主要就是了解一下pytorch中的使用layernorm這種歸一化之后的數據變化,以及數據使用relu,prelu,leakyrelu之后的變化。
import torch
import torch.nn as nn
import torch.nn.functional as F
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
self.LN=nn.LayerNorm(10,eps=0,elementwise_affine=True)
self.PRelu=nn.PReLU(init=0.25)
self.Relu=nn.ReLU()
self.LeakyReLU=nn.LeakyReLU(negative_slope=0.01,inplace=False)
def forward(self,input ):
out=self.LN(input)
print("LN:",out)
out1=self.PRelu(out)
print("PRelu:",out1)
out2=self.Relu(out)
print("Relu:",out2)
out3=self.LeakyReLU(out)
print("LeakyRelu:",out3)
return out
tensor=torch.tensor([-0.9,0.1,0,-0.1,0.9,-0.4,0.9,-0.5,0.8,0.1])
net=model()
print(tensor)
net(tensor)
輸出:
tensor([-0.9000, 0.1000, 0.0000, -0.1000, 0.9000, -0.4000, 0.9000, -0.5000,
0.8000, 0.1000])
LN: tensor([-1.6906, 0.0171, -0.1537, -0.3245, 1.3833, -0.8368, 1.3833, -1.0076,
1.2125, 0.0171], grad_fn=NativeLayerNormBackward>)
Relu: tensor([0.0000, 0.0171, 0.0000, 0.0000, 1.3833, 0.0000, 1.3833, 0.0000, 1.2125,
0.0171], grad_fn=ReluBackward0>)
PRelu: tensor([-0.4227, 0.0171, -0.0384, -0.0811, 1.3833, -0.2092, 1.3833, -0.2519,
1.2125, 0.0171], grad_fn=PreluBackward>)
LeakyRelu: tensor([-0.0169, 0.0171, -0.0015, -0.0032, 1.3833, -0.0084, 1.3833, -0.0101,
1.2125, 0.0171], grad_fn=LeakyReluBackward0>)
從上面可以看出,這個LayerNorm的歸一化,并不是將數據限定在0-1之間,也沒有進行一個類似于高斯分布一樣的分數,只是將其進行了一個處理,對應的數值得到了一些變化,相同數值的變化也是相同的。
Relu的則是單純將小于0的數變成了0,減少了梯度消失的可能性
PRelu是一定程度上的保留了負值,根據init給的值。
LeakyRelu也是一定程度上保留負值,不過比較小,應該是根據negative_slope給的值。
補充:PyTorch學習之歸一化層(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)
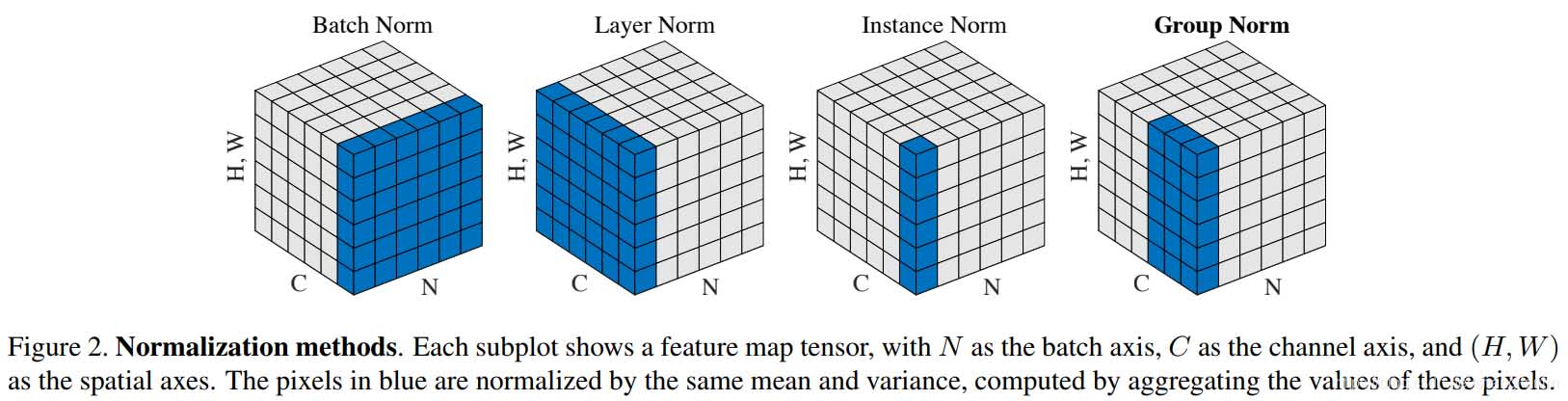
BN,LN,IN,GN從學術化上解釋差異:
BatchNorm:batch方向做歸一化,算NHW的均值,對小batchsize效果不好;BN主要缺點是對batchsize的大小比較敏感,由于每次計算均值和方差是在一個batch上,所以如果batchsize太小,則計算的均值、方差不足以代表整個數據分布
LayerNorm:channel方向做歸一化,算CHW的均值,主要對RNN作用明顯;
InstanceNorm:一個channel內做歸一化,算H*W的均值,用在風格化遷移;因為在圖像風格化中,生成結果主要依賴于某個圖像實例,所以對整個batch歸一化不適合圖像風格化中,因而對HW做歸一化。可以加速模型收斂,并且保持每個圖像實例之間的獨立。
GroupNorm:將channel方向分group,然后每個group內做歸一化,算(C//G)HW的均值;這樣與batchsize無關,不受其約束。
SwitchableNorm是將BN、LN、IN結合,賦予權重,讓網絡自己去學習歸一化層應該使用什么方法。
1 BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
參數:
num_features: 來自期望輸入的特征數,該期望輸入的大小為'batch_size x num_features [x width]'
eps: 為保證數值穩定性(分母不能趨近或取0),給分母加上的值。默認為1e-5。
momentum: 動態均值和動態方差所使用的動量。默認為0.1。
affine: 布爾值,當設為true,給該層添加可學習的仿射變換參數。
track_running_stats:布爾值,當設為true,記錄訓練過程中的均值和方差;
實現公式:
track_running_stats:布爾值,當設為true,記錄訓練過程中的均值和方差;
實現公式:
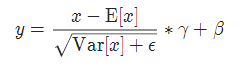
2 GroupNorm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
參數:
num_groups:需要劃分為的groups
num_features:來自期望輸入的特征數,該期望輸入的大小為'batch_size x num_features [x width]'
eps:為保證數值穩定性(分母不能趨近或取0),給分母加上的值。默認為1e-5。
momentum:動態均值和動態方差所使用的動量。默認為0.1。
affine:布爾值,當設為true,給該層添加可學習的仿射變換參數。
實現公式:
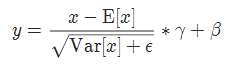
3 InstanceNorm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
參數:
num_features:來自期望輸入的特征數,該期望輸入的大小為'batch_size x num_features [x width]'
eps:為保證數值穩定性(分母不能趨近或取0),給分母加上的值。默認為1e-5。
momentum:動態均值和動態方差所使用的動量。默認為0.1。
affine:布爾值,當設為true,給該層添加可學習的仿射變換參數。
track_running_stats:布爾值,當設為true,記錄訓練過程中的均值和方差;
實現公式:
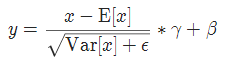
4 LayerNorm
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
參數:
normalized_shape: 輸入尺寸
[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
eps: 為保證數值穩定性(分母不能趨近或取0),給分母加上的值。默認為1e-5。
elementwise_affine: 布爾值,當設為true,給該層添加可學習的仿射變換參數。
實現公式:
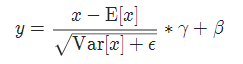
5 LocalResponseNorm
torch.nn.LocalResponseNorm(size, alpha=0.0001, beta=0.75, k=1.0)
參數:
size:用于歸一化的鄰居通道數
alpha:乘積因子,Default: 0.0001
beta :指數,Default: 0.75
k:附加因子,Default: 1
實現公式:
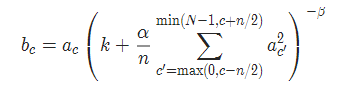
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- pytorch方法測試——激活函數(ReLU)詳解
- pytorch在fintune時將sequential中的層輸出方法,以vgg為例
- pytorch 輸出中間層特征的實例
- PyTorch之nn.ReLU與F.ReLU的區別介紹
