目錄
- 如何用Python搞到小姐姐私房照
- 正式教程
- 寫在最后
如何用Python搞到小姐姐私房照
本文純技術角度出發���,教你如何用Python爬蟲獲取百度圖庫海量照片——技術無罪。
學會獲取小姐姐私房照同理可得也能獲取其他的照片,技術原理是一致的。
目標站點
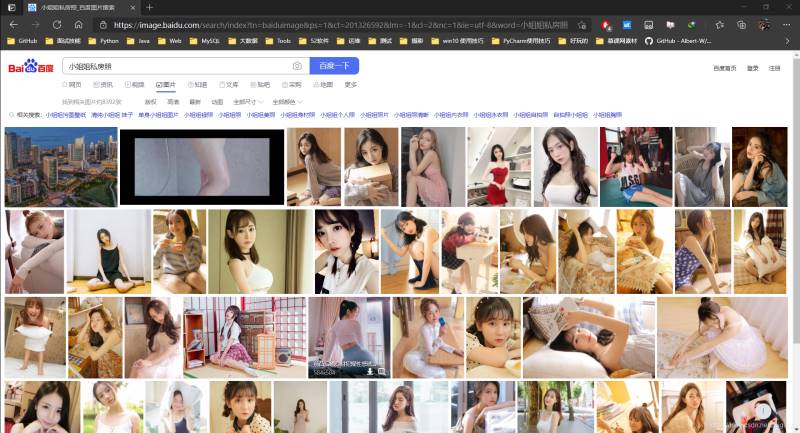
百度圖片使用關鍵字搜索 小姐姐私房照
開發環境
- 系統:Windows10 64位
- Python版本:Python3.6.5(Python3以上版本即可)
- IDE:Pycharm(非必須�����,其實你完全可以記事本寫代碼)
- 第三方庫:requests���、jsonpath
效果預覽
網頁私房照
代碼爬取效果

正式教程
一��、第三方庫安裝
在確保你正確安裝了Python解釋器之后�����,我們還需要安裝幾個第三方庫,命令如下**[在終端中安裝即可]**:
HTTP請求庫:
JSON數據解析庫:
二��、爬蟲的基本套路
- 不管是爬取哪類網站���,在爬蟲中基本都遵循以下的基本套路:
請求數據 → 獲取響應內容 → 解析內容 → 保存數據

- 當然��,以上步驟是代碼的編寫思路���,實際操作中應該還要添加一個前置步驟�,所以完整流程如下:
分析目標站點 → 請求網站獲取數據 → 解析內容 → 保存數據
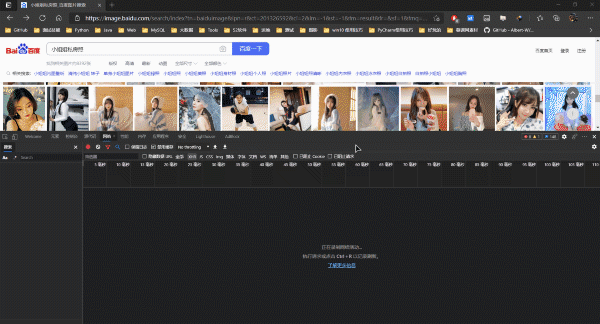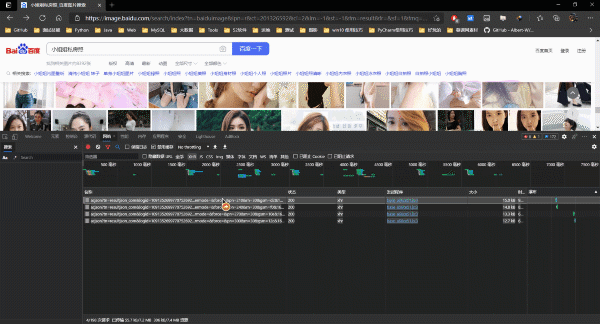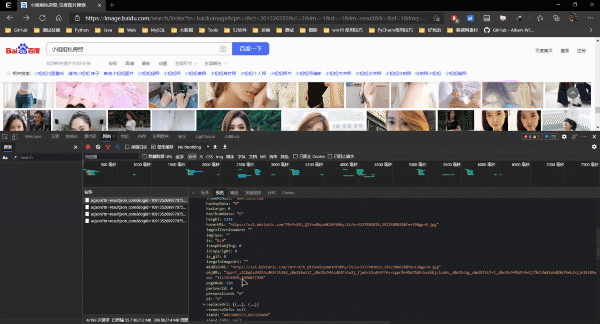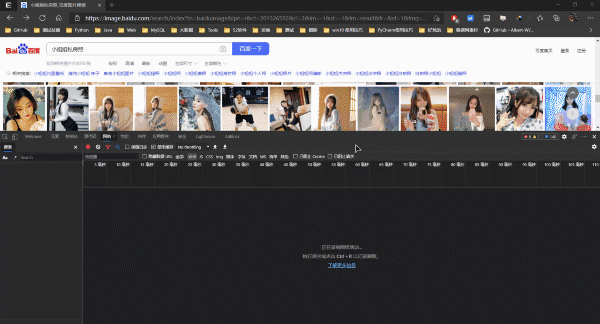
分析目標站點
快速的分析目標站點就很容易發現百度圖庫的圖片資源是通過AJAX加載的�,所以我們要請求的鏈接并非瀏覽器地址欄鏈接���,而是ajax加載的數據包的資源路徑��,如圖:
那么問題來了��,如何獲取到這些數據包的地址?其實很簡單����,如圖所示:
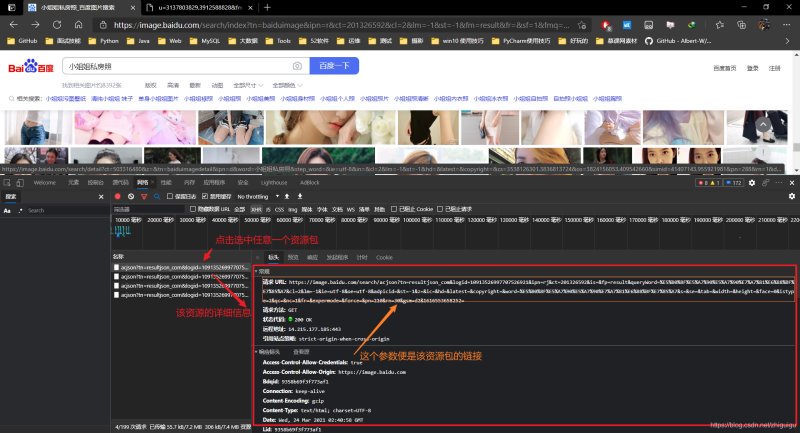
請求網站獲取數據
編寫代碼請求資源����,這里有一點需要注意:請求頭必須攜帶�����,否則有可能請求失敗導致報錯��。
import requests # 導包
# 構建請求頭,把爬蟲程序偽裝成正常的瀏覽器用戶
headers = {
'sec-fetch-dest': 'image',
'Host': 'image.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50',
}
# 資源包的url鏈接
url = 'https://image.baidu.com/search/acjson?tn=resultjson_comlogid=10913526997707526921ipn=rjct=201326592is=fp=resultqueryWord=%E5%B0%8F%E5%A7%90%E5%A7%90%E7%A7%81%E6%88%BF%E7%85%A7cl=2lm=-1ie=utf-8oe=utf-8adpicid=st=-1z=ic=hd=latest=copyright=word=%E5%B0%8F%E5%A7%90%E5%A7%90%E7%A7%81%E6%88%BF%E7%85%A7s=se=tab=width=height=face=0istype=2qc=nc=1fr=expermode=force=pn=210rn=30gsm=d21616553658252='
# 構建請求
response = requests.get(url,headers=headers)
# 查看狀態碼
print(response.status_code)
# 獲取原始數據
response.json()
解析數據
上述代碼最終獲取到的數據是json數據,也就是我們Python中常說的字典�����,它長這樣:
{
"queryEnc":"%D0%A1%BD%E3%BD%E3%CB%BD%B7%BF%D5%D5",
"queryExt":"小姐姐私房照",
"listNum":758,
"displayNum":8392,
"gsm":"f0",
"bdFmtDispNum":"約8,390",
"bdSearchTime":"",
"isNeedAsyncRequest":0,
"bdIsClustered":"1",
"data":[
Object{...}, # 沒張私房照對應的詳細信息�,其中就有圖片的URL
Object{...},
···
}
既然它是一個字典,我們當然是可以使用Python中的鍵值索引方式獲取到想要的數據��,但是此方法太笨,這里介紹一種更加高明的方式,使用jsonpath解析數據
# 這一行代碼便可以獲取到所有圖片的URL��,返回的是一個列表�����,遍歷即可拿到每一個URL
imgs = jsonpath.jsonpath(json_data, '$..middleURL')
使用requests請求圖片URL��,獲取圖片數據
image_data = requests.get(page_url).content
保存數據
使用Python中的文件對象�����,保存圖片�,圖片名字使用時間戳命名�,避免圖片重名
with open('imgs/' + datetime.now().strftime("%Y%m%d%H%M%S%f") + '.jpg', 'wb') as f:
f.write(image_data)
寫在最后
到這整個兒爬蟲程序就寫完了。
當然��,當前的這個只能爬取一個資源包中的數據����,要爬取多個資源包或者說全部資源包的數據也是很簡單的,只需要分析分析資源包的URL變化規律就不難發現其中的某個關鍵字變化,靈活改變該關鍵字就可以不斷爬取。
文章正文到這里已經結束了��,只是想感謝一些閱讀我文章的人���。
我退休后一直在學習如何寫文章����,說實在的,每次我在后臺看到一些讀者的回應就會覺得很欣慰��,于是我想把我收藏的一些編程干貨貢獻給大家��,回饋每一個讀者�,希望能幫到你們��。
到此這篇關于手把手帶你用python爬取小姐姐私房照的文章就介紹到這了,更多相關python爬取圖片內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家���!
您可能感興趣的文章:- Python使用Py2neo創建Neo4j的節點���、關系及路徑
- Python使用py2neo操作圖數據庫neo4j的方法詳解
- python利用文件讀寫編寫一個博客
- Python time.time()方法
- Python接口自動化之接口依賴
- python中bottle使用實例代碼
- python使用py2neo查詢Neo4j的節點����、關系及路徑
