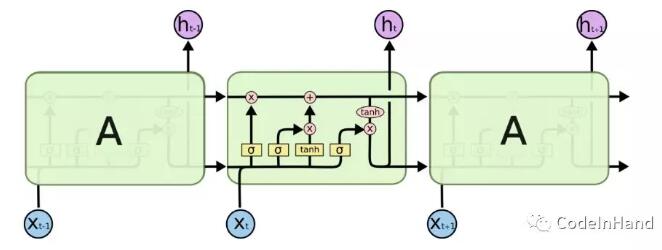
遺忘門:ft = sigma(Wf*[ht-1, xt] + bf)
輸入門:it = sigma(Wi*[ht-1, xt] + bi)
cell state initial: C't = tanh(Wc*[ht-1, xt] +bc)
cell state: Ct = ft*Ct-1+ itC't
輸出門:ot = sigma(Wo*[ht-1, xt] + bo)
模型輸出:ht = ot*tanh(Ct)
LSTM有很多種變型結構,實際工程化過程中用的比較多的是peephole,就是計算每個門的時候增添了cell state的信息,有興趣的童鞋可以專研專研。
上一部分簡單地介紹了LSTM的模型結構,下邊將具體介紹使用LSTM模型進行時間序列預測的具體過程。
2、數據準備
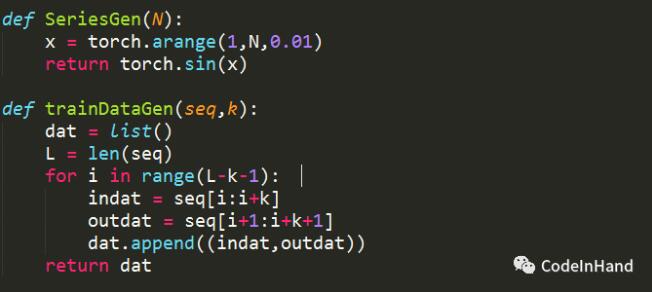
對于時間序列,本文選取正弦波序列,事先產生一定數量的序列數據,然后截取前部分作為訓練數據訓練LSTM模型,后部分作為真實值與模型預測結果進行比較。正弦波的產生過程如下:
SeriesGen(N)方法用于產生長度為N的正弦波數值序列;
trainDataGen(seq,k)用于產生訓練或測試數據,返回數據結構為輸入輸出數據。seq為序列數據,k為LSTM模型循環的長度,使用1~k的數據預測2~k+1的數據。
3、模型構建
Pytorch的nn模塊提供了LSTM方法,具體接口使用說明可以參見Pytorch的接口使用說明書。此處調用nn.LSTM構建LSTM神經網絡,模型另增加了線性變化的全連接層Linear(),但并未加入激活函數。由于是單個數值的預測,這里input_size和output_size都為1.
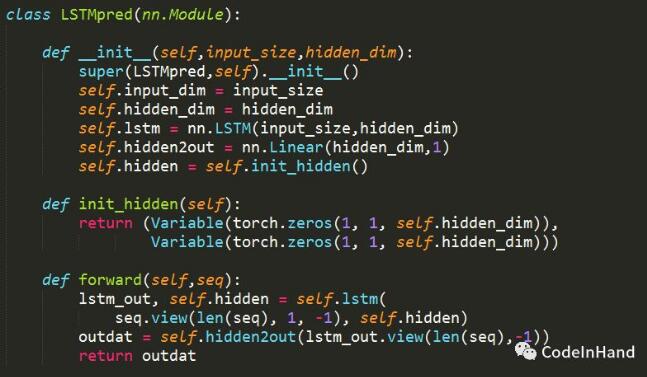
4、訓練和測試
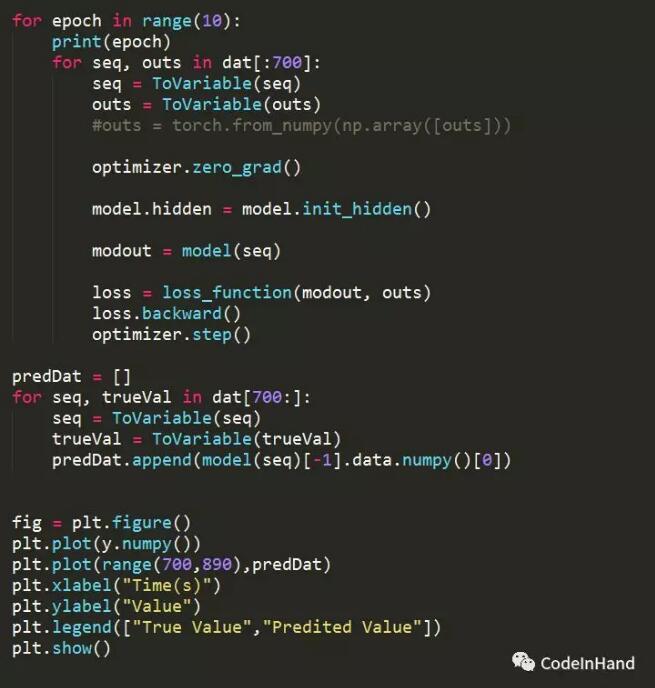
(1)模型定義、損失函數定義

(2)訓練與測試
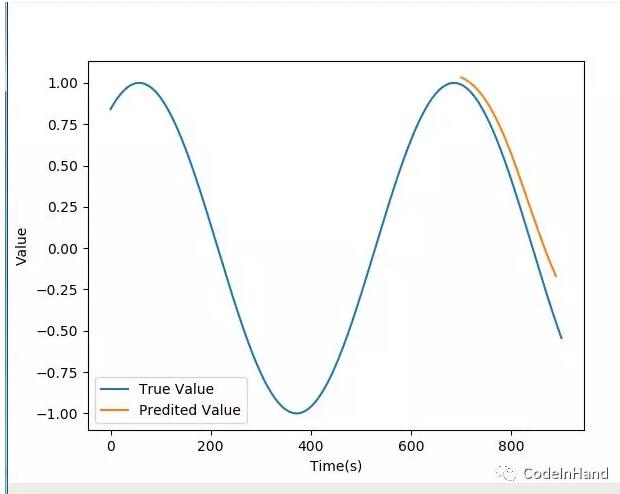
(3)結果展示
比較模型預測序列結果與真實值之間的差距
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- Pytorch實現LSTM和GRU示例
- pytorch下使用LSTM神經網絡寫詩實例
- TensorFlow實現RNN循環神經網絡
- pytorch lstm gru rnn 得到每個state輸出的操作
