本次案例以爬取起小點(diǎn)小說(shuō)為例
案例目的:
通過(guò)爬取起小點(diǎn)小說(shuō)月票榜的名稱(chēng)和月票數(shù),介紹如何破解字體加密的反爬,將加密的數(shù)據(jù)轉(zhuǎn)化成明文數(shù)據(jù)。
程序功能:
輸入要爬取的頁(yè)數(shù),得到每一頁(yè)對(duì)應(yīng)的小說(shuō)名稱(chēng)和月票數(shù)。
案例分析: 找到目標(biāo)的url:
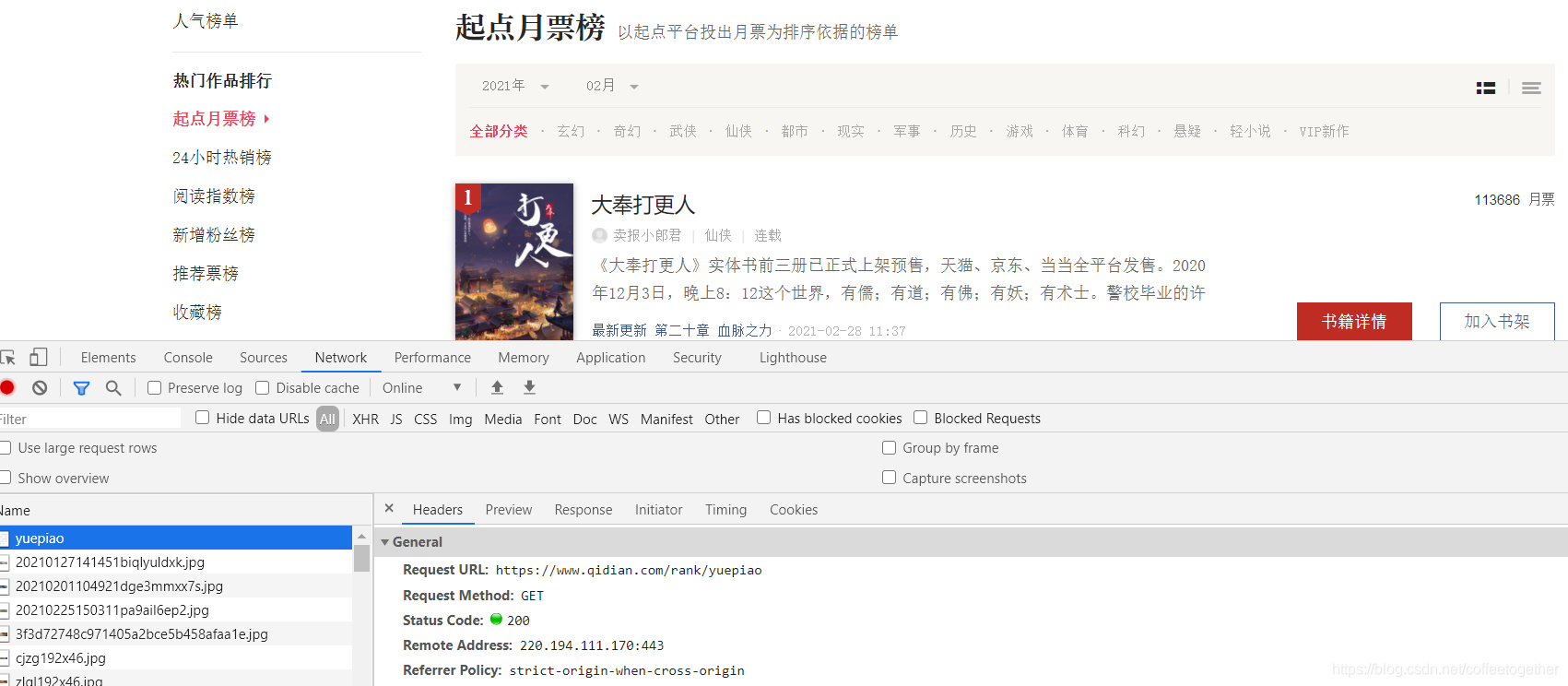
(右鍵檢查)找到小說(shuō)名稱(chēng)所在的位置:
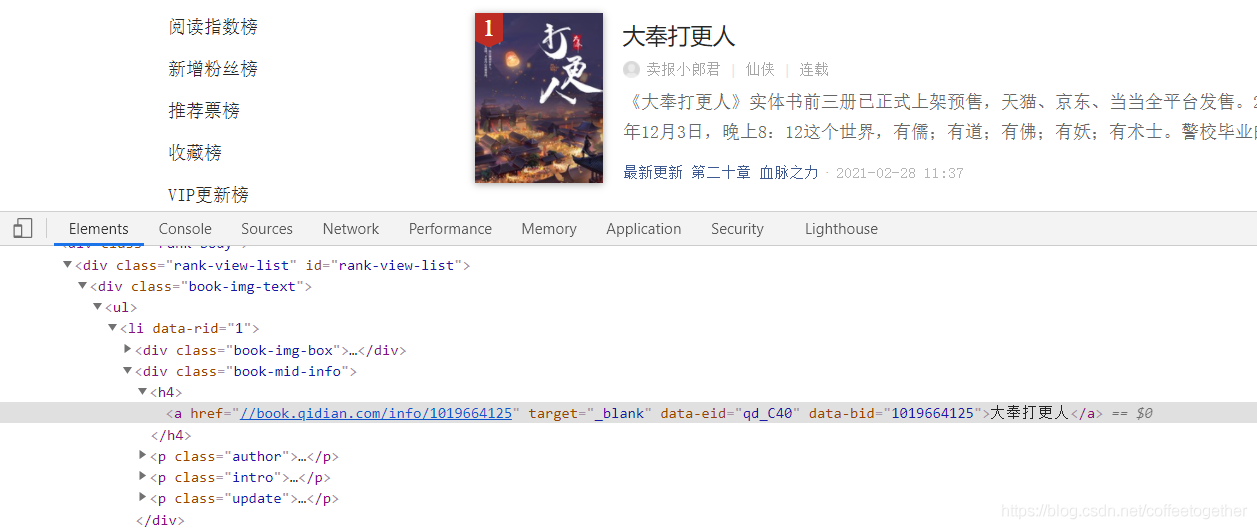
通過(guò)名稱(chēng)所在的節(jié)點(diǎn)位置,找到小說(shuō)名稱(chēng)的xpath語(yǔ)法:
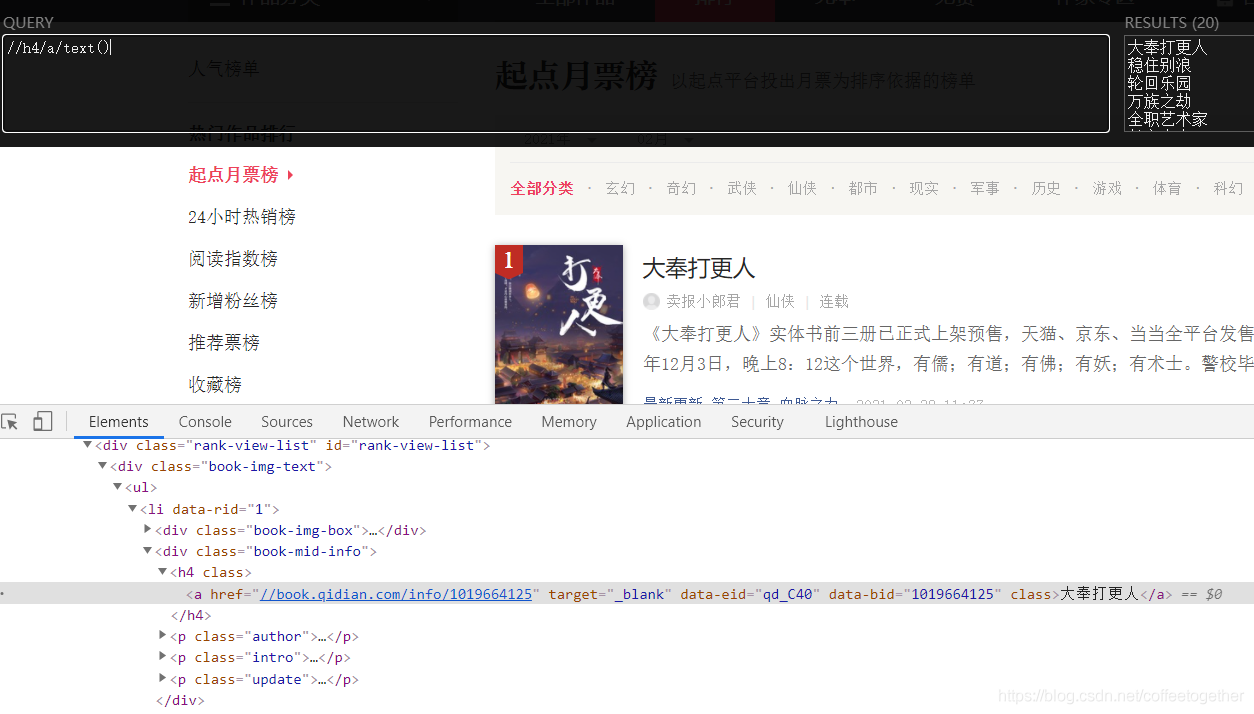
(右鍵檢查)找到月票數(shù)所在的位置:

由上圖發(fā)現(xiàn),檢查月票數(shù)據(jù)的文本,得到一串加密數(shù)據(jù)。
我們通過(guò)xpathhelper進(jìn)行調(diào)試發(fā)現(xiàn),無(wú)法找到加密數(shù)據(jù)的語(yǔ)法。因此,需要通過(guò)正則表達(dá)式進(jìn)行提取。
通過(guò)正則進(jìn)行數(shù)據(jù)提取。

正則表達(dá)式如下:

得到的加密數(shù)據(jù)如下:

破解加密數(shù)據(jù)是本次案例的關(guān)鍵:
既然是加密數(shù)據(jù),就會(huì)有加密數(shù)據(jù)所對(duì)應(yīng)的加密規(guī)則的Font文件。
通過(guò)找到Font字體文件中數(shù)據(jù)加密文件的url,發(fā)送請(qǐng)求,獲取響應(yīng),得到加密數(shù)據(jù)的woff文件。
注:我們需要的woff文件,名稱(chēng)與加密月票數(shù)前面的class屬性相同。
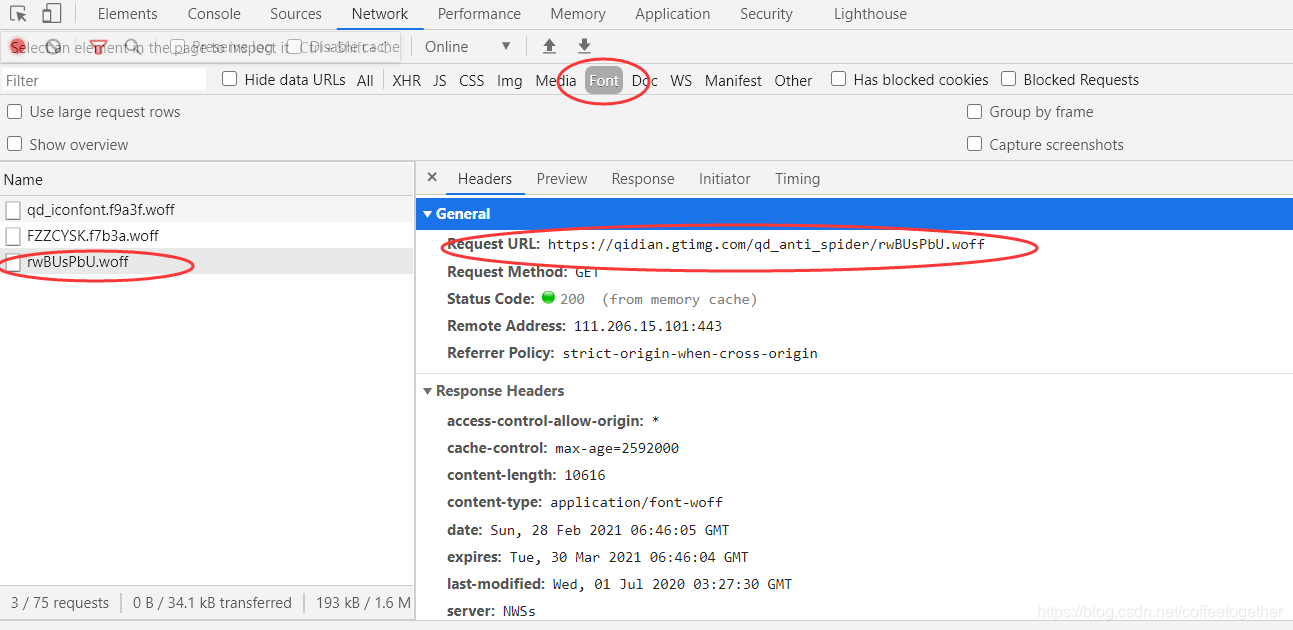
如下圖,下載woff文件:
找到16進(jìn)制的數(shù)字對(duì)應(yīng)的英文數(shù)字。
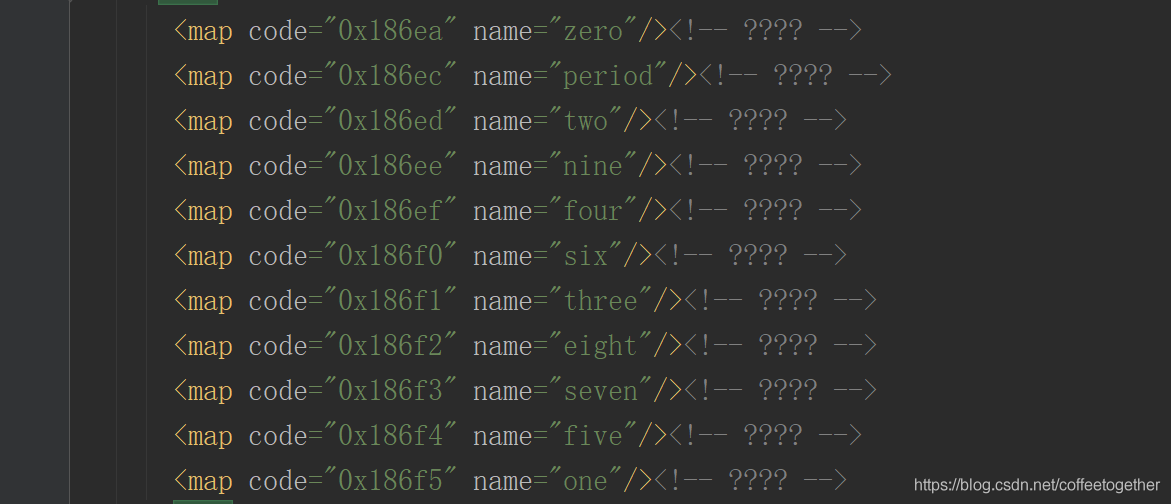
其次,我們需要通過(guò)第三方庫(kù)TTFont將文件中的16進(jìn)制數(shù)轉(zhuǎn)換成10進(jìn)制,將英文數(shù)字轉(zhuǎn)換成阿拉伯?dāng)?shù)字。如下圖:

解析出每個(gè)加密數(shù)據(jù)對(duì)應(yīng)的對(duì)應(yīng)的月票數(shù)的數(shù)字如下:

注意:
由于我們?cè)谏厦嫱ㄟ^(guò)正則表式獲得的加密數(shù)據(jù)攜帶特殊符號(hào)
因此解析出月票數(shù)據(jù)中的數(shù)字之后,除了將特殊符號(hào)去除,還需把每個(gè)數(shù)字進(jìn)行拼接,得到最后的票數(shù)。
最后,通過(guò)對(duì)比不同頁(yè)的url,找到翻頁(yè)的規(guī)律:



對(duì)比三個(gè)不同url發(fā)現(xiàn),翻頁(yè)的規(guī)律在于參數(shù)page
所以問(wèn)題分析完畢,開(kāi)始代碼:
import requests
from lxml import etree
import re
from fontTools.ttLib import TTFont
import json
if __name__ == '__main__':
# 輸入爬取的頁(yè)數(shù)、
pages = int(input('請(qǐng)輸入要爬取的頁(yè)數(shù):')) # eg:pages=1,2
for i in range(pages): # i=0,(0,1)
page = i+1 # 1,(1,2)
# 確認(rèn)目標(biāo)的url
url_ = f'https://www.qidian.com/rank/yuepiao?page={page}'
# 構(gòu)造請(qǐng)求頭參數(shù)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
# 發(fā)送請(qǐng)求,獲取響應(yīng)
response_ = requests.get(url_,headers=headers)
# 響應(yīng)類(lèi)型為html問(wèn)文本
str_data = response_.text
# 將html文本轉(zhuǎn)換成python文件
py_data = etree.HTML(str_data)
# 提取文本中的目標(biāo)數(shù)據(jù)
title_list = py_data.xpath('//h4/a[@target="_blank"]/text() ')
# 提取月票數(shù),由于利用xpath語(yǔ)法無(wú)法提取,因此換用正則表達(dá)式,正則提取的目標(biāo)為response_.text
mon_list = re.findall('/style>span class=".*?">(.*?)/span>/span>',str_data)
print(mon_list)
# 獲取字體反爬woff文件對(duì)應(yīng)的url,xpath配合正則使用
fonturl_str = py_data.xpath('//p/span/style/text()')
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)",str_data)[0]
print(font_url)
# 獲得url之后,構(gòu)造請(qǐng)求頭獲取響應(yīng)
headers_ = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Referer':'https://www.qidian.com/'
}
# 發(fā)送請(qǐng)求,獲取響應(yīng)
font_response = requests.get(font_url,headers=headers_)
# 文件類(lèi)型未知,因此用使用content格式
font_data = font_response.content
# 保存到本地
with open('加密font文件.woff','wb')as f:
f.write(font_data)
# 解析加密的font文件
font_obj = TTFont('加密font文件.woff')
# 將文件轉(zhuǎn)成明文的xml文件
font_obj.saveXML('加密font文件.xml')
# 獲取字體加密的關(guān)系映射表,將16進(jìn)制轉(zhuǎn)換成10進(jìn)制
cmap_list = font_obj.getBestCmap()
print('字體加密關(guān)系映射表:',cmap_list)
# 創(chuàng)建英文轉(zhuǎn)英文的字典
dict_e_a = {'one':'1','two':'2','three':'3','four':'4','five':'5','six':'6',
'seven':'7','eight':'8','nine':'9','zero':'0'}
# 將英文數(shù)據(jù)進(jìn)行轉(zhuǎn)換
for i in cmap_list:
for j in dict_e_a:
if j == cmap_list[i]:
cmap_list[i] = dict_e_a[j]
print('轉(zhuǎn)換為阿拉伯?dāng)?shù)字的映射表為:',cmap_list)
# 去掉加密的月票數(shù)據(jù)列表中的符號(hào)
new_mon_list = []
for i in mon_list:
list_ = re.findall(r'\d+',i)
new_mon_list.append(list_)
print('去掉符號(hào)之后的月票數(shù)據(jù)列表為:',new_mon_list)
# 最終解析月票數(shù)據(jù)
for i in new_mon_list:
for j in enumerate(i):
for k in cmap_list:
if j[1] == str(k):
i[j[0]] = cmap_list[k]
print('解析之后的月票數(shù)據(jù)為:',new_mon_list)
# 將月票數(shù)據(jù)進(jìn)行拼接
new_list = []
for i in new_mon_list:
j = ''.join(i)
new_list.append(j)
print('解析出的明文數(shù)據(jù)為:',new_list)
# 將名稱(chēng)和對(duì)應(yīng)的月票數(shù)據(jù)放進(jìn)字典,并轉(zhuǎn)換成json格式及進(jìn)行保存
for i in range(len(title_list)):
dict_ = {}
dict_[title_list[i]] = new_list[i]
# 將字典轉(zhuǎn)換成json格式
json_data = json.dumps(dict_,ensure_ascii=False)+',\n'
# 將數(shù)據(jù)保存到本地
with open('翻頁(yè)起小點(diǎn)月票榜數(shù)據(jù)爬取.json','a',encoding='utf-8')as f:
f.write(json_data)
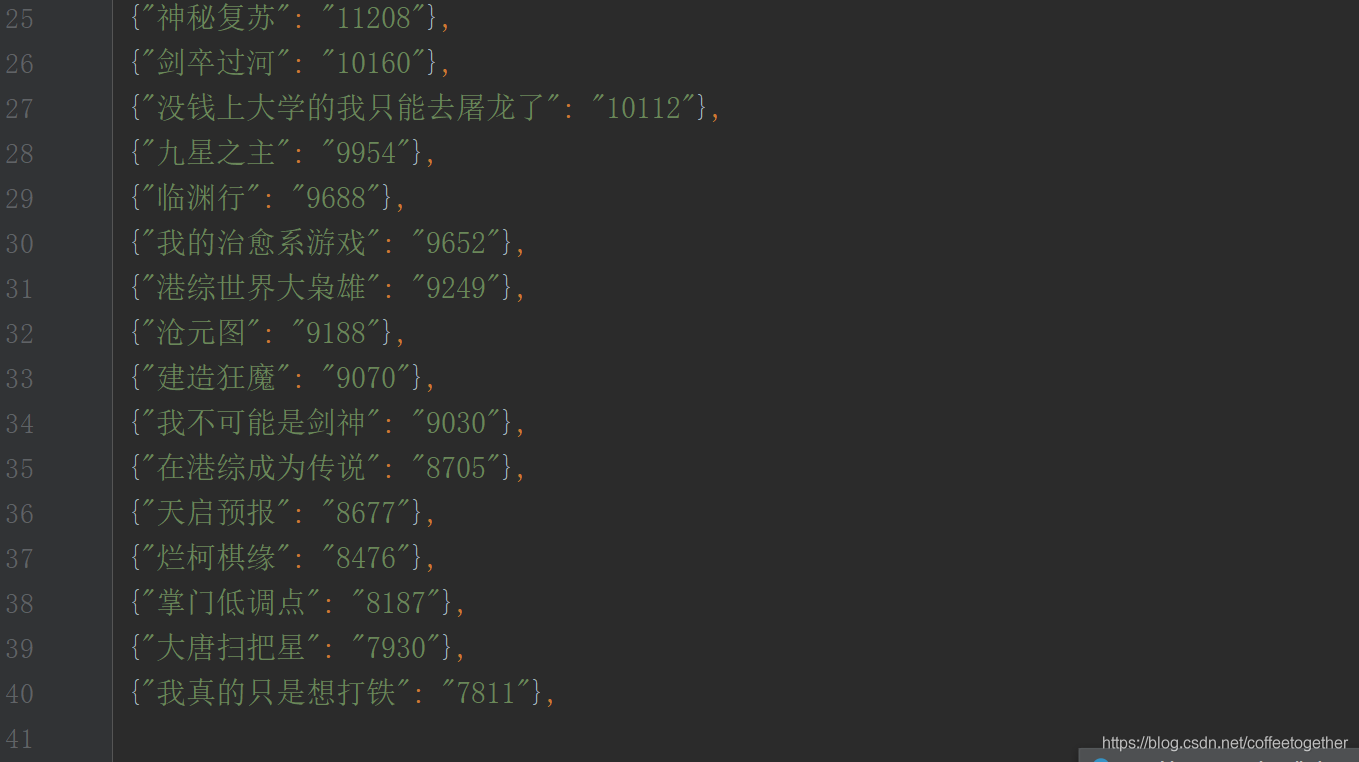
爬取了兩頁(yè)的數(shù)據(jù),每一頁(yè)包含20個(gè)數(shù)據(jù)
執(zhí)行結(jié)果如下:
到此這篇關(guān)于python爬蟲(chóng)破解字體加密案例詳解的文章就介紹到這了,更多相關(guān)python爬蟲(chóng)破解字體加密內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- scrapy在python爬蟲(chóng)中搭建出錯(cuò)的解決方法
- scrapy-redis分布式爬蟲(chóng)的搭建過(guò)程(理論篇)
- Python爬蟲(chóng)代理池搭建的方法步驟
- windows下搭建python scrapy爬蟲(chóng)框架步驟
- windows7 32、64位下python爬蟲(chóng)框架scrapy環(huán)境的搭建方法
- 使用Docker Swarm搭建分布式爬蟲(chóng)集群的方法示例
- 快速一鍵生成Python爬蟲(chóng)請(qǐng)求頭
- 一文讀懂python Scrapy爬蟲(chóng)框架
- 快速搭建python爬蟲(chóng)管理平臺(tái)
