需求:
合并某一個(gè)字段的相同項(xiàng),并且要按照另一個(gè)時(shí)間字段排序。
例子:
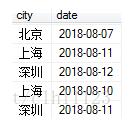
一開(kāi)始用
select city from table group by city order by date desc
會(huì)報(bào)錯(cuò)因?yàn)閐ate沒(méi)有包含在聚合函數(shù)或 GROUP BY 子句中
然后用將date放入group by中:
select city from table group by city,date order by date desc
得到結(jié)果
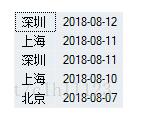
但是得到的結(jié)果還是有重復(fù)的,沒(méi)有解決
如果不按照時(shí)間排序,就會(huì)影響我之后的操作,所以百度了很久,終于找到了解決方法:
正確寫(xiě)法:
select city from table group by city order by max(date) desc
發(fā)現(xiàn)很神奇的結(jié)果出來(lái)了

然后又找了一些資料,發(fā)現(xiàn)max()神奇的地方:
select city,max(date) as d1 from table group by city,d1 order by d1 desc
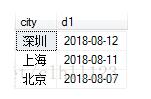
這里寫(xiě)在前面還能看到時(shí)間排序
如果還有更好的方法大家一起交流。
補(bǔ)充:MYSQL中去重,DISTINCT和GROUP BY的區(qū)別
例如有如下表user:
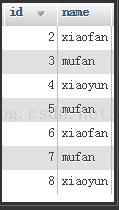
distinct會(huì)過(guò)濾掉它后面每個(gè)字段都重復(fù)的記錄
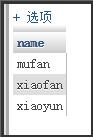
用distinct來(lái)返回不重復(fù)的用戶名:select distinct name from user;,結(jié)果為:
用distinct來(lái)返回不重復(fù)的name和id:select distinct name,id from user;,結(jié)果為:
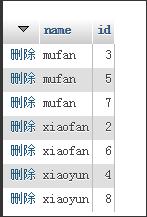
distinct name,id 這樣的寫(xiě)法,mysql 會(huì)認(rèn)為要過(guò)濾掉name和id兩個(gè)字段都重復(fù)的記錄。
如果sql這樣寫(xiě):
select id,distinct name from user
這樣mysql會(huì)報(bào)錯(cuò),因?yàn)閐istinct必須放在要查詢字段的開(kāi)頭。
group by則可以在要查詢的多個(gè)字段中,針對(duì)其中一個(gè)字段去重 :
select id,name from user group by name;
以上為個(gè)人經(jīng)驗(yàn),希望能給大家一個(gè)參考,也希望大家多多支持腳本之家。如有錯(cuò)誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- 詳解SQL中Group By的用法
- SQL去除重復(fù)記錄(七種)
- 深入淺析SQL中的group by 和 having 用法
- MySQL中按照多字段排序及問(wèn)題解決
