接觸MGR有一段時間了,MySQL 8.0.23的到來,基于MySQL Group Replicaion(MGR)的高可用架構又提供了新的架構思路。
災備機房的slave,如何更好的支持主機房的MGR?
MGR 到底可以壞幾個節點?
這次我就以上2個問題,和大家簡單聊下MGR的一些思想和功能。
一、MySQL Group Relication 成員數量的容錯能力
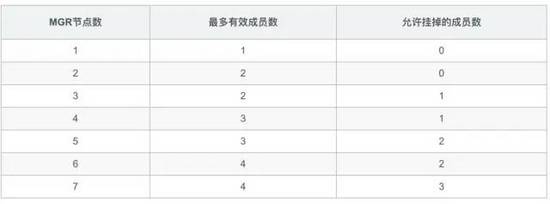
上面的表格相信大家不會陌生了,我經常在面試里會問:“4個節點的MGR,最多壞幾個呢?” ,多數人回答:“最多壞1個,壞2個就腦裂不能工作了。”
那我們來看看MGR的處理方式,是不是這個答案呢?
1)我們具有一個4節點MGR
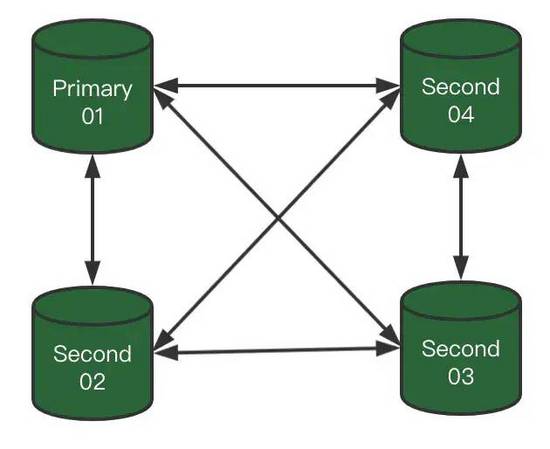
埋一個問題:這個圖一看就是Single模式,但箭頭不是單向,是不是畫錯了?
2)此時,Second-04突然宕機了,那么MGR集群會成什么樣子呢?
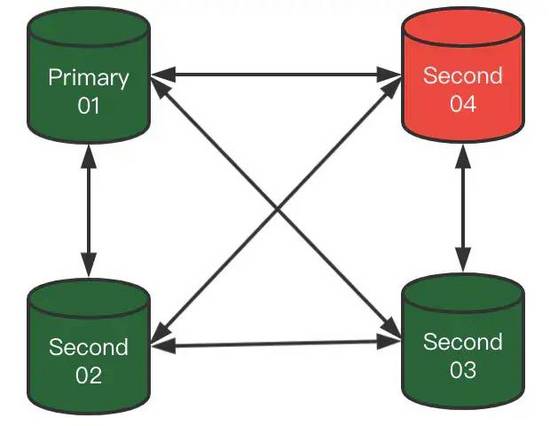
集群此時狀態會變成:
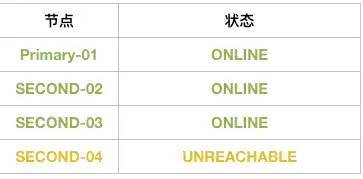
- 每個節點會固定時間交換各自信息。
- 當沒有收到Second-04節點信息后,其他成員會等待5秒。
- 這個期間Second-04肯定沒有發出來消息,于是健康成員認為Second-04是可疑狀態,標記UNREACHABLE狀態。
- 然后健康成員按照參數:group_replication_member_expel_timeout,繼續等待(此時Second-04依然是UNREACHABLE狀態)。
- 當超過了group_replication_member_expel_timeout時間,健康成員就把Second-04節點驅逐出集群了。
那么重點來了,敲黑板
在Second-04,沒有被驅逐出去時:
此時集群是(4節點-3健康-1壞),這個期間如果繼續壞1個節點,那么集群變成(4節點-2健康-2壞),集群沒有滿足多數原則,每個節點都無法寫入了(除非人工干預,強制指定集群成員List)。
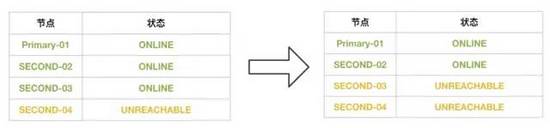
在Second-04,被驅逐出去后:
此時集群是(3節點-3健康-0壞),4節點集群退化成3節點健康集群了,這個時候,集群依然可以繼續壞一個節點,變成(3節點-2健康-1壞)
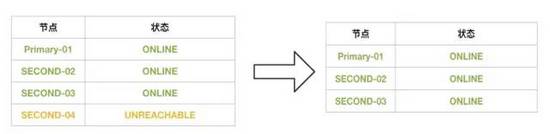
所以4節點集群是否可以壞1個還是2個,具體要看集群處理過程哪個階段哦。
PS:
我們說說剛才埋的問題:這個圖一看就是Single模式,但箭頭不是單向,是不是畫錯了?
首先Single模式,Second節點默認是不能寫入的,但只是由于Second節點的super-read-only開啟了。
將Second節點super-read-only = 0,Second節點可以正常寫入,并可以同步其他節點(Primary和其他Second),傳輸還是基于Paxos協議的。
跑個火車:Second節點反向同步其他節點,是不會經過沖突檢測階段(理論效率要高于多寫模式),沒有驗證,大家有興趣可以研究下。
二、 Asynchronous Connection Failover
MySQL 8.0.22,推出了異步復制連接故障轉移,很多朋友都發文做了介紹,這里我只簡單描述下:
1)同機房1主1從,異地機房單獨放一個slave節點
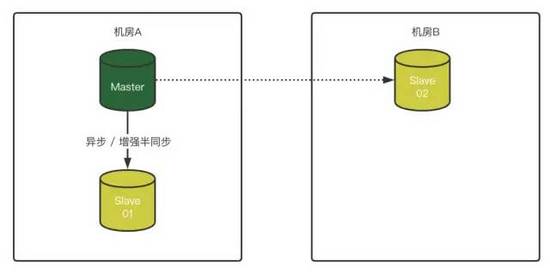
2)Master 故障,將Slave-01變成Master,Slave-02無法連接原Master
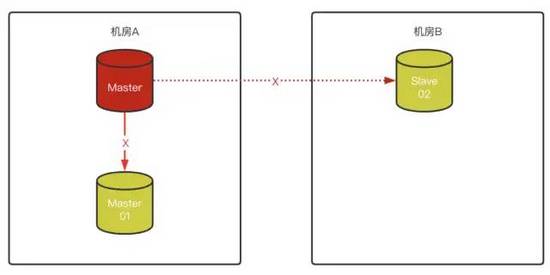
3)如果對Slave-02配置了“異步連接故障轉移配置”,那么Slave-02在識別原Master故障后,會自動嘗試按照預先定義好的配置,與原Slave-01(新Master)建立復制關系:
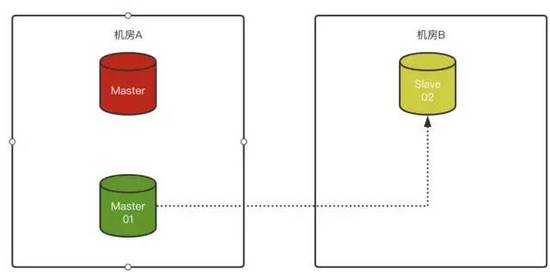
這個功能非常好,引用三方工具(例如MHA的修復主從關系)已經可以被MySQL原生功能代替了。
但我測試完,又有了幾點疑慮:
1. “異步”復制故障轉移,難道不支持半同步架構?不能確保數據不丟失,還是無法完全代替MHA啊?
答:其實是支持增強半同步的。
2. 要預先配置故障轉移的Master List,那么A機房架構變更,還要去維護機房B的節點嗎?
答:是的。
3. 如果A機房是MGR,那么MGR的節點(master)異常,但服務沒有關,可以訪問,機房B節點豈不是一直連接著?
答:是的
然后,MySQL 8.0.23發布了,帶來了此功能的增強:
Slave可以支持MGR集群,并且可以動態識別MGR成員,來建立Master-Slave關系了

最后讓我們跑一圈:
1)首先我們有3節點的MGR集群,版本8.0.22(異步連接故障轉移,是作用在Slave的IO Thread上的,所以Slave是8.0.23版本就成)
+----------------------------+-------------+--------------+-------------+---------------------+
| now(6) | member_host | member_state | member_role | VIEW_ID |
+----------------------------+-------------+--------------+-------------+---------------------+
| 2021-01-22 13:41:27.902251 | mysql-01 | ONLINE | SECONDARY | 16112906030396799:9 |
| 2021-01-22 13:41:27.902251 | mysql-02 | ONLINE | PRIMARY | 16112906030396799:9 |
| 2021-01-22 13:41:27.902251 | mysql-03 | ONLINE | SECONDARY | 16112906030396799:9 |
+----------------------------+-------------+--------------+-------------+---------------------+
2)然后我們在獨立Slave節點,指定Slave上“對Master連接故障轉移列表”
SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1', 'mysql-02', 3306, '', 80, 60);
簡單解釋下參數:
ch1:chanel名稱
GroupReplication:強制寫死的參數,目前支持MGR集群
aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1:MGR組名(參數 group_replication_group_name)
mysql-02:MGR成員之一
80:Primary節點的優先級(0-100),多主相同優先級則隨機選擇節點充當master。
60:Second節點的優先級(0-100),基本就是給Single模式準備的
3)為Slave指定復制通道信息
CHANGE REPLICATION SOURCE TO SOURCE_USER='rpl_user', SOURCE_PASSWORD='123456', SOURCE_HOST='mysql-02',SOURCE_PORT=3306,SOURCE_RETRY_COUNT=2,SOURCE_CONNECTION_AUTO_FAILOVER=1,SOURCE_AUTO_POSITION=1 For CHANNEL 'ch1';
4)啟動Slave,并查看“連接的可轉移列表”
不開啟io thread,是不會自動識別MGR成員的。并且復制用戶
rpl_user需要在MGR節點對performance_schema具有select權限
start slave;
SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
+--------------+----------+------+-------------------+--------+--------------------------------------+
| CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME |
+--------------+----------+------+-------------------+--------+--------------------------------------+
| ch1 | mysql-01 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
| ch1 | mysql-02 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
| ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
+--------------+----------+------+-------------------+--------+--------------------------------------+
5)然后我們將mysql-02 stop group_replication(不是關閉服務),
Slave列表自動淘汰mysql-02,重新與其他節點建立連接-- mysql-02(Primary):
stop group_replication;
-- Slave:
SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
+--------------+----------+------+-------------------+--------+--------------------------------------+
| CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME |
+--------------+----------+------+-------------------+--------+--------------------------------------+
| ch1 | mysql-01 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
| ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
+--------------+----------+------+-------------------+--------+--------------------------------------+
show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-01
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mybinlog.000003
Read_Master_Log_Pos: 4904
Relay_Log_File: mysql-01-relay-bin-ch1.000065
Relay_Log_Pos: 439
Relay_Master_Log_File: mybinlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
至此,配置完成。后面MGR節點增、減,Slave都可以自動維護這個列表。不貼其他用例了。
PS:
如果想手工切換Slave已建立的Master節點(Primary)連接到其他節點(Second)上,只需要刪除“復制連接的可轉移列表”,重新調整Second優先級加回即可。
-- 刪除配置
SELECT asynchronous_connection_failover_delete_managed('ch1', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1');
-- 重新添加,調整Second優先級高于Primary
SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaaaaaaaa-aaaa-aaaa-aaaaaaaaaaa1', 'mysql-03', 3306, '', 60, 80);
參考連接:
https://mysqlhighavailability.com/automatic-asynchronous-replication-connection-failover/
https://my.oschina.net/u/4591256/blog/4813037
https://dev.mysql.com/doc/refman/8.0/en/replication-functions-source-list.html
到此這篇關于MySQL 8.0.23中復制架構從節點自動故障轉移的文章就介紹到這了,更多相關MySQL自動故障轉移內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- MySql主從復制機制全面解析
- 磁盤寫滿導致MySQL復制失敗的解決方案
- Mysql主從復制與讀寫分離圖文詳解
- MySQL 復制表的方法
- MYSQL數據庫GTID實現主從復制實現(超級方便)
- MySql主從復制實現原理及配置
- 淺析MySQL的WriteSet并行復制
- MySQL主從復制原理以及需要注意的地方
- mysql 如何動態修改復制過濾器
- 淺析MySQL并行復制
- MySQL復制問題的三個參數分析
