交叉表(cross-tabulation,簡(jiǎn)稱(chēng)crosstab)是⼀種⽤于計(jì)算分組頻率的特殊透視表。
語(yǔ)法詳解:
pd.crosstab(index, # 分組依據(jù)
columns, # 列
values=None, # 聚合計(jì)算的值
rownames=None, # 列名稱(chēng)
colnames=None, # 行名稱(chēng)
aggfunc=None, # 聚合函數(shù)
margins=False, # 總計(jì)行/列
dropna=True, # 是否刪除缺失值
normalize=False #
)
1 crosstab() 實(shí)例1
1.1 讀取數(shù)據(jù)
import os
import numpy as np
import pandas as pd
file_name = os.path.join(path, 'Excel_test.xls')
df = pd.read_excel(io=file_name, # 工作簿路徑
sheetname='透視表', # 工作表名稱(chēng)
skiprows=1, # 要忽略的行數(shù)
parse_cols='A:D' # 讀入的列
)
df
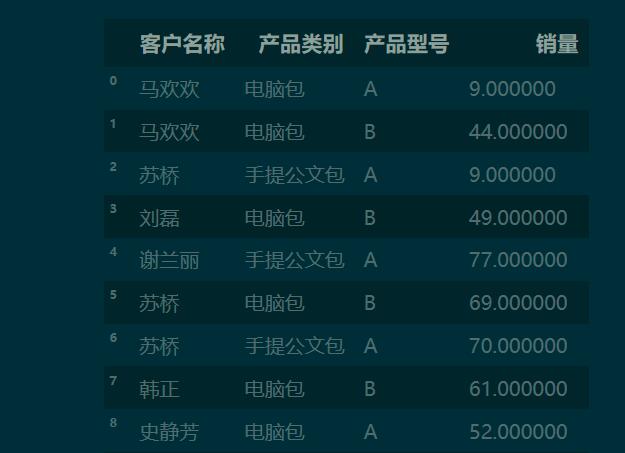
1.2 pd.crosstab() 默認(rèn)生成以行和列分類(lèi)的頻數(shù)表
pd.crosstab(df['客戶(hù)名稱(chēng)'], df['產(chǎn)品類(lèi)別'])
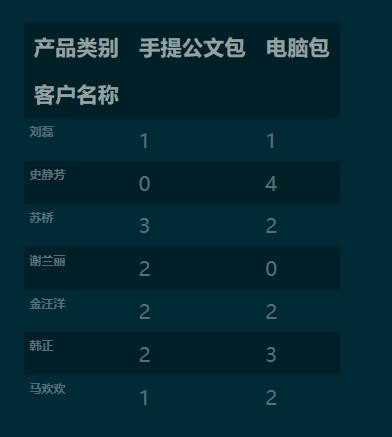
1.3 設(shè)置跟多參數(shù)實(shí)現(xiàn)分類(lèi)匯總
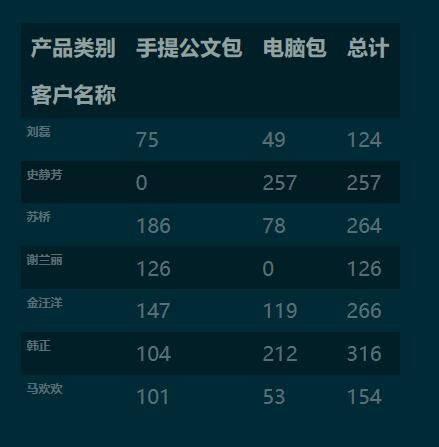
pd.crosstab(index=df['客戶(hù)名稱(chēng)'],
columns=df['產(chǎn)品類(lèi)別'],
values=df['銷(xiāo)量'],
aggfunc='sum',
margins=True
).round(0).fillna(0).astype('int')
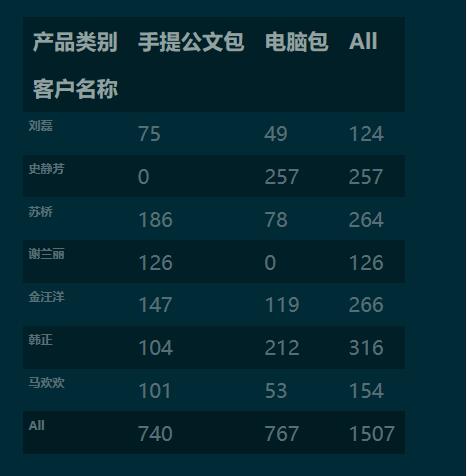
注:因?yàn)榻徊姹硎就敢暠淼奶乩越徊姹砜梢杂猛敢暠淼暮瘮?shù)實(shí)現(xiàn)。又因?yàn)橥敢暠砜梢杂酶?python 的方式 groupby-apply 實(shí)現(xiàn),所以,交叉表完全可以用 groupby-apply 的方式實(shí)現(xiàn)。
2 用分類(lèi)匯總的方法實(shí)現(xiàn) 交叉表
df.groupby(['客戶(hù)名稱(chēng)', '產(chǎn)品類(lèi)別']).apply(sum)
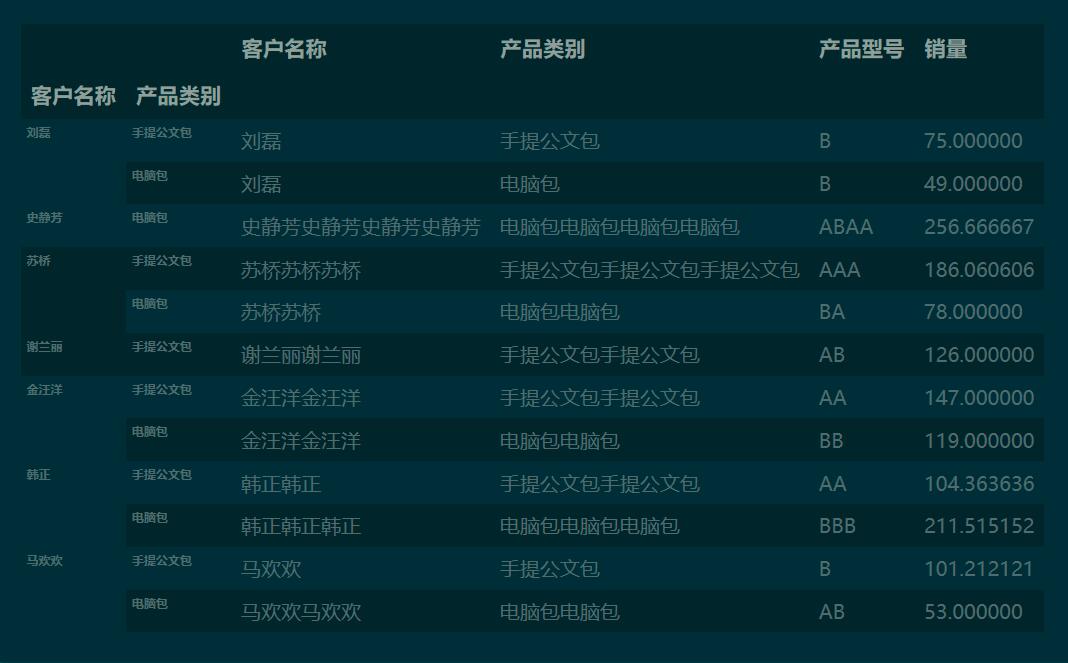
2.1 分類(lèi)匯總、重新索引、設(shè)置數(shù)值格式綜合應(yīng)用
c_tbl = df.groupby(['客戶(hù)名稱(chēng)', '產(chǎn)品類(lèi)別']).apply(sum)['銷(xiāo)量'].unstack()
c_tbl['總計(jì)'] = c_tbl.sum(axis=1) # 添加總計(jì)列
c_tbl.fillna(0).round(0).astype('int')
軟件信息:

補(bǔ)充:使用python(pandas)將數(shù)據(jù)處理成交叉分組表
交叉分組表是匯總兩種變量數(shù)據(jù)的方法, 在很多場(chǎng)景可以用到, 本文會(huì)介紹如何使用pandas將包含兩個(gè)變量的數(shù)據(jù)集處理成交叉分組表.
環(huán)境
pandas
python 2.7
原理
用坐標(biāo)軸來(lái)進(jìn)行比喻, 其中一個(gè)變量作為x軸, 另一個(gè)作為y軸, 如果定位到數(shù)據(jù)則累加一, 將所有數(shù)據(jù)遍歷一遍, 最后的坐標(biāo)軸就是一張交叉分組表(使用坐標(biāo)軸展示的數(shù)據(jù)一般是連續(xù)的, 交叉分組表的數(shù)據(jù)是離散的).
具體實(shí)現(xiàn)
示例數(shù)據(jù):
quality price
0 bad 18
1 bad 17
2 great 52
3 good 28
4 excellent 88
5 great 63
6 bad 8
7 good 22
8 good 68
9 excellent 98
10 great 53
11 bad 13
12 great 62
13 good 48
14 excellent 78
15 great 63
16 good 37
17 great 69
18 good 28
19 excellent 81
20 great 43
21 good 32
22 great 62
23 good 28
24 excellent 82
25 great 53
代碼:
import pandas as pd
from pandas import DataFrame, Series
#生成數(shù)據(jù)
df = DataFrame([['bad', 18], ['bad', 17], ['great', 52], ['good', 28], ['excellent', 88], ['great', 63]
, ['bad', 8], ['good', 22], ['good', 68], ['excellent', 98], ['great', 53]
, ['bad', 13], ['great', 62], ['good', 48], ['excellent', 78], ['great', 63]
, ['good', 37], ['great', 69], ['good', 28], ['excellent', 81], ['great', 43]
, ['good', 32], ['great', 62], ['good', 28], ['excellent', 82], ['great', 53]], columns = ['quality', 'price'])
#廣播使用的函數(shù)
def quality_cut(data):
s = Series(pd.cut(data['price'], np.arange(0, 100, 10)))
return pd.groupby(s, s).count()
#進(jìn)行分組處理
df.groupby(df['quality']).apply(quality_cut)
結(jié)果:
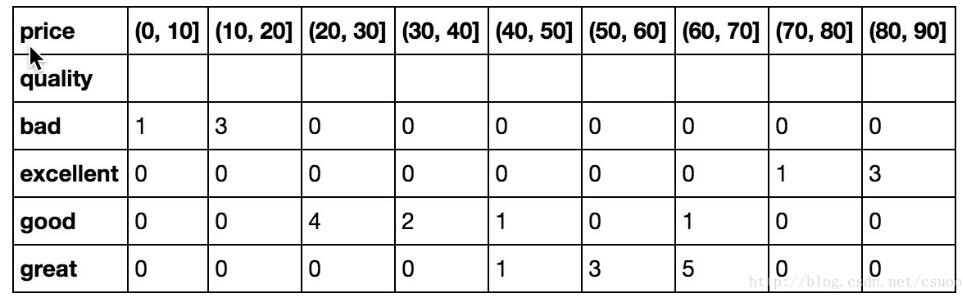
交叉分組
詳細(xì)分析
從邏輯上來(lái)看, 為了達(dá)到對(duì)示例數(shù)據(jù)的交叉分組, 需要完成以下工作:
將數(shù)據(jù)以quality列進(jìn)行分組.
將每個(gè)分組的數(shù)據(jù)分別進(jìn)行cut, 以10為間隔.
將cut過(guò)的數(shù)據(jù), 以cut的范圍為列進(jìn)行分組
將所有數(shù)據(jù)組合到一起, row為quality, columns為cut的范圍
步驟1, pandasgroupby(...)接口, 會(huì)按照指定的列進(jìn)行分組處理, 每一個(gè)分組, 存儲(chǔ)相同類(lèi)別的數(shù)據(jù)
class 'pandas.core.frame.DataFrame'>
quality price
0 bad 18
1 bad 17
6 bad 8
11 bad 13
而我們需要的, 只是price這列的數(shù)據(jù), 所以單獨(dú)將這列拿出來(lái), 進(jìn)行cut, 最后得到我們要的series(步驟2, 步驟3)
price
(0, 10] 1
(10, 20] 3
(20, 30] 0
(30, 40] 0
(40, 50] 0
(50, 60] 0
(60, 70] 0
(70, 80] 0
(80, 90] 0
使用pandas
apply()的廣播特性, 每一個(gè)分組的數(shù)據(jù)都會(huì)經(jīng)過(guò)上述幾個(gè)步驟的處理, 最后與第一次分組row進(jìn)行組合.
后記
估計(jì)能力有限, 這個(gè)問(wèn)題想了很長(zhǎng)時(shí)間, 沒(méi)想到pandas這么可以這么方便達(dá)成交叉分組的效果. 思考的時(shí)候主要是卡在數(shù)據(jù)組合上, 當(dāng)數(shù)據(jù)量很大時(shí)通過(guò)多個(gè)步驟進(jìn)行數(shù)據(jù)組合, 肯定是低效而且錯(cuò)誤的. 最后仔細(xì)研究了groupby, dataframe, series, dataframeIndex等數(shù)據(jù)模型, 使用廣播特性用幾句代碼就完成了. 證明了pandas的高性能, 也提醒自己遇見(jiàn)問(wèn)題一定要耐心分析。
以上為個(gè)人經(jīng)驗(yàn),希望能給大家一個(gè)參考,也希望大家多多支持腳本之家。如有錯(cuò)誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- python基于Pandas讀寫(xiě)MySQL數(shù)據(jù)庫(kù)
- python中pandas.read_csv()函數(shù)的深入講解
- python pandas合并Sheet,處理列亂序和出現(xiàn)Unnamed列的解決
- python 使用pandas同時(shí)對(duì)多列進(jìn)行賦值
- python之 matplotlib和pandas繪圖教程
- Python3 pandas.concat的用法說(shuō)明
- python pandas模糊匹配 讀取Excel后 獲取指定指標(biāo)的操作
- 聊聊Python pandas 中l(wèi)oc函數(shù)的使用,及跟iloc的區(qū)別說(shuō)明
- python Polars庫(kù)的使用簡(jiǎn)介
