三種數據抓取的方法
- 正則表達式(re庫)
- BeautifulSoup(bs4)
- lxml
*利用之前構建的下載網頁函數,獲取目標網頁的html,我們以https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/為例,獲取html。
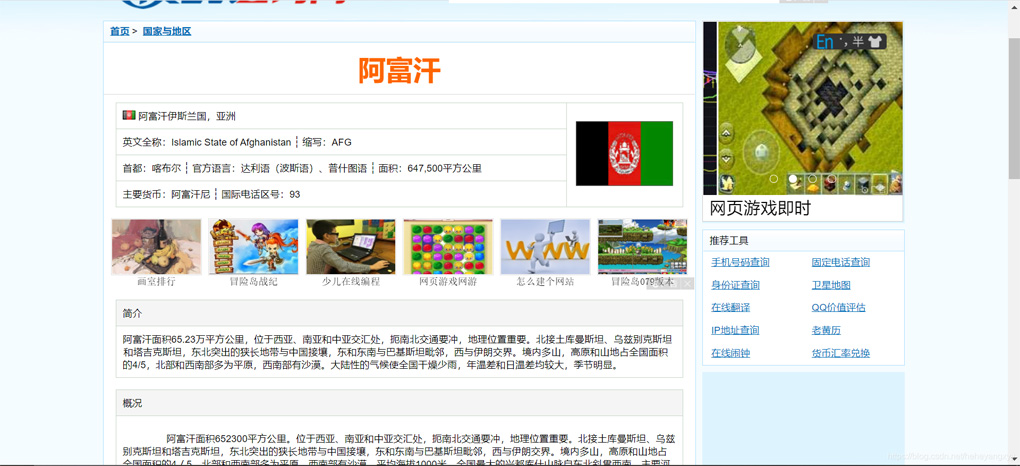
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假設我們需要爬取該網頁中的國家名稱和概況,我們依次使用這三種數據抓取的方法實現數據抓取。
1.正則表達式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)/h2>', page_content) #注意返回的是list
survey_data = re.findall('tr>td bgcolor="#FFFFFF" id="wzneirong">(.*?)/td>/tr>', page_content)
survey_info_list = re.findall('p> (.*?)/p>', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#創建 beautifulsoup 對象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析樹
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可進行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
運行結果:

最后,引用《用python寫網絡爬蟲》中對三種方法的性能對比,如下圖:

僅供參考。
總結
到此這篇關于python數據抓取3種方法的文章就介紹到這了,更多相關python數據抓取內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python采用requests庫模擬登錄和抓取數據的簡單示例
- Python爬蟲抓取手機APP的傳輸數據
- 通過抓取淘寶評論為例講解Python爬取ajax動態生成的數據(經典)
- python抓取某汽車網數據解析html存入excel示例
- Python實現并行抓取整站40萬條房價數據(可更換抓取城市)
- Python基于多線程實現抓取數據存入數據庫的方法
- 對python抓取需要登錄網站數據的方法詳解
- 在Python3中使用asyncio庫進行快速數據抓取的教程
- Python抓取京東圖書評論數據
- 使用Python抓取豆瓣影評數據的方法
