1.pyspider介紹
一個國人編寫的強大的網絡爬蟲系統并帶有強大的WebUI。采用Python語言編寫,分布式架構,支持多種數據庫后端,強大的WebUI支持腳本編輯器,任務監視器,項目管理器以及結果查看器。
- 用Python編寫腳本
- 功能強大的WebUI,包含腳本編輯器,任務監視器,項目管理器和結果查看器
- MySQL,MongoDB,Redis,SQLite,Elasticsearch ; PostgreSQL與SQLAlchemy作為數據庫后端
- RabbitMQ,Beanstalk,Redis和Kombu作為消息隊列
- 任務優先級,重試,定期,按年齡重新抓取等...
- 分布式架構,抓取JavaScript頁面,Python 2和3等...
2.pyspider文檔
1>中文文檔:http://www.pyspider.cn/
2>英文文檔:http://docs.pyspider.org/
3.pyspider安裝
打開cmd命令行工具,執行命令
出現下圖則安裝成功

4.pyspider啟動服務,進入WebUI界面
安裝pyspider后,打開cmd命令工具,執行命令來啟動服務器
出現下圖則啟動服務成功,默認地址端口為127.0.0.1:5000
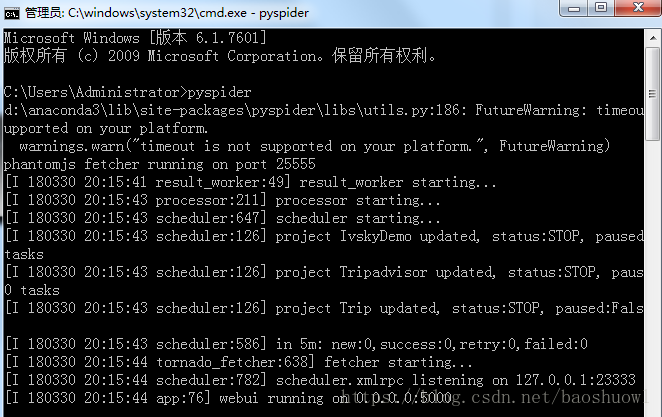
輸入地址127.0.0.1:5000,打開WebUI界面
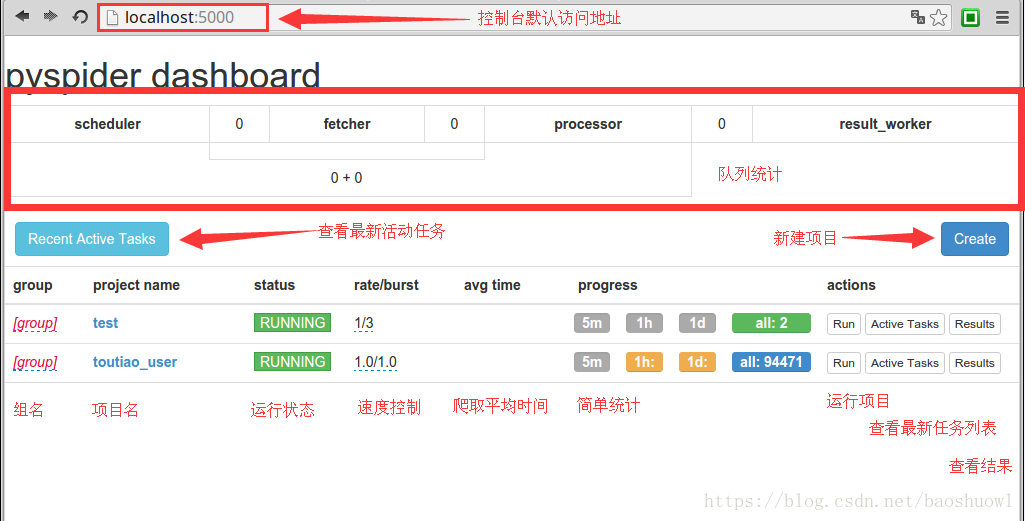
隊列統計是為了方便查看爬蟲狀態,優化爬蟲爬取速度新增的狀態統計.每個組件之間的數字就是對應不同隊列的排隊數量.通常來是0或是個位數.如果達到了幾十甚至一百說明下游組件出現了瓶頸或錯誤,需要分析處理.
新建項目:pyspider與scrapy最大的區別就在這,pyspider新建項目調試項目完全在web下進行,而scrapy是在命令行下開發并運行測試.
組名:項目新建后一般來說是不能修改項目名的,如果需要特殊標記可修改組名.直接在組名上點鼠標左鍵進行修改.注意:組名改為delete后如果狀態為stop狀態,24小時后項目會被系統刪除.
運行狀態:這一欄顯示的是當前項目的運行狀態.每個項目的運行狀態都是單獨設置的.直接在每個項目的運行狀態上點鼠標左鍵進行修改.運行分為五個狀態:TODO,STOP,CHECKING,DEBUG,RUNNING.各狀態說明:TODO是新建項目后的默認狀態,不會運行項目.STOP狀態是停止狀態,也不會運行.CHECHING是修改項目代碼后自動變的狀態.DEBUG是調試模式,遇到錯誤信息會停止繼續運行,RUNNING是運行狀態,遇到錯誤會自動嘗試,如果還是錯誤會跳過錯誤的任務繼續運行.
速度控制:很多朋友安裝好用說爬的慢,多數情況是速度被限制了.這個功能就是速度設置項.rate是每秒爬取頁面數,burst是并發數.如1/3是三個并發,每秒爬取一個頁面.
簡單統計:這個功能只是簡單的做的運行狀態統計,5m是五分鐘內任務執行情況,1h是一小時內運行任務統計,1d是一天內運行統計,all是所有的任務統計.
運行:run按鈕是項目初次運行需要點的按鈕,這個功能會運行項目的on_start方法來生成入口任務.
任務列表:顯示最新任務列表,方便查看狀態,查看錯誤等
結果查看:查看項目爬取的結果.
5.創建pyspider項目
點擊上圖中的新建項目按鈕
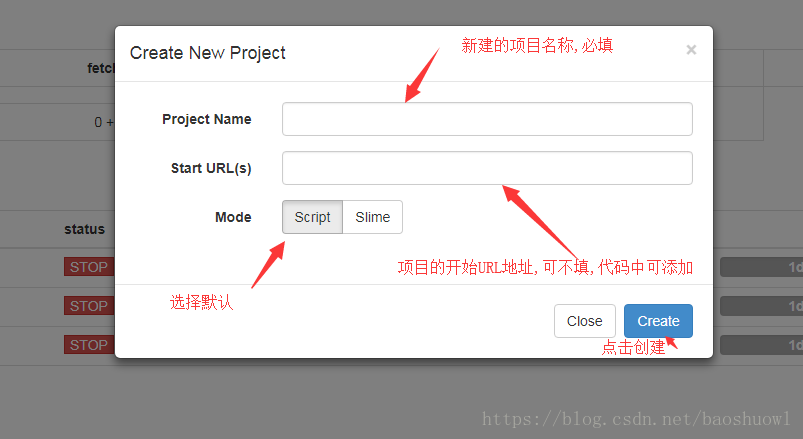
6.創建后的pyspider項目
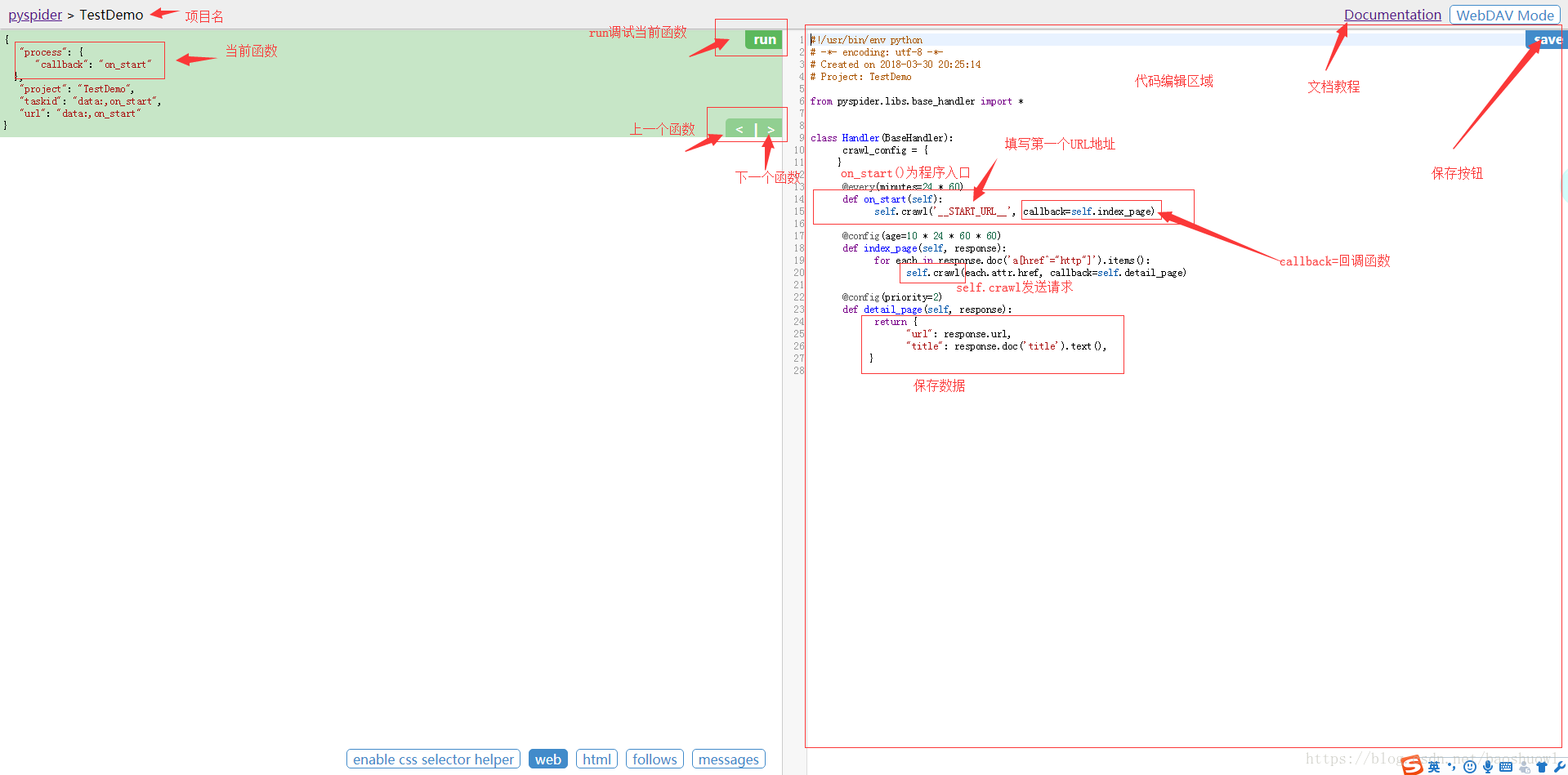
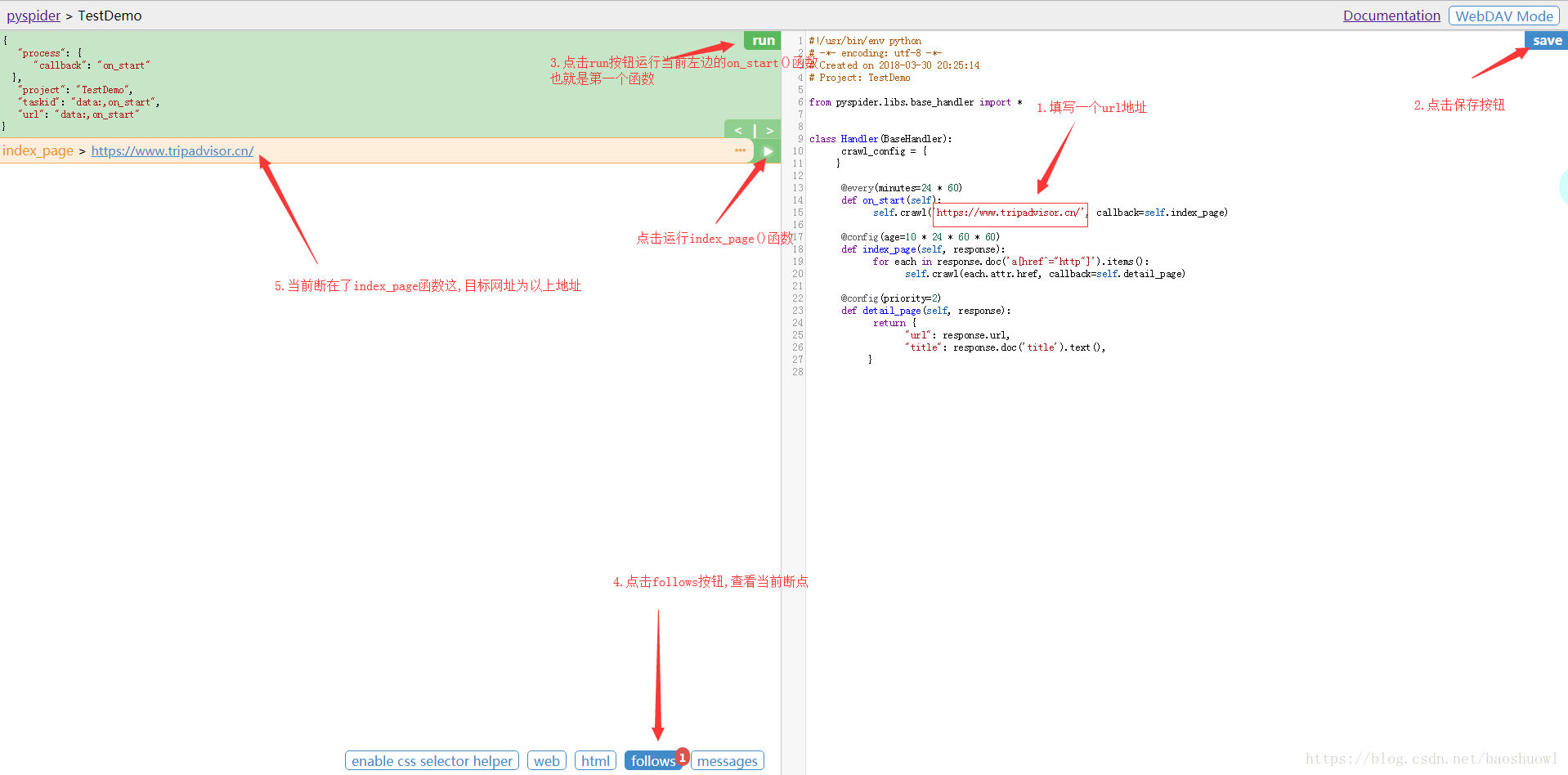
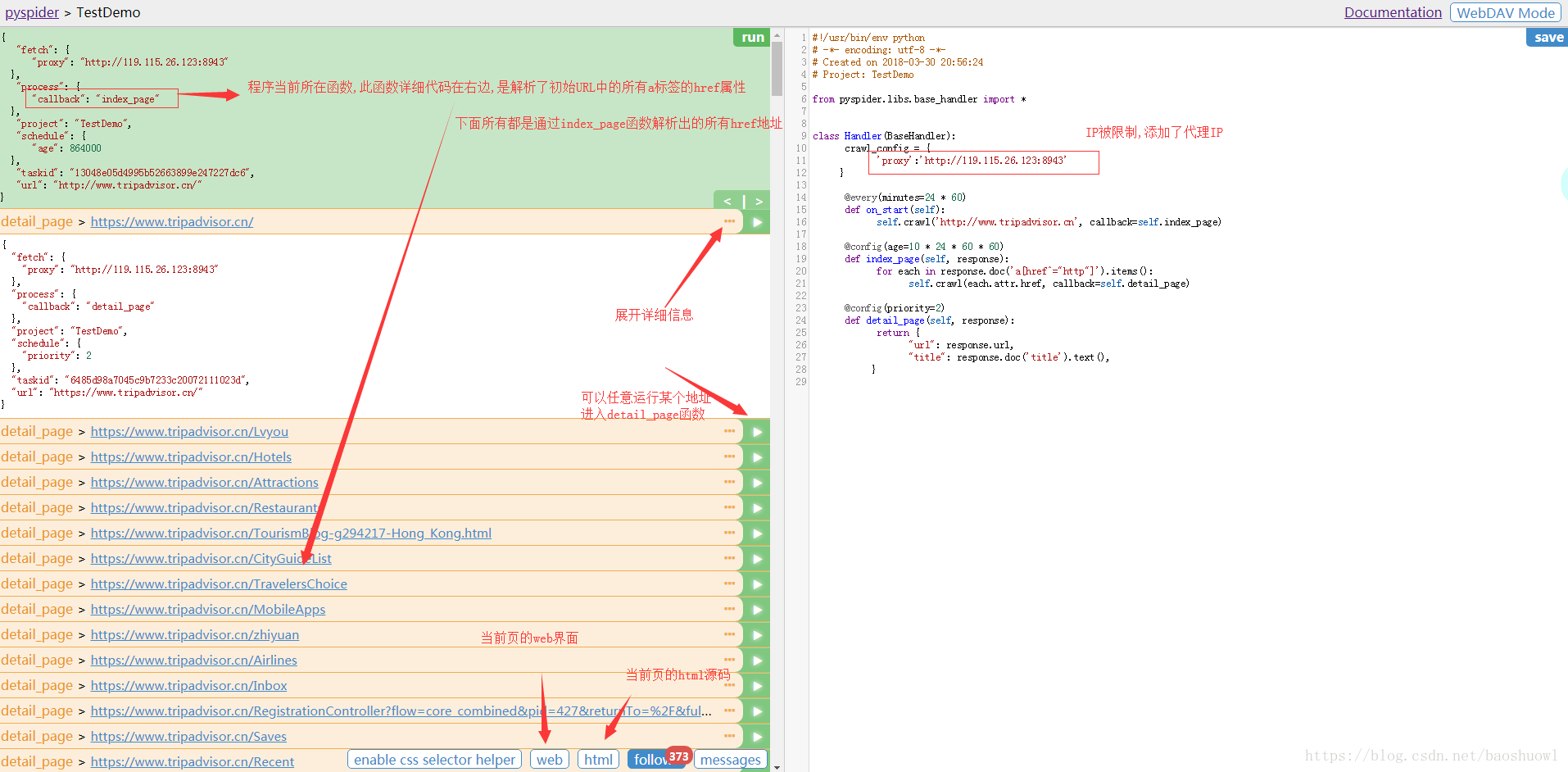
到此這篇關于Python中Pyspider爬蟲框架的基本使用詳解的文章就介紹到這了,更多相關Pyspider爬蟲框架使用內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬蟲框架feapder的使用簡介
- 一文讀懂python Scrapy爬蟲框架
- python Scrapy爬蟲框架的使用
- 詳解Python的爬蟲框架 Scrapy
- python3 Scrapy爬蟲框架ip代理配置的方法
- Python3環境安裝Scrapy爬蟲框架過程及常見錯誤
- windows下搭建python scrapy爬蟲框架步驟
- windows7 32、64位下python爬蟲框架scrapy環境的搭建方法
- 上手簡單,功能強大的Python爬蟲框架——feapder
