前言:
貓眼票房頁面的字體加密是動態(tài)的,每次或者每天加載頁面的字體文件都會有所變化,本篇內(nèi)容針對這種加密方式進(jìn)行分析
字體加密原理:簡單來說就是程序員在設(shè)計(jì)網(wǎng)站的時(shí)候使用了自己設(shè)計(jì)的字體代碼對關(guān)鍵字進(jìn)行編碼,在瀏覽器加載的時(shí)會根據(jù)這個字體文件對這些字體進(jìn)行編碼,從而顯示出正確的字體。
已知的使用了字體加密的一些網(wǎng)站:
58同城,起點(diǎn),貓眼,大眾點(diǎn)評,啟信寶,天眼查,實(shí)習(xí)僧,汽車之家
本篇內(nèi)容不過多解釋字體文件的映射關(guān)系,不了解的請自行查找其他資料。
如若還未入門爬蟲,請往這走 簡單粗暴入門法——Python爬蟲入門篇
import requests
import urllib.request as down
import json
from fontTools.ttLib import TTFont
import re
#分析用
import matplotlib.pyplot as plt #繪圖
import numpy as np # 科學(xué)計(jì)算庫
安裝:
pip install matplotlib
pip install requests
pip install numpy
pip install fonttools
首先我們對貓眼票房頁面進(jìn)行簡單分析
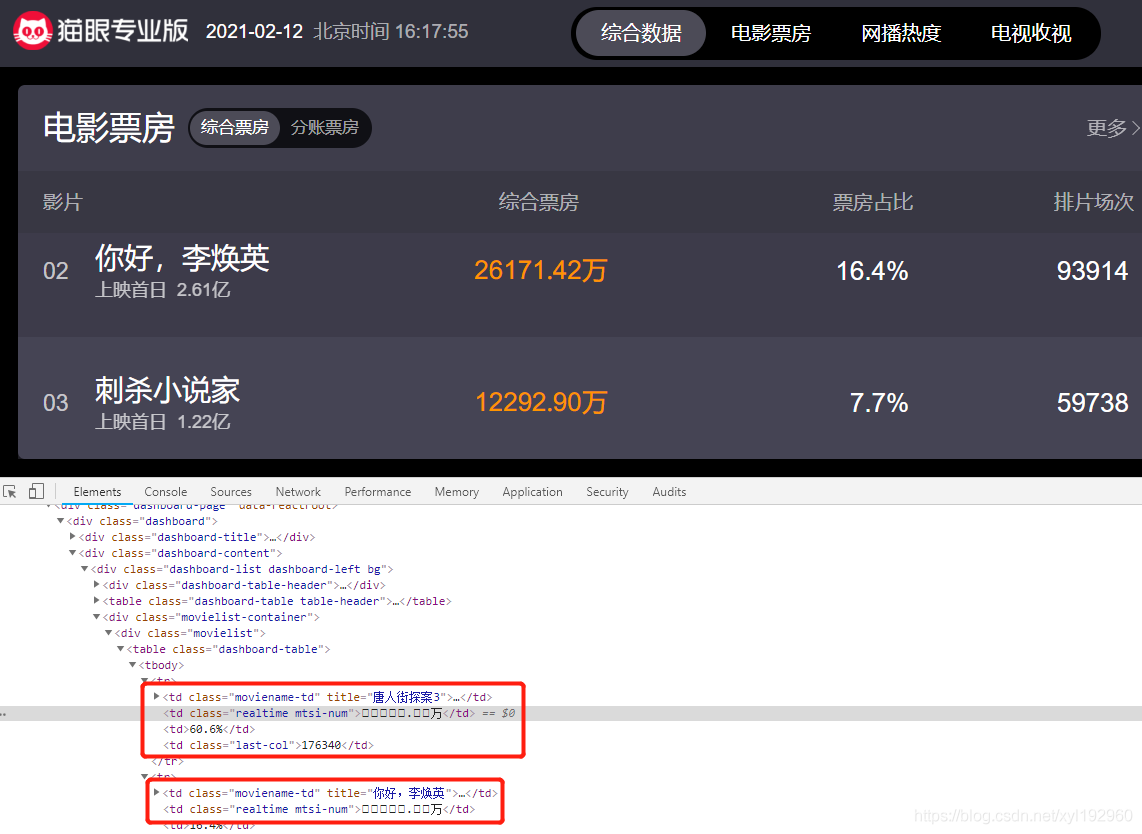
可以看到票房數(shù)字在審查中顯示的是亂碼,類似與這種情況的就可能是使用了字體加密,因此我們需要找到字體文件(字體文件會以鏈接方式存放在頁面中)

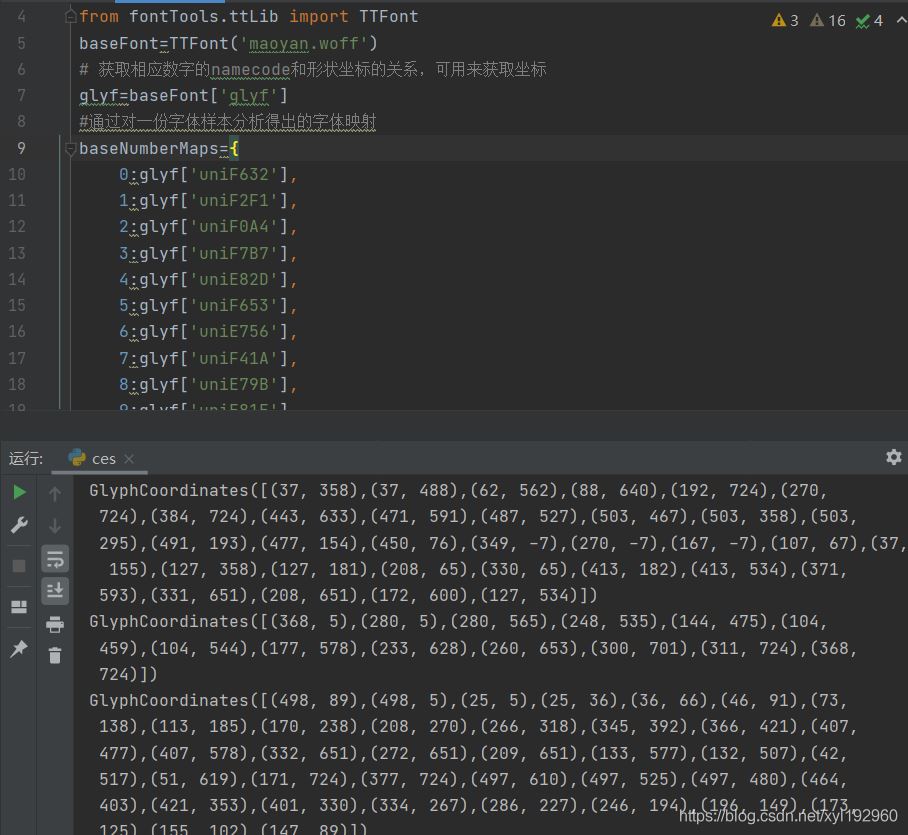
找到了字體文件,下載并對映射關(guān)系進(jìn)行分析,可以得到我們需要的一組基礎(chǔ)字形映射表;并且可以通過映射關(guān)系得到每個字形的所有坐標(biāo)
baseFont=TTFont('maoyan.woff')
# 獲取相應(yīng)數(shù)字的namecode和形狀坐標(biāo)的關(guān)系,可用來獲取坐標(biāo)
glyf=baseFont['glyf']
#通過對一份字體樣本分析得出的字體映射
baseNumberMaps={
0:glyf['uniF632'],
1:glyf['uniF2F1'],
2:glyf['uniF0A4'],
3:glyf['uniF7B7'],
4:glyf['uniE82D'],
5:glyf['uniF653'],
6:glyf['uniE756'],
7:glyf['uniF41A'],
8:glyf['uniE79B'],
9:glyf['uniE81E']
}
for num,name in baseNumberMaps.items():
print(name.coordinates)
我們將坐標(biāo)繪圖成圖形,在進(jìn)行不同組字形圖形對比可以發(fā)現(xiàn)每套字形的坐標(biāo)不同,大小比例不同,而字形是不變的,也就是相似
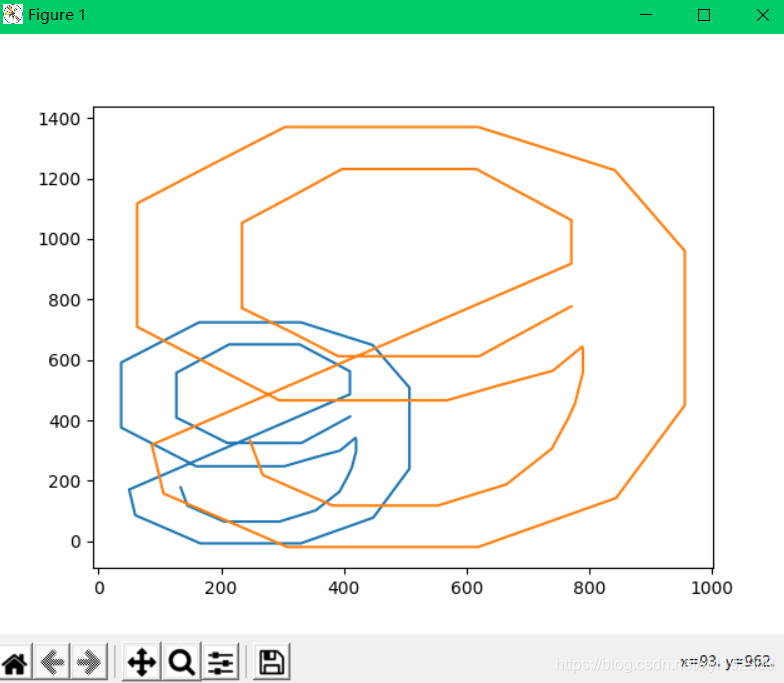
對比坐標(biāo)發(fā)現(xiàn)每套字形坐標(biāo)都會有所改變,但是整體圖形還是同一個,所以我想到了斜率對比,我們計(jì)算每個字形部分線段的斜率,如果斜率之差小于一個數(shù)值,就說明這兩個是相同的數(shù)字。
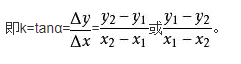
因此就得到了一個思路 獲得基礎(chǔ)字體映射關(guān)系表爬取頁面下載所加載的字體獲得需要對比的字體映射關(guān)系表計(jì)算每套字體每個字形的線段斜率,并進(jìn)行差值計(jì)算循環(huán)匹配,從基礎(chǔ)字形的0-9開始去匹配新字形的斜率,如果斜率之差小于0.5并且樣本數(shù)>=9我們則認(rèn)為兩個圖形為同一個數(shù)字,獲得正確的字體映射關(guān)系對加密字體進(jìn)行替換得到正確內(nèi)容
程序?qū)崿F(xiàn)
import requests
import urllib.request as down
import json
from fontTools.ttLib import TTFont
import re
import MyPyClass
# 得到字體斜率列表(部分)
def font_Kdict(mapstype,maps=None):
'''
得到字體斜率字典(部分)
參數(shù):
mapstype:str->maps類型,判斷是是base/new
maps:映射字典
return kdict
kdict字典關(guān)系:
num:Klist 數(shù)字對應(yīng)每條線段的斜率列表
'''
kdict={}
# 遍歷maps字典,找到對應(yīng)的num和namecode
for num, namecode in maps.items():
# 跳過無用數(shù)據(jù)
if namecode == 'x': continue
# 判斷類型,并從.coordinates得到對應(yīng)num的所有坐標(biāo)
if mapstype=='base':coordinates = namecode.coordinates
elif mapstype=='new':coordinates=glyf[namecode].coordinates
# 得到坐標(biāo) X列表和坐標(biāo) Y列表
x = [i[0] for i in coordinates]
y = [i[1] for i in coordinates]
Klist = []
# 遍歷X列表并切片為前10個數(shù)據(jù)進(jìn)行斜率計(jì)算,即代表繪圖的前10條線段的斜率
for index, absx in enumerate(x[:10]):
# 當(dāng)斜率為0/1時(shí),認(rèn)為斜率為1計(jì)算
if x[index + 1] == x[index] or y[index + 1] == y[index]:
absxy = 1
else:
absxy = (y[index + 1] - y[index]) / (x[index + 1] - x[index])
# 將斜率加入到列表
Klist.append(-absxy if absxy 0 else absxy)
kdict[num]=Klist
#print('base:', code, Klist, name)
return kdict
# 對比斜率字典
def contrast_K(kbase,knew):
'''
對比斜率映射差距
參數(shù):
kbase:基礎(chǔ)字體映射表的斜率字典
knew:當(dāng)前鏈接的字體映射表的斜率字典
return:dict
fontMaps:根據(jù)對比得出正確的字體映射關(guān)系字典
'''
fontMaps = {}
# 遍歷kbase字典
for base in kbase.items():
n = 0 # 成功匹配的斜率個數(shù)
# 遍歷knew字典
for new in knew.items():
# 遍歷kbase>knew>下的兩組斜率,進(jìn)行大小匹配,
# 如果斜率k的差值小于0.5,并且樣本數(shù)>=9時(shí),認(rèn)為兩個坐標(biāo)圖形相識只是大小比例不同
# 即k=0.5 n>=9
for (k1,k2) in zip(base[1],new[1]):
# k取正數(shù)
k=k1-k2 if k1>k2 else k2-k1
if k=0.5:
n+=1
continue
else:
break
if n>=9:
# 匹配正確則添加進(jìn)字典中 此時(shí)的字典關(guān)系是:code:num 代碼對應(yīng)數(shù)字的關(guān)系
fontMaps[str(hex(new[0]).replace('0x','#x'))]=str(base[0])
break
n=0
#print(fontMaps)
return fontMaps
# 建立基礎(chǔ)字體對象
baseFont=TTFont('maoyan.woff')
# 獲取相應(yīng)數(shù)字的namecode和形狀坐標(biāo)的關(guān)系,可用來獲取坐標(biāo)
glyf=baseFont['glyf']
#通過對一份字體樣本分析得出的字體映射
baseNumberMaps={
0:glyf['uniF632'],
1:glyf['uniF2F1'],
2:glyf['uniF0A4'],
3:glyf['uniF7B7'],
4:glyf['uniE82D'],
5:glyf['uniF653'],
6:glyf['uniE756'],
7:glyf['uniF41A'],
8:glyf['uniE79B'],
9:glyf['uniE81E']
}
url='https://piaofang.maoyan.com/dashboard-ajax?orderType=0uuid=1778ad877f8c8-0b23bf32a2bb26-c7d6957-1fa400-1778ad877f8c8riskLevel=71optimusCode=10'
ua=MyPyClass.GetUserAgent()#獲得ua
# 爬取內(nèi)容
with requests.get(url,headers={'user-agent':ua}) as response:
# 獲取存放字典的json字段,并提取字體url
fontStyle=json.loads(response.content)['fontStyle']
fontStyle=re.findall('\"([\s\S]*?)\"',fontStyle[::-1])
fonturl='http:'+fontStyle[0][::-1]# 字體url鏈接
# 將加載的字體下載保存到本地,并對其進(jìn)行分析
down.urlretrieve(fonturl,'newfont.woff')
# 爬取的電影數(shù)據(jù)內(nèi)容
content = json.loads(response.content)['movieList']['data']['list']
# 信息字典
movieNum={}#綜合票房數(shù)字典
movieDayOne= {}#上映首日數(shù)量
movieRate={}#票房占比
movieshowCount={}#排片場次
movieViewerAvg={}#場均人數(shù)
movieInfos={}
# 頁面內(nèi)容
for i in content:
moviename=i['movieInfo']['movieName']
movieNum[moviename]=i['boxSplitUnit']['num']
movieDayOne[moviename]=i['sumBoxDesc']
movieRate[moviename]=i['splitBoxRate']
movieshowCount[moviename]=i['showCount']
movieViewerAvg[moviename]=i['avgShowView']
# 新字體對象
fontnew=TTFont('newfont.woff')
# 得到當(dāng)前字體的映射關(guān)系表
newNumberMaps=fontnew.getBestCmap()
# 獲取字形
glyf=fontnew['glyf']
# 基礎(chǔ)字體斜率字典
k_base_dict=font_Kdict(maps=baseNumberMaps,mapstype='base')
# 新字體斜率字典
k_new_dict=font_Kdict(maps=fontnew.getBestCmap(),mapstype='new')
# 得到字體映射字典
fontcodes=contrast_K(k_base_dict,k_new_dict)
# 對加密的字體遍歷分組,并去除無用字符
for name,numbercode in movieNum.items():
movieNum[name]=re.findall('([\S]*?);', numbercode)
# 根據(jù)得到的fontcodes映射對加密字體進(jìn)行替換,得到正確數(shù)值
for index,(name,numbercodelist) in enumerate(movieNum.items()):
num=[]
# 替換操作
for code in numbercodelist:
if '.' in code:
code=code.replace('.','')
num.append('.'+fontcodes[code])
else:
num.append(fontcodes[code])
infos=['排行:'+str(index+1),
'片名',name,
'上映首日',movieDayOne[name],
'票房',''.join(num)+'萬',
'票房占比',movieRate[name],
'場均人數(shù)',movieViewerAvg[name]+'人',
'排片場次',movieshowCount[name]]
print(infos)
實(shí)現(xiàn)效果如下
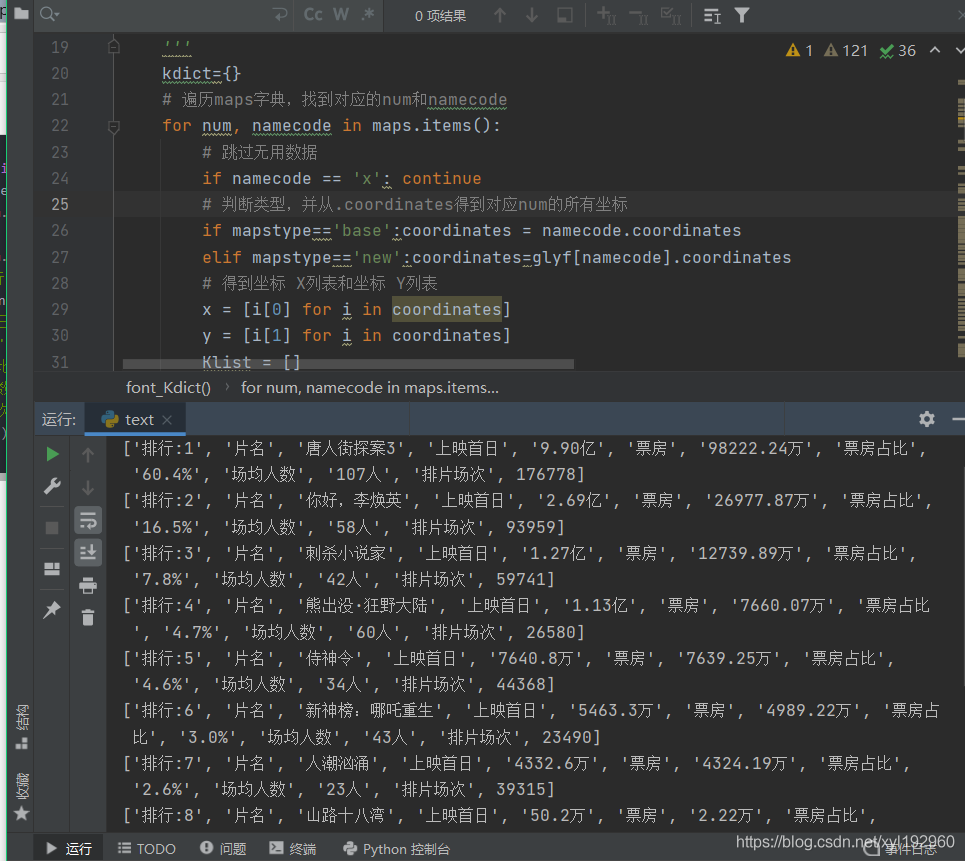
到此這篇關(guān)于Python爬蟲實(shí)例之2021貓眼票房字體加密反爬策略(粗略版)的文章就介紹到這了,更多相關(guān)Python爬蟲貓眼票房字體反爬內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python 逆向爬蟲正確調(diào)用 JAR 加密邏輯
- Python3 使用cookiejar管理cookie的方法
- python調(diào)用java的jar包方法
- Java實(shí)現(xiàn)的執(zhí)行python腳本工具類示例【使用jython.jar】
- Python創(chuàng)建自己的加密貨幣的示例
- python通過cython加密代碼
- python 實(shí)現(xiàn)aes256加密
- Python 正確調(diào)用 jar 包加密得到加密值的操作方法
