目錄
- 1.爬蟲文件
- 2.items.py
- 3.pipelines.py
- 4.進行持久化存儲
之前我們使用lxml對梨視頻網(wǎng)站中的視頻進行了下載,感興趣的朋友點擊查看吧。
下面我用scrapy框架對梨視頻網(wǎng)站中的視頻標題和視頻頁中對視頻的描述進行爬取

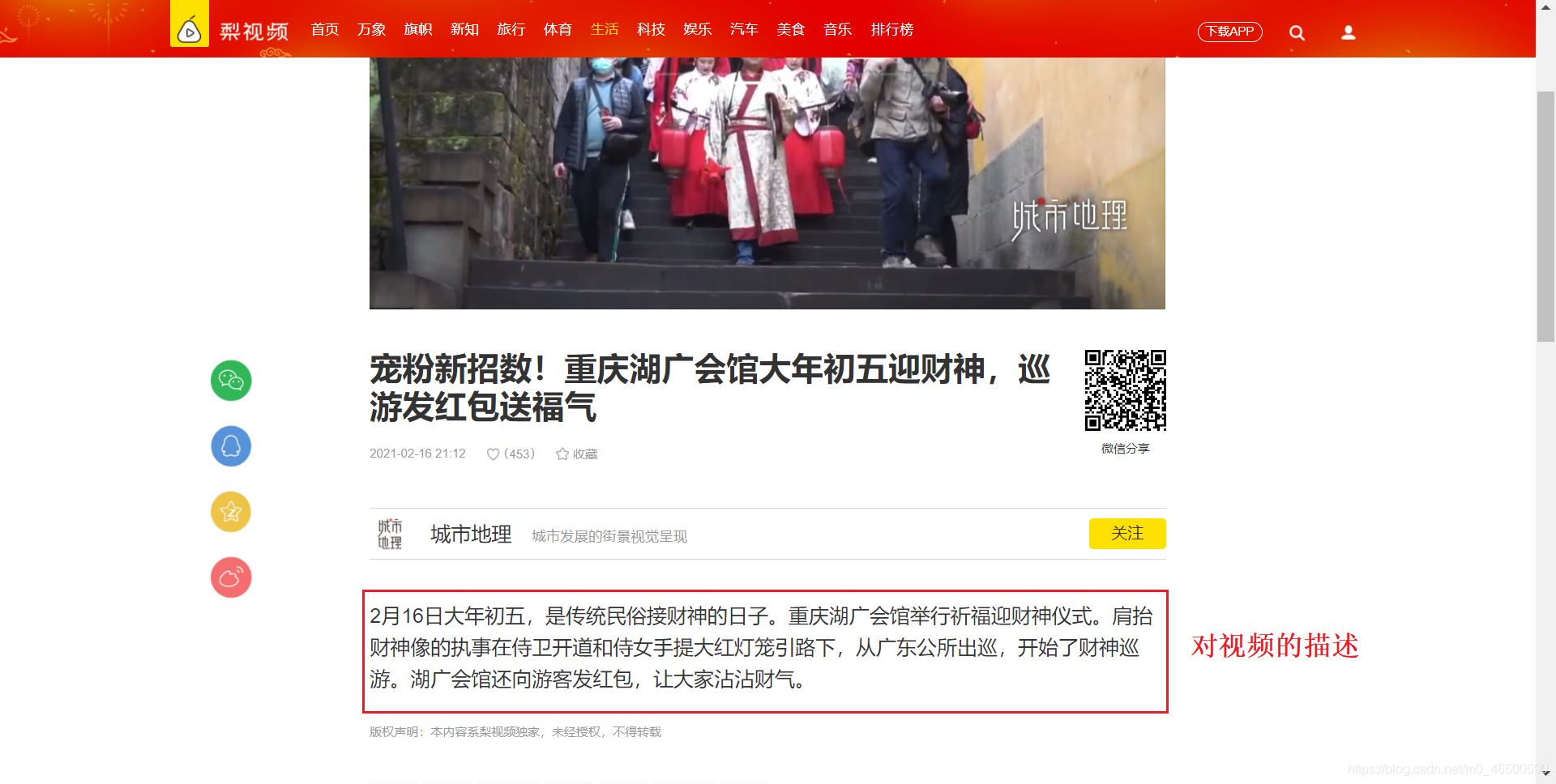
分析:我們要爬取的內(nèi)容并不在同一個頁面,視頻描述內(nèi)容需要我們點開視頻,跳轉到新的url中才能獲取,我們就不能在一個方法中去解析我們需要的不同內(nèi)容
1.爬蟲文件
- 這里我們可以仿照爬蟲文件中的parse方法,寫一個新的parse方法,可以將新的url的響應對象傳給這個新的parse方法
- 如果需要在不同的parse方法中使用同一個item對象,可以使用meta參數(shù)字典,將item傳給callback回調函數(shù)
- 爬蟲文件中的parse需要yield的Request請求,而item則在新的parse方法中使用yield item傳給下一個parse方法或管道文件
import scrapy
# 從items.py文件中導入BossprojectItem類
from bossProject.items import BossprojectItem
class BossSpider(scrapy.Spider):
name = 'boss'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.pearvideo.com/category_5']
# 回調函數(shù)接受響應對象,并且接受傳遞過來的meata參數(shù)
def content_parse(self,response):
# meta參數(shù)包含在response響應對象中,調用meta,然后根據(jù)鍵值取出對應的值:item
item = response.meta['item']
# 解析視頻鏈接中的對視頻的描述
des = response.xpath('//div[@class="summary"]/text()').extract()
des = "".join(des)
item['des'] = des
yield item
# 解析首頁視頻的標題以及視頻的鏈接
def parse(self, response):
li_list = response.xpath('//div[@id="listvideoList"]/ul/li')
for li in li_list:
href = li.xpath('./div/a/@href').extract()
+ "".join(href)
title = li.xpath('./div[1]/a/div[2]/text()').extract()
title = "".join(title)
item = BossprojectItem()
item["title"] = title
#手動發(fā)送請求,并將響應對象傳給回調函數(shù)
#請求傳參:meta={},可以將meta字典傳遞給請求對應的回調函數(shù)
yield scrapy.Request(href,callback=self.content_parse,meta={'item':item})
2.items.py
要將BossprojectItem類導入爬蟲文件中才能夠創(chuàng)建item對象
import scrapy
class BossprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 定義了item屬性
title = scrapy.Field()
des = scrapy.Field()
3.pipelines.py
open_spider(self,spider)和close_spider(self,spider)重寫這兩個父類方法,且這兩個方法都只執(zhí)行一次在process_item方法中最好保留return item,因為如果存在多個管道類,return item會自動將item對象傳給優(yōu)先級低于自己的管道類
from itemadapter import ItemAdapter
class BossprojectPipeline:
def __init__(self):
self.fp = None
# 重寫父類方法,只調用一次
def open_spider(self,spider):
print("爬蟲開始")
self.fp = open('./lishipin.txt','w')
# 接受爬蟲文件中yield傳遞來的item對象,將item中的內(nèi)容持久化存儲
def process_item(self, item, spider):
self.fp.write(item['title'] + '\n\t' + item['des'] + '\n')
# 如果有多個管道類,會將item傳遞給下一個管道類
# 管道類的優(yōu)先級取決于settings.py中的ITEM_PIPELINES屬性中對應的值
## ITEM_PIPELINES = {'bossProject.pipelines.BossprojectPipeline': 300,} 鍵值中的值越小優(yōu)先級越高
return item
# 重寫父類方法,只調用一次
def close_spider(self,spider):
self.fp.close()
print("爬蟲結束")
4.進行持久化存儲
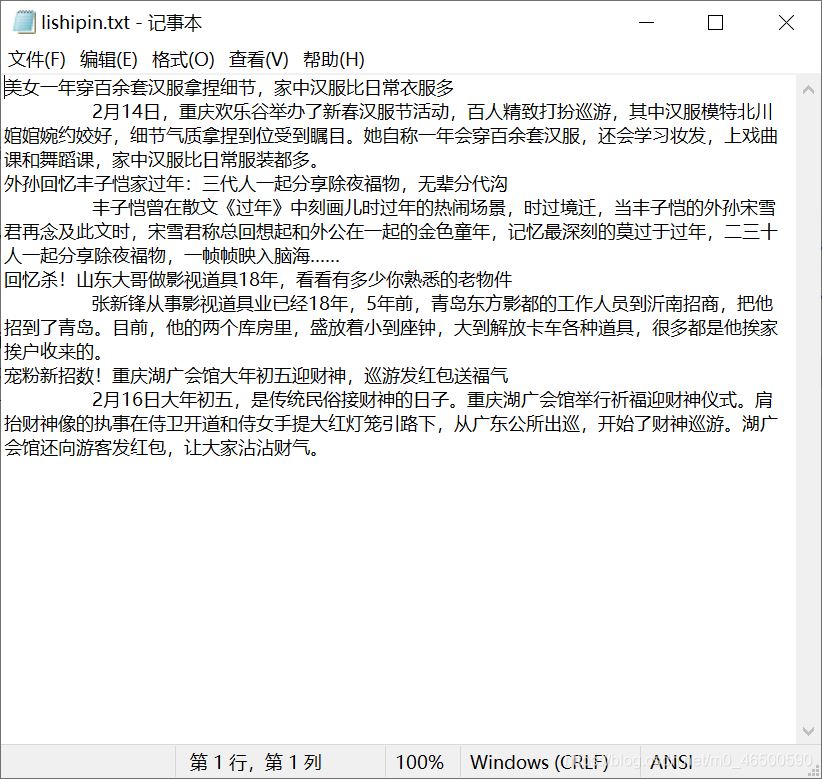
到此這篇關于python爬蟲scrapy框架的梨視頻案例解析的文章就介紹到這了,更多相關python爬蟲scrapy框架內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲基礎講解之scrapy框架
- 簡述python Scrapy框架
- Python Scrapy框架第一個入門程序示例
- Python爬蟲基礎之簡單說一下scrapy的框架結構
