目錄
- 一、什么是進(jìn)程
- 二、什么是線程
- 三、并發(fā)、并行
- 四、多線程適用場景
- 五、Python GIL
- 六、Python多線程、多進(jìn)程實(shí)例:CPU 密集型任務(wù)
- 6.1 單線程
- 6.2 多線程
- 6.3 多進(jìn)程
- 七、Python多線程、多進(jìn)程實(shí)例:IO密集型任務(wù)
- 7.1 單線程
- 7.2 多線程
- 7.3 多進(jìn)程
- 7.4 協(xié)程
- 八、總結(jié)
一、什么是進(jìn)程
- 進(jìn)程是執(zhí)行中的程序,是資源分配的最小單位:操作系統(tǒng)以進(jìn)程為單位分配存儲空間,進(jìn)程擁有獨(dú)立地址空間、內(nèi)存、數(shù)據(jù)棧等
- 操作系統(tǒng)管理所有進(jìn)程的執(zhí)行,分配資源
- 可以通過fork或 spawn的方式派生新進(jìn)程,新進(jìn)程也有自己獨(dú)立的內(nèi)存空間
- 進(jìn)程間通信方式(IPC,Inter-Process Communication)共享信息,實(shí)現(xiàn)數(shù)據(jù)共享,包括管道、信號、套接字、共享內(nèi)存區(qū)等。
二、什么是線程
- 線程是CPU調(diào)度的的最小單位
- 一個進(jìn)程可以有多個線程
- 同進(jìn)程下執(zhí)行,并共享相同的上下文
- 線程間的信息共享和通信更加容易
- 多線程并發(fā)執(zhí)行
- 需要同步原語
三、并發(fā)、并行

并發(fā)通常應(yīng)用于 I/O 操作頻繁的場景,并行則更多應(yīng)用于 CPU heavy 的場景。
3.1 并發(fā)
并發(fā)(concurrency),指同一時刻只能有一條指令執(zhí)行,多個線程的對應(yīng)的指令被快速輪換地執(zhí)行,線程/任務(wù)之間會互相切換。
- 處理器先執(zhí)行線程 A 的指令一段時間,再執(zhí)行線程 B 的指令一段時間,再切回到線程 A,快速輪換地執(zhí)行。
- 處理器切換過程中會進(jìn)行上下文的切換操作,進(jìn)行多個線程之間切換和執(zhí)行,這個切換過程非常快,使得在宏觀上看起來多個線程在同時運(yùn)行。
- 每個線程的執(zhí)行會占用這個處理器一個時間片段,同一時刻,其實(shí)只有一個線程在執(zhí)行。
3.2 并行
并行(parallel) 指同一時刻,有多條指令在多個處理器上同時執(zhí)行
- 不論是從宏觀上還是微觀上,多個線程都是在同一時刻一起執(zhí)行的。
- 并行只能在多處理器系統(tǒng)中存在,如果只有一個核就不可能實(shí)現(xiàn)并行。并發(fā)在單處理器和多處理器系統(tǒng)中都是可以存在的,一個核就可以實(shí)現(xiàn)并發(fā)。
注意:具體是并發(fā)還是并行取決于操作系統(tǒng)的調(diào)度。
四、多線程適用場景
多線程/多進(jìn)程是解決并發(fā)問題的經(jīng)典模型之一。
在一個程序進(jìn)程中,有一些操作是比較耗時或者需要等待的,比如等待數(shù)據(jù)庫的查詢結(jié)果的返回,等待網(wǎng)頁結(jié)果的響應(yīng)。這個線程在等待的過程中,處理器是可以執(zhí)行其他的操作的,從而從整體上提高執(zhí)行效率。
比如網(wǎng)絡(luò)爬蟲,在向服務(wù)器發(fā)起請求之后,有一段時間必須要等待服務(wù)器的響應(yīng)返回,這種任務(wù)屬于 IO 密集型任務(wù)。對于這種任務(wù),啟用多線程可以在某個線程等待的過程中去處理其他的任務(wù),從而提高整體的爬取效率。
還有一種任務(wù)叫作計算密集型任務(wù),或者稱為CPU 密集型任務(wù)。任務(wù)的運(yùn)行一直需要處理器的參與。如果使用多線程,一個處理器從一個計算密集型任務(wù)切換到另一個計算密集型任務(wù),處理器依然不會停下來,并不會節(jié)省總體的時間,如果線程數(shù)目過多,進(jìn)程上下文切換會占用大量的資源,整體效率會變低。
所以,如果任務(wù)不全是計算密集型任務(wù),我們可以使用多線程來提高程序整體的執(zhí)行效率。尤其對于網(wǎng)絡(luò)爬蟲這種 IO 密集型任務(wù)來說,使用多線程會大大提高程序整體的爬取效率,多線程只適合IO 密集型任務(wù)。
五、Python GIL
由于 Python 中 GIL 的限制,導(dǎo)致不論是在單核還是多核條件下,在同一時刻只能運(yùn)行一個線程,導(dǎo)致 Python 多線程無法發(fā)揮多核并行的優(yōu)勢。
GIL 全稱為 Global Interpreter Lock(全局解釋器鎖),是 Python 解釋器 CPython 中的一個技術(shù)術(shù)語,是Python之父為了數(shù)據(jù)安全而設(shè)計的。
CPython 使用引用計數(shù)來管理內(nèi)存,所有 Python 腳本中創(chuàng)建的實(shí)例,都會有一個引用計數(shù),來記錄有多少個指針指向它。當(dāng)引用計數(shù)只有 0 時,則會自動釋放內(nèi)存。每隔一段時間,Python 解釋器就會強(qiáng)制當(dāng)前線程去釋放 GIL,Python 3 以后版本的間隔時間是 15 毫秒。
在 Python 多線程下,每個線程輪流執(zhí)行:
- 獲取 GIL
- 執(zhí)行對應(yīng)線程的代碼
- 釋放 GIL
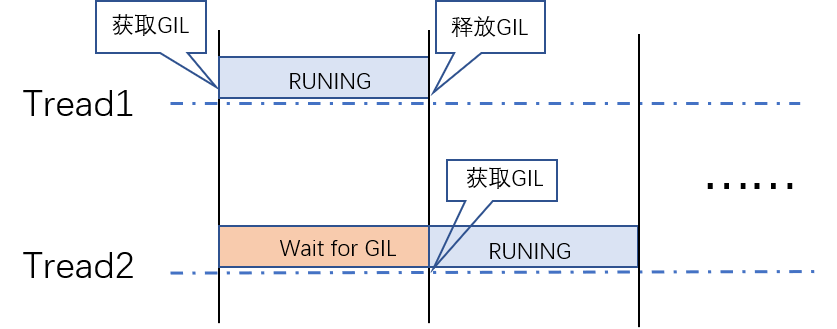
某個線程想要執(zhí)行,必須先拿到 GIL,并且在一個 Python 進(jìn)程中,GIL 只有一個,導(dǎo)致即使在多核的條件下,同一時刻也只能執(zhí)行一個線程。每一個線程執(zhí)行完一段后,會釋放 GIL,以允許別的線程開始利用資源。
六、Python多線程、多進(jìn)程實(shí)例:CPU 密集型任務(wù)
6.1 單線程
執(zhí)行一個CPU 密集型任務(wù):
import time
import os
def cpu_bound_task(n):
print('當(dāng)前進(jìn)程: {}'.format(os.getpid()))
while n > 0:
n -= 1
if __name__ == "__main__":
print('主進(jìn)程: {}'.format(os.getpid()))
start = time.time()
for i in range(2):
cpu_bound_task(100000000)
end = time.time()
print(f"耗時{end - start}秒")
輸出:
主進(jìn)程: 10104
當(dāng)前進(jìn)程: 10104
當(dāng)前進(jìn)程: 10104
耗時10.829032897949219秒
6.2 多線程
import os
import threading
import time
def cpu_bound_task(n,i):
print(f'子線程 {threading.current_thread().name}:{os.getpid()} - 任務(wù){(diào)i}')
while n > 0:
n -= 1
if __name__=='__main__':
start = time.time()
print(f'主線程: {os.getpid()}')
thread_list = []
for i in range(1, 3):
t = threading.Thread(target=cpu_bound_task, args=(100000000,i))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
end = time.time()
print(f"耗時{end - start}秒")
- start():啟動線程
- join():等待子線程結(jié)束后主程序才退出,便于計算所有進(jìn)程執(zhí)行時間。
輸出:
主線程: 1196
子線程 Thread-1:1196 - 任務(wù)1
子線程 Thread-2:1196 - 任務(wù)2
耗時10.808091640472412秒
可以發(fā)現(xiàn)多線程對CPU 密集型任務(wù)性能沒有提升效果。
6.3 多進(jìn)程
from multiprocessing import Process
import os
import time
def cpu_bound_task(n,i):
print(f'子進(jìn)程: {os.getpid()} - 任務(wù){(diào)i}')
while n > 0:
n -= 1
if __name__=='__main__':
print(f'父進(jìn)程: {os.getpid()}')
start = time.time()
p1 = Process(target=cpu_bound_task, args=(100000000,1))
p2 = Process(target=cpu_bound_task, args=(100000000,2))
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print(f"耗時{end - start}秒")
輸出:
父進(jìn)程: 22636
子進(jìn)程: 18072 - 任務(wù)1
子進(jìn)程: 9580 - 任務(wù)2
耗時6.264241933822632秒
也可以使用Pool類創(chuàng)建多進(jìn)程
from multiprocessing import Pool, cpu_count
import os
import time
def cpu_bound_task(n,i):
print(f'子進(jìn)程: {os.getpid()} - 任務(wù){(diào)i}')
while n > 0:
n -= 1
if __name__=='__main__':
print(f"CPU內(nèi)核數(shù):{cpu_count()}")
print(f'父進(jìn)程: {os.getpid()}')
start = time.time()
p = Pool(4)
for i in range(2):
p.apply_async(cpu_bound_task, args=(100000000,i))
p.close()
p.join()
end = time.time()
print(f"耗時{end - start}秒")
輸出:
CPU內(nèi)核數(shù):8
父進(jìn)程: 18616
子進(jìn)程: 21452 - 任務(wù)0
子進(jìn)程: 16712 - 任務(wù)1
耗時5.928101301193237秒
七、Python多線程、多進(jìn)程實(shí)例:IO密集型任務(wù)
7.1 單線程
IO 密集型任務(wù):
def io_bound_task(self, n, i):
print(f'子進(jìn)程: {os.getpid()} - 任務(wù){(diào)i}')
print(f'IO Task{i} start')
time.sleep(n)
print(f'IO Task{i} end')
if __name__=='__main__':
print('主進(jìn)程: {}'.format(os.getpid()))
start = time.time()
for i in range(2):
self.io_bound_task(4,i)
end = time.time()
print(f"耗時{end - start}秒")
輸出:
主進(jìn)程: 2780
子進(jìn)程: 2780 - 任務(wù)0
IO Task0 start
IO Task0 end
子進(jìn)程: 2780 - 任務(wù)1
IO Task1 start
IO Task1 end
耗時8.04494023323059秒
7.2 多線程
print(f"CPU內(nèi)核數(shù):{cpu_count()}")
print(f'父進(jìn)程: {os.getpid()}')
start = time.time()
p = Pool(2)
for i in range(2):
p.apply_async(io_bound_task, args=(4, i))
p.close()
p.join()
end = time.time()
print(f"耗時{end - start}秒")
輸出:
CPU內(nèi)核數(shù):8
父進(jìn)程: 1396
子進(jìn)程: 2712 - 任務(wù)0
IO Task0 start
子進(jìn)程: 10492 - 任務(wù)1
IO Task1 start
IO Task0 endIO Task1 end
耗時4.201171398162842秒
可以看出對于IO密集型任務(wù),Python多線程具有顯著提升。
7.3 多進(jìn)程
print(f'父進(jìn)程: {os.getpid()}')
start = time.time()
p1 = Process(target=io_bound_task, args=(4, 1))
p2 = Process(target=io_bound_task, args=(4, 2))
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print("耗時{}秒".format((end - start)))
輸出:
父進(jìn)程: 12328
子進(jìn)程: 12452 - 任務(wù)2
IO Task2 start
子進(jìn)程: 16896 - 任務(wù)1
IO Task1 start
IO Task1 endIO Task2
end
耗時4.1241302490234375秒
7.4 協(xié)程
IO型任務(wù)還可以使用協(xié)程,協(xié)程比線程更加輕量級,一個線程可以擁有多個協(xié)程,協(xié)程在用戶態(tài)執(zhí)行,完全由程序控制。一般來說,線程數(shù)量越多,協(xié)程性能的優(yōu)勢越明顯。這里就不介紹Python協(xié)程了,下面Python代碼是協(xié)程的其中一種實(shí)現(xiàn)方式:
import asyncio
import time
async def io_bound_task(self,n,i):
print(f'子進(jìn)程: {os.getpid()} - 任務(wù){(diào)i}')
print(f'IO Task{i} start')
# time.sleep(n)
await asyncio.sleep(n)
print(f'IO Task{i} end')
if __name__ == '__main__':
start = time.time()
loop = asyncio.get_event_loop()
tasks = [io_bound_task(4, i) for i in range(2)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
end = time.time()
print(f"耗時{end - start}秒")
輸出:
子進(jìn)程: 5436 - 任務(wù)1
IO Task1 start
子進(jìn)程: 5436 - 任務(wù)0
IO Task0 start
IO Task1 end
IO Task0 end
耗時4.008626461029053秒
八、總結(jié)
Python 由于GIL鎖的存在,無法利用多進(jìn)程的優(yōu)勢,要真正利用多核,可以重寫一個不帶GIL的解釋器, 比如JPython(Java 實(shí)現(xiàn)的 Python 解釋器)。
某些Python 庫使用C語言實(shí)現(xiàn),例如 NumPy 庫不受 GIL 的影響。在實(shí)際工作中,如果對性能要求很高,可以使用C++ 實(shí)現(xiàn),然后再提供 Python 的調(diào)用接口。另外Java語言也沒有GIL限制。
對于多線程任務(wù),如果線程數(shù)量很多,建議使用Python協(xié)程,執(zhí)行效率比多線程高。
到此這篇關(guān)于Python多線程與多進(jìn)程相關(guān)知識總結(jié)的文章就介紹到這了,更多相關(guān)Python多線程與多進(jìn)程內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python多進(jìn)程的使用詳情
- python實(shí)現(xiàn)多進(jìn)程并發(fā)控制Semaphore與互斥鎖LOCK
- python 多進(jìn)程和多線程使用詳解
- python 實(shí)現(xiàn)多進(jìn)程日志輪轉(zhuǎn)ConcurrentLogHandler
- Python 多進(jìn)程原理及實(shí)現(xiàn)
- python多進(jìn)程基礎(chǔ)詳解
