為什么要模擬登錄
有些網站是需要登錄之后才能訪問的,即便是同一個網站,在用戶登錄前后頁面所展示的內容也可能會大不相同,例如,未登錄時訪問Github首頁將會是以下的注冊頁面:
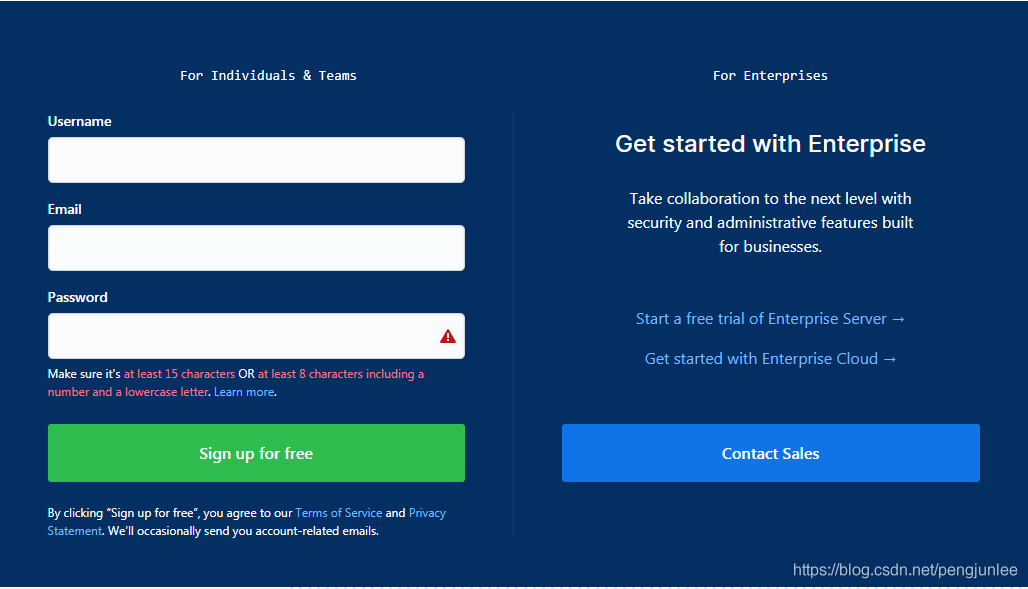
然而,登錄后訪問Github首頁將包含如下頁面內容:
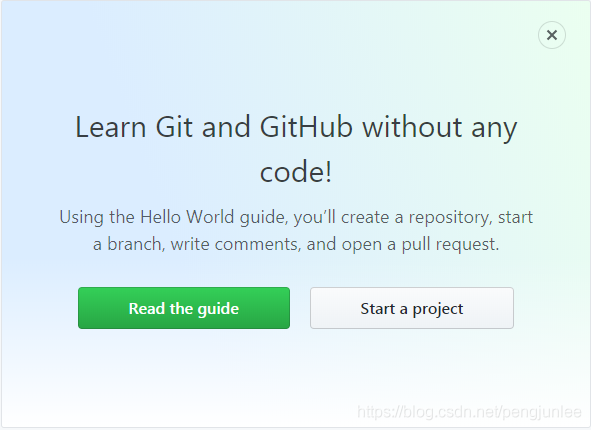
如果我們要爬取的是一些需要登錄之后才能訪問的頁面數據就需要模擬登錄了。通常我們都是利用的 Cookies 來實現模擬登錄,在Scrapy中,模擬登陸網站一般有如下兩種實現方式:
(1) 請求時攜帶Cookies
(2) 發送Post請求獲取Cookies
請求時攜帶Cookies
對于一些Cookies過期時間很長的不規范網站,如果我們能夠在Cookies過期之前爬取到所有我們想要的數據,可以考慮在請求時直接將Cookies信息帶上來模擬用戶登錄。
以下是模擬登錄Github的示例代碼:
# -*- coding: utf-8 -*-
import scrapy
import re
class TmallLoginSpider(scrapy.Spider):
name = 'github_login3'
allowed_domains = ['github.com']
start_urls = ['https://github.com/']
def start_requests(self): # 請求時攜帶Cookies
cookies = '_ga=GA1.2.363045452.1554860671; tz=Asia%2FShanghai; _octo=GH1.1.1405577398.1554860677; _device_id=ee3ff12512668a1f9dc6fb33e388ea20; ignored_unsupported_browser_notice=false; has_recent_activity=1; user_session=5oxrsfsZCor1iJFCgRXXyeAXd8hcmzEUGh70-xHWLjQkT62Q; __Host-user_session_same_site=5oxrsfsZCor1iJFCgRXXyeAXd8hcmzEUGh70-xHWLjQkT62Q; logged_in=yes; dotcom_user=pengjunlee; _gat=1'
cookies = {i.split('=')[0]: i.split('=')[1] for i in cookies.split('; ')}
yield scrapy.Request(self.start_urls[0], cookies=cookies)
def parse(self, response): # 驗證是否請求成功
print(re.findall('Learn Git and GitHub without any code!',response.body.decode()))
執行爬蟲后,后臺部分日志截圖如下:

發送Post請求模擬登錄
Scrapy還提供了兩種通過發送Post請求來獲取Cookies的方法。
scrapy.FormRequest()
使用scrapy.FormRequest()發送Post請求實現模擬登陸,需要人為找出登錄請求的地址以及構造出登錄時所需的請求數據。
使用scrapy.FormRequest()模擬登錄Github的示例代碼:
# -*- coding: utf-8 -*-
import scrapy
import re
class GithubLoginSpider(scrapy.Spider):
name = 'github_login'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response): # 發送Post請求獲取Cookies
authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract_first()
utf8 = response.xpath('//input[@name="utf8"]/@value').extract_first()
commit = response.xpath('//input[@name="commit"]/@value').extract_first()
form_data = {
'login': 'pengjunlee@163.com',
'password': '123456',
'webauthn-support': 'supported',
'authenticity_token': authenticity_token,
'utf8': utf8,
'commit': commit}
yield scrapy.FormRequest("https://github.com/session", formdata=form_data, callback=self.after_login)
def after_login(self, response): # 驗證是否請求成功
print(re.findall('Learn Git and GitHub without any code!', response.body.decode()))
從后臺日志不難看出,Scrapy 在請求完 https://github.com/session 后,自動幫我們重定向到了Github首頁。

scrapy.FormRequest.from_response()
scrapy.FormRequest.from_response()使用起來比 scrapy.FormRequest()更加簡單方便,我們通常只需要提供用戶相關信息(賬戶和密碼)即可,scrapy.FormRequest.from_response()將通過模擬點擊為我們填充好其他的表單字段并提交表單。
使用scrapy.FormRequest.from_response()模擬登錄Github的示例代碼:
# -*- coding: utf-8 -*-
import scrapy
import re
class GithubLogin2Spider(scrapy.Spider):
name = 'github_login2'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response): # 發送Post請求獲取Cookies
form_data = {
'login': 'pengjunlee@163.com',
'password': '123456'
}
yield scrapy.FormRequest.from_response(response,formdata=form_data,callback=self.after_login)
def after_login(self,response): # 驗證是否請求成功
print(re.findall('Learn Git and GitHub without any code!',response.body.decode()))
scrapy.FormRequest.from_response()方法還可以傳入其他參數來幫我們更加精確的指定表單元素:
'''
response (Response object) – 包含表單HTML的響應,將用來對表單的字段進行預填充
formname (string) – 如果設置了該值,name 等于該值的表單將被使用
formid (string) – 如果設置了該值,id 等于該值的表單將被使用
formxpath (string) – 如果設置了該值,匹配該 xpath 的第一個表單將被使用
formcss (string) – 如果設置了該值,匹配該 css選擇器的第一個表單將被使用
formnumber (integer) – 索引值等于該值的表單將被使用,默認第一個(索引值為 0 )
formdata (dict) – 傳入的表單數據,將覆蓋form 元素中已經存在的值
clickdata (dict) – 用于查找可點擊控件的屬性值
dont_click (boolean) – 如果設置為 True,將不點擊任何元素,直接提交表單數據
'''
參考文章
https://doc.scrapy.org/en/latest/topics/request-response.html
到此這篇關于Scrapy實現模擬登錄的示例代碼的文章就介紹到這了,更多相關Scrapy 模擬登錄內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python基于scrapy爬取京東筆記本電腦數據并進行簡單處理和分析
- Scrapy元素選擇器Xpath用法匯總
- Django結合使用Scrapy爬取數據入庫的方法示例
- python實現Scrapy爬取網易新聞
- python爬蟲scrapy框架之增量式爬蟲的示例代碼
- 一文讀懂python Scrapy爬蟲框架
- Python爬蟲之教你利用Scrapy爬取圖片
