繼語音論文成功入選并亮相全球頂級語音學術會議INTERSPEECH2019后,標貝科技再登全球語音大賽舞臺Blizzard Challenge2019(譯為暴雪挑戰賽)。
9月23日,全球語音合成領域最具權威性和影響力的國際比賽Blizzard Challenge2019在奧地利維也納城市舉辦。作為全球語音合成發展的推動者,標貝科技受邀成為大賽贊助企業,并亮相現場做精彩開場發言。其中,與標貝一同贊助的另一家全球企業還包括蘋果,2家企業共同支持語音科研的發展。
Blizzard Challenge是由全球知名科研高校組織,旨在構建一個公開、統一的語音合成技術評測平臺,以此加強全球研究機構之間的技術交流與溝通,推動語音技術快速發展。本屆Blizzard Challenge2019組委會評委由英國愛丁堡大學、美國卡內基梅隆大學、日本名古屋工業大學等全球高校專家構成,參賽內容為中文語音合成效果對比測評,吸引了來自日本、新加坡、美國、中國等全球多個國家地區高校及廠商參賽。
在開場發言中,標貝科技海外業務相關負責人介紹了標貝自有語音合成技術應用與數據業務的產品服務特色。標貝在業內擁有領先的語音合成技術及深厚AI數據基礎,致力于為全球客戶提供高品質、多類別、多場景的語音合成方案,以及高質量、安全與多語種為特點的專業數據服務。
“標貝科技自成立以來,始終把數據安全與質量放在首位,基于深度學習+高精度預處理技術,以及國際安全體系保障,為客戶提供高質量、安全、專業的數據設計、數據采集、數據加工處理、評測分析等服務,業務覆蓋語音合成、語音識別、計算機視覺、自然語言處理、歌曲等重要領域,致力于讓產品更加智能與精準。”以上負責人說。
在數據質量方面,標貝經過嚴格專業的立項設計、數據采集加工處理、語音標注校對及結構處理等系列流程,能夠實現快速產出高質量的人工智能數據,與算法、模型、架構等進行深度匹配,形成可進行落地的產品形態。
在安全方面,標貝擁有歐盟GDPR通用數據保護條例、英國ISO信息安全管理體系標準為指導,以數據主體及用戶隱私保護為核心,建立數據信息安全體系。實時嚴格監管數據控制、處理過程,制定數據安全性操作指導規范及應急響應機制,以此保護數據主體及用戶數據隱私安全。
基于以上2方面的數據優勢,標貝能夠創造高質量與多語種為特色的語音數據庫。據了解,標貝數據總規模時長超過10萬小時,其中語音合成數據超過3000小時,覆蓋韓語、日語、葡萄牙語、德語、法語、意大利語、西班牙語、俄語等10余種外語語言數據及中美兒童、男女聲、粵語、臺語、天津話、四川話、東北話等中文及方言數據;而在語音識別數據方面,總規模時長超過97000小時,包括英日韓等3大主流外語及成人、青少年、兒童中文、英文、中英混數據,普通話及四川話、粵語、閩南話、上海話、藏語等中文及方言數據。
在現場,來自不同地區的科研團體及語音廠商對標貝自有語音技術創新及產品服務理念表達了高度認同。
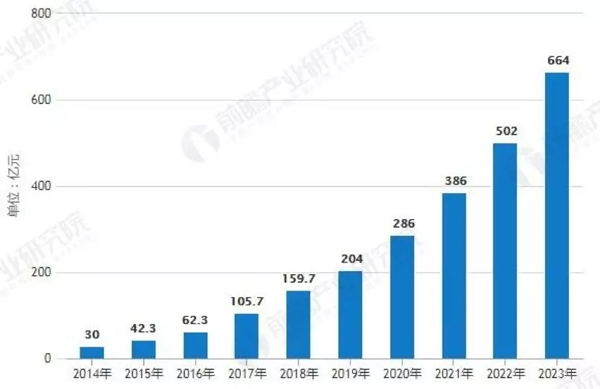
近年來,AI技術與語音合成應用不斷融合,推動全球語音產業的發展。來自第三方的數據機構《前瞻經濟學人》發布的數據預測,2023年中國智能語音市場規模將達到664億元。
“盡管全球語音及數據市場迎來了高速增長期,特別是中國市場,但數據安全與質量仍然是國內外廠商普遍關注的重點。”現場一位企業代表說道。
在發言結尾,標貝海外負責人介紹,“標貝在技術+數據+應用3端不斷創新,過去3年來取得了飛速的發展,收獲了包括微軟、百度、阿里、騰訊、京東、滴滴、字節跳動等在內的全球百余家企業客戶。”標貝未來將加大創新力度,為全球客戶提供高質量與專業的語音及數據服務。