偶然從pytorch討論論壇中看到的一個問題,KL divergence different results from tf,kl divergence 在TensorFlow中和pytorch中計算結果不同,平時沒有注意到,記錄下
一篇關于KL散度、JS散度以及交叉熵對比的文章
kl divergence 介紹
KL散度( Kullback–Leibler divergence),又稱相對熵,是描述兩個概率分布 P 和 Q 差異的一種方法。計算公式:
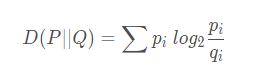
可以發現,P 和 Q 中元素的個數不用相等,只需要兩個分布中的離散元素一致。
舉個簡單例子:
兩個離散分布分布分別為 P 和 Q
P 的分布為:{1,1,2,2,3}
Q 的分布為:{1,1,1,1,1,2,3,3,3,3}
我們發現,雖然兩個分布中元素個數不相同,P 的元素個數為 5,Q 的元素個數為 10。但里面的元素都有 “1”,“2”,“3” 這三個元素。
當 x = 1時,在 P 分布中,“1” 這個元素的個數為 2,故 P(x = 1) = 2/5 = 0.4,在 Q 分布中,“1” 這個元素的個數為 5,故 Q(x = 1) = 5/10 = 0.5
同理,
當 x = 2 時,P(x = 2) = 2/5 = 0.4 ,Q(x = 2) = 1/10 = 0.1
當 x = 3 時,P(x = 3) = 1/5 = 0.2 ,Q(x = 3) = 4/10 = 0.4
把上述概率帶入公式:
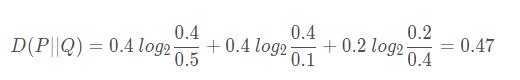
至此,就計算完成了兩個離散變量分布的KL散度。
pytorch 中的 kl_div 函數
pytorch中有用于計算kl散度的函數 kl_div
torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean')

計算 D (p||q)
1、不用這個函數的計算結果為:

與手算結果相同
2、使用函數:
(這是計算正確的,結果有差異是因為pytorch這個函數中默認的是以e為底)

注意:
1、函數中的 p q 位置相反(也就是想要計算D(p||q),要寫成kl_div(q.log(),p)的形式),而且q要先取 log
2、reduction 是選擇對各部分結果做什么操作,默認為取平均數,這里選擇求和
好別扭的用法,不知道為啥官方把它設計成這樣
補充:pytorch 的KL divergence的實現
看代碼吧~
import torch.nn.functional as F
# p_logit: [batch, class_num]
# q_logit: [batch, class_num]
def kl_categorical(p_logit, q_logit):
p = F.softmax(p_logit, dim=-1)
_kl = torch.sum(p * (F.log_softmax(p_logit, dim=-1)
- F.log_softmax(q_logit, dim=-1)), 1)
return torch.mean(_kl)
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- pytorch 實現計算 kl散度 F.kl_div()
- 淺談pytorch 模型 .pt, .pth, .pkl的區別及模型保存方式
- Pytorch 計算誤判率,計算準確率,計算召回率的例子
