Python列表和字典
- 前面我們了解了 “大O表示法” 以及對不同的算法的評估,下面來討論下 Python 兩種內置數據類型有關的各種操作的大O數量級:列表 list 和字典dict。
- 這是 Python 中兩種非常重要的數據類型,后面會用來實現各種數據結構,通過運行試驗來估計其各種操作運行時間數量級。
對比 list 和 dict 操作如下:

List列表數據類型常用操作性能:
最常用的是:按索引取值和賦值(v=a[i],a[i]=v),由于列表的隨機訪問特性,這兩個操作執行時間與列表大小無關,均為O(1)。
另一個是列表增長,可以選擇 append() 和 “+”:lst.append(v),執行時間是O(1);lst= lst+ [v],執行時間是O(n+k),其中 k 是被加的列表長度,選擇哪個方法來操作列表,也決定了程序的性能。
測試 4 種生成 n 個整數列表的方法:

創建一個 Timer 對象,指定需要反復運行的語句和只需要運行一次的"安裝語句"。
然后調用這個對象的 timeit 方法,指定反復運行多少次。
# Timer(stmt="pass", setup="pass") # 這邊只介紹兩個參數
# stmt:statement的縮寫,就是要測試的語句,要執行的對象
# setup:導入被執行的對象(就和run代碼前,需要導入包一個道理) 在主程序命名空間中 導入
time1 = Timer("test1()", "from __main__ import test1")
print("concat:{} seconds".format(time1.timeit(1000)))
time2 = Timer("test2()", "from __main__ import test2")
print("append:{} seconds".format(time2.timeit(1000)))
time3 = Timer("test3()", "from __main__ import test3")
print("comprehension:{} seconds".format(time3.timeit(1000)))
time4 = Timer("test4()", "from __main__ import test4")
print("list range:{} seconds".format(time4.timeit(1000))
結果如下:
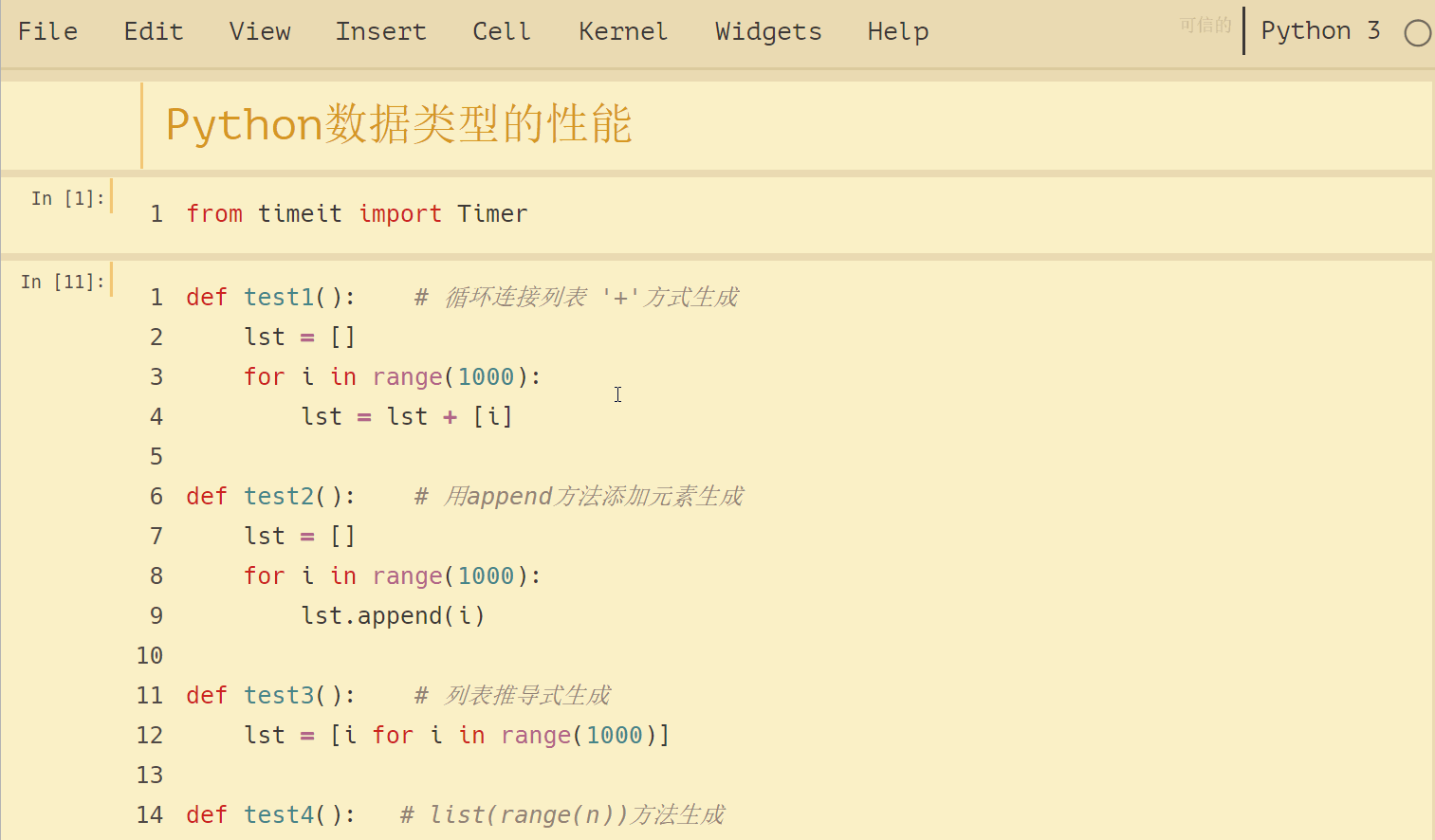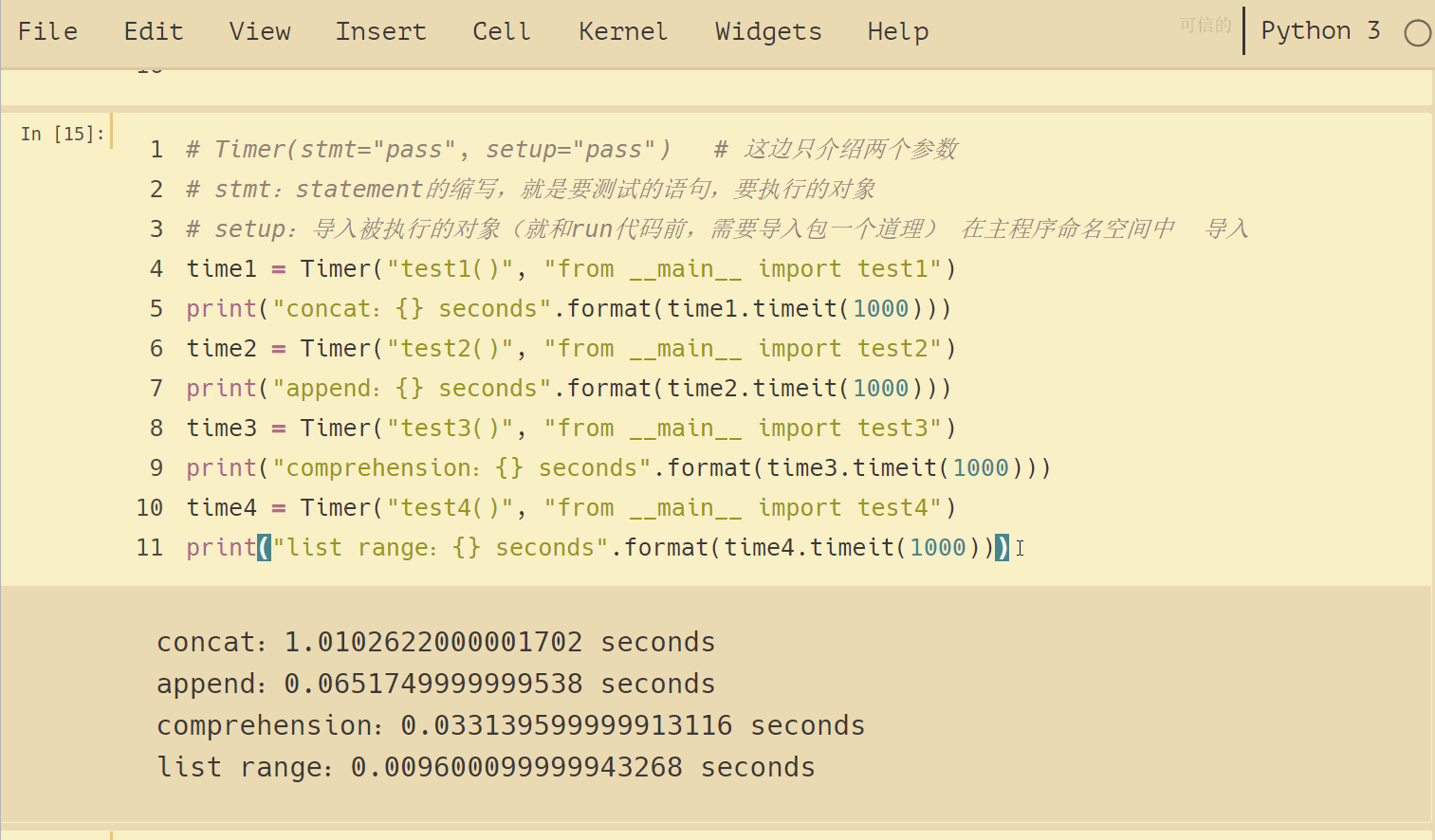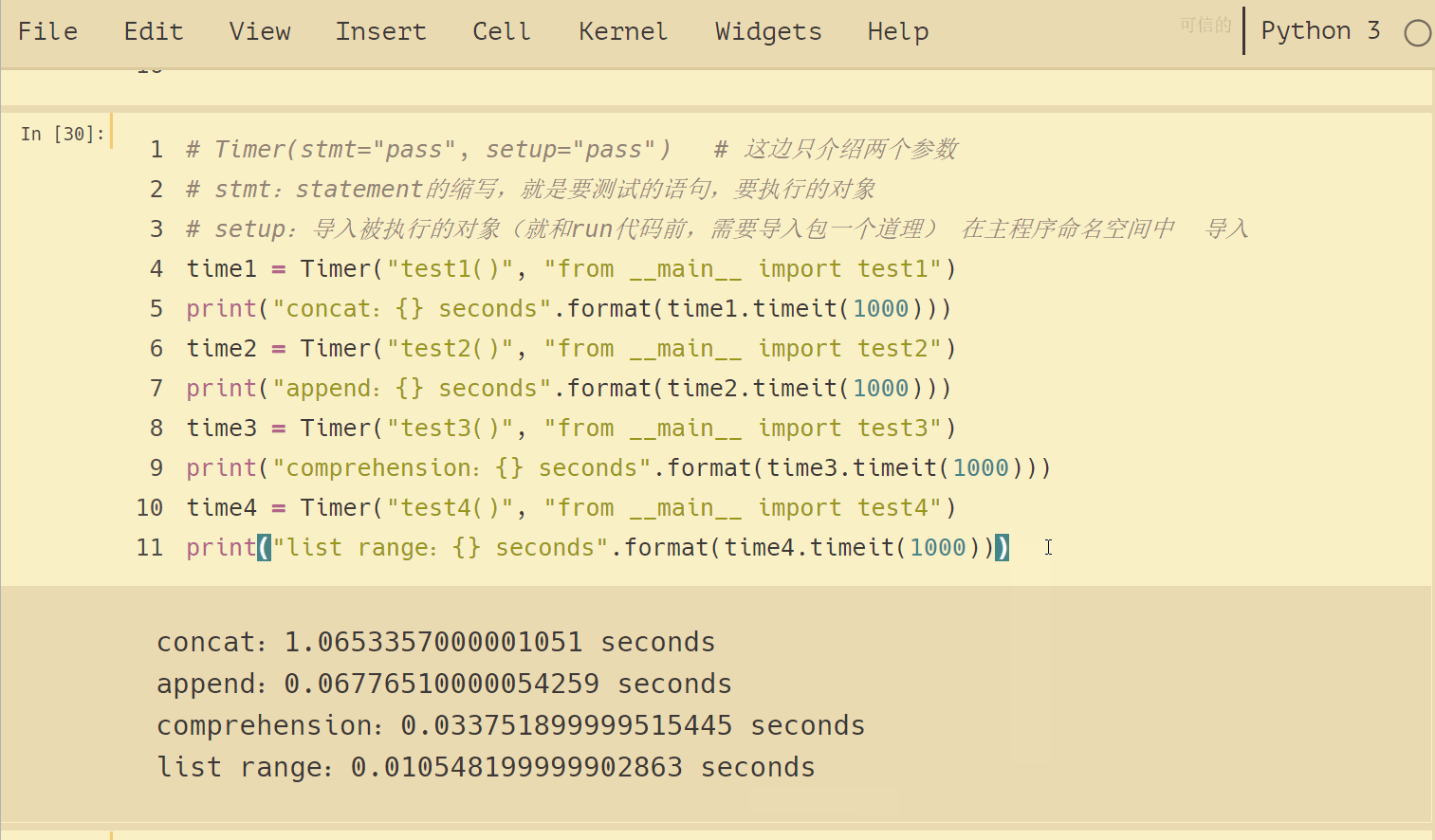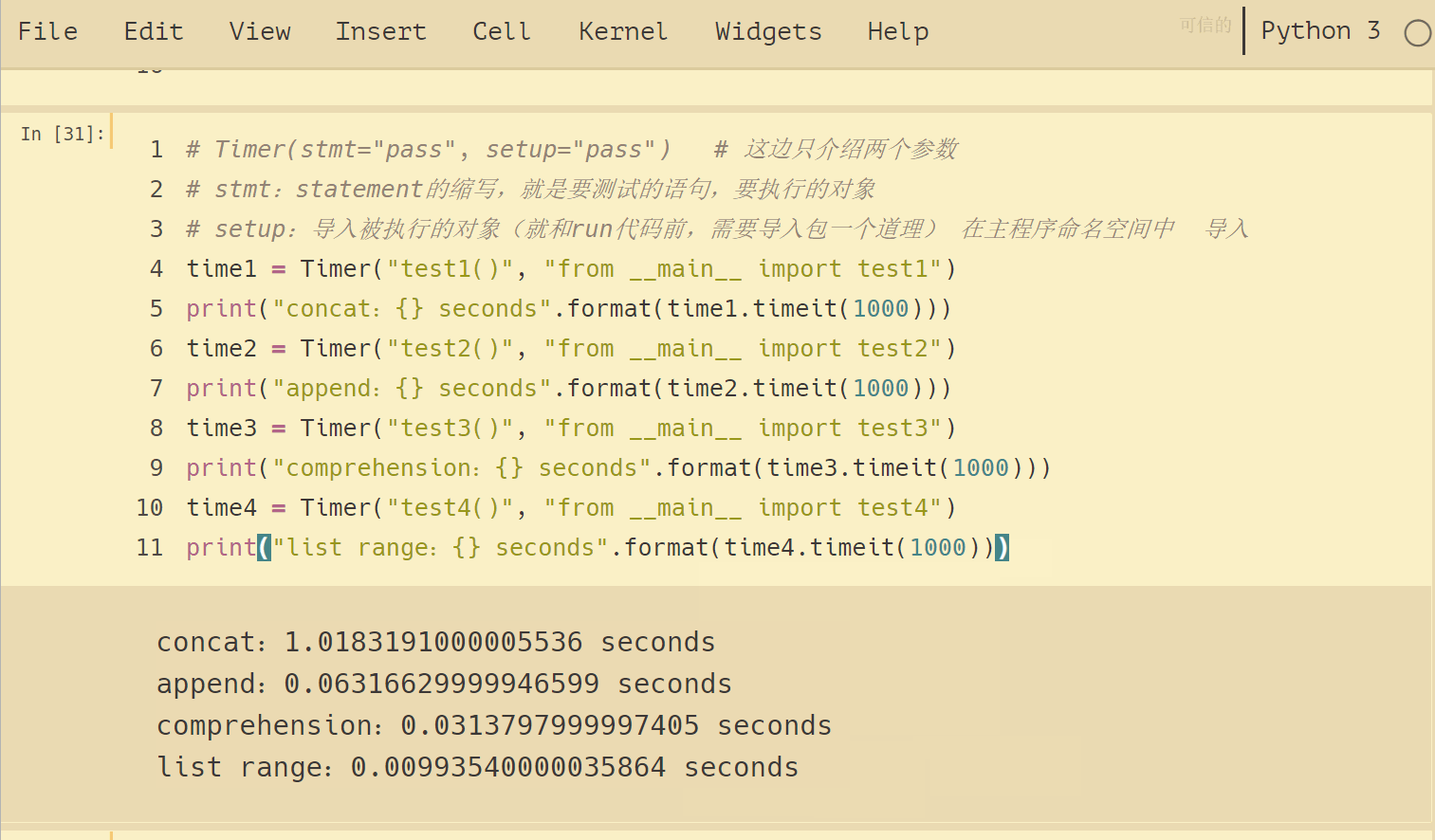
可以看到,4種方法運行時間差別挺大的,列表連接(concat)最慢,List range最快,速度相差近 100 倍。append要比 concat 快得多。另外,我們注意到列表推導式速度大約是 append 兩倍的樣子。
總結列表基本操作的大 O 數量級:
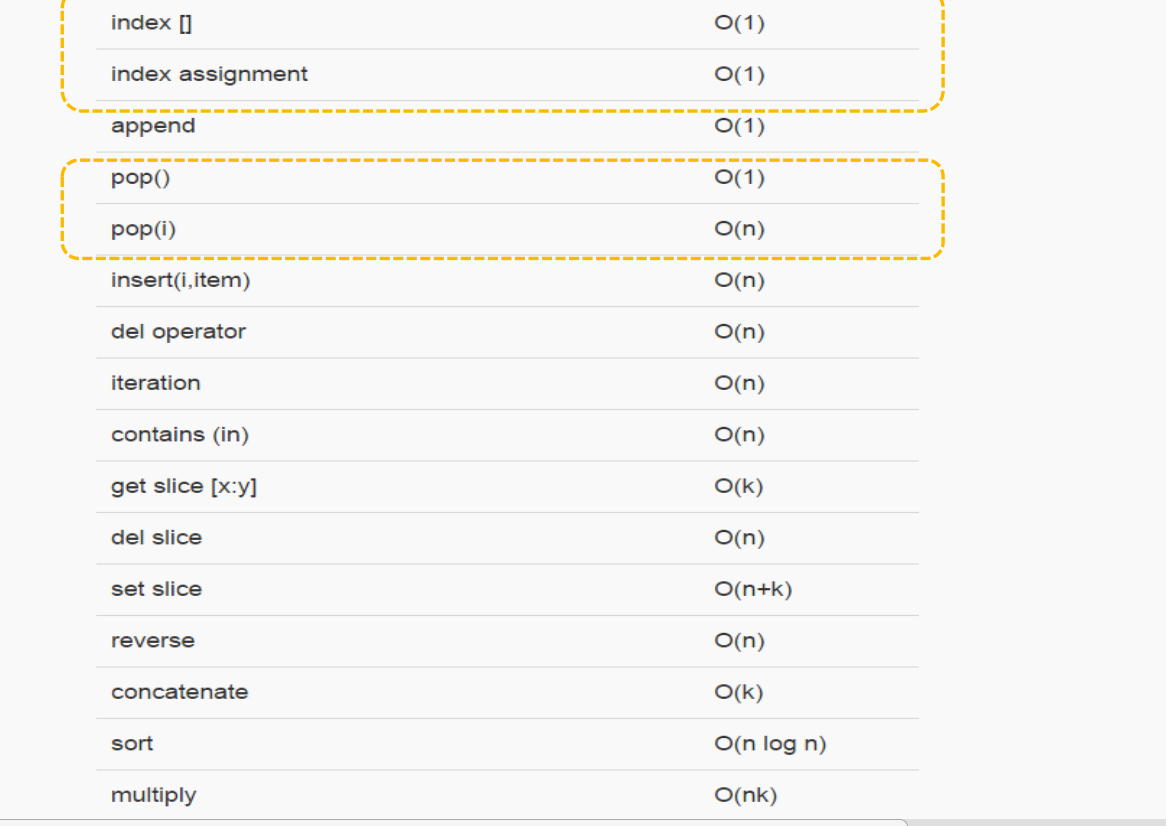
我們注意到 pop 這個操作,pop()是從列表末尾移除元素,時間復雜度為O(1);pop(i)從列表中部移除元素,時間復雜度為O(n)。
原因在于 Python 所選擇的實現方法,從中部移除元素的話,要把移除元素后面的元素,全部向前挪位復制一遍,這個看起來有點笨拙
但這種實現方法能夠保證列表按索引取值和賦值的操作很快,達到O(1)。這也算是一種對常用和不常用操作的折中方案。
list.pop()的計時試驗,通過改變列表的大小來測試兩個操作的增長趨勢:
import timeit
pop_first = timeit.Timer("x.pop(0)", "from __main__ import x")
pop_end = timeit.Timer("x.pop()", "from __main__ import x")
print("pop(0) pop()")
y_1 = []
y_2 = []
for i in range(1000000, 10000001, 1000000):
x = list(range(i))
p_e = pop_end.timeit(number=1000)
x = list(range(i))
p_f = pop_first.timeit(number=1000)
print("{:.6f} {:.6f}".format(p_f, p_e))
y_1.append(p_f)
y_2.append(p_e)
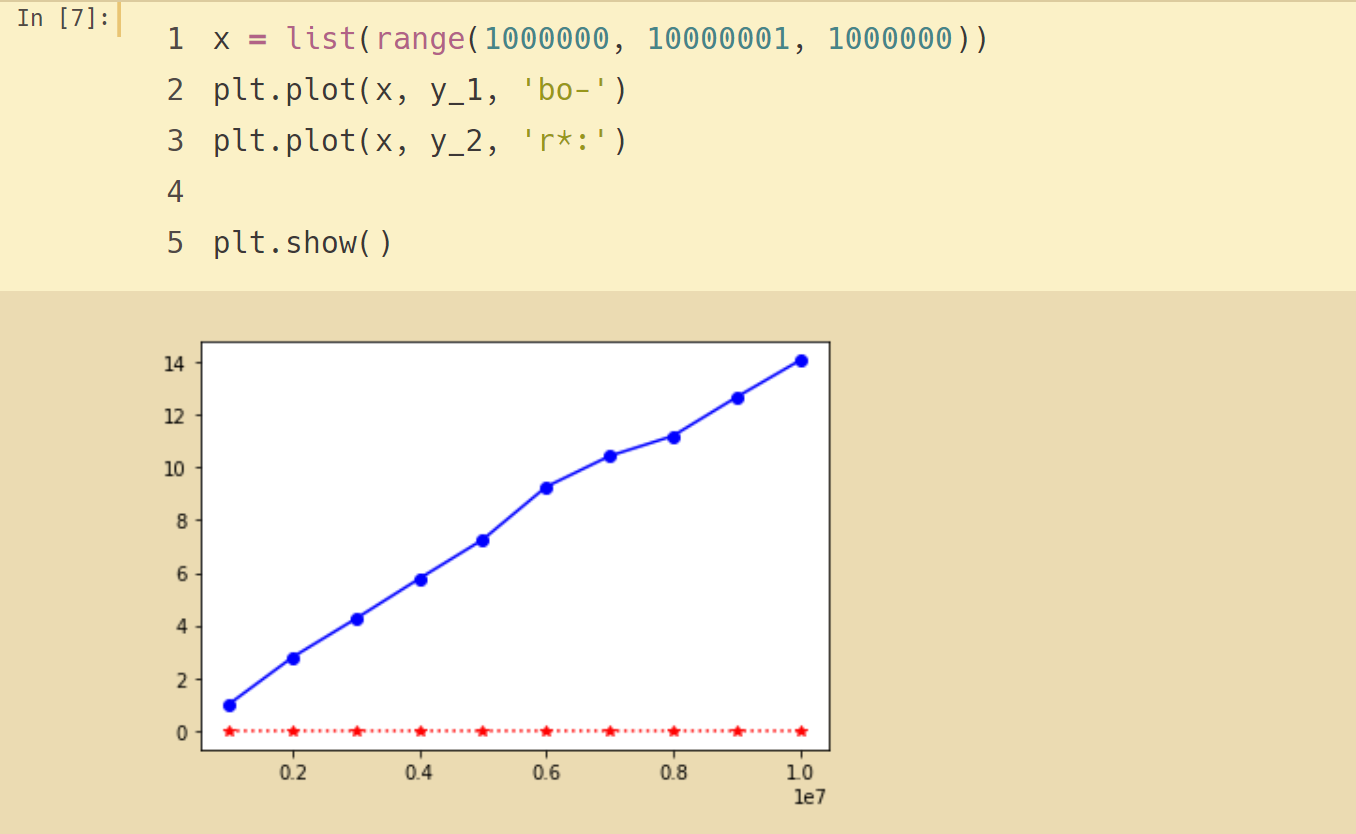
結果如下:

將試驗結果可視化,可以看出增長趨勢:pop()是平坦的常數,pop(0)是線性增長的趨勢。
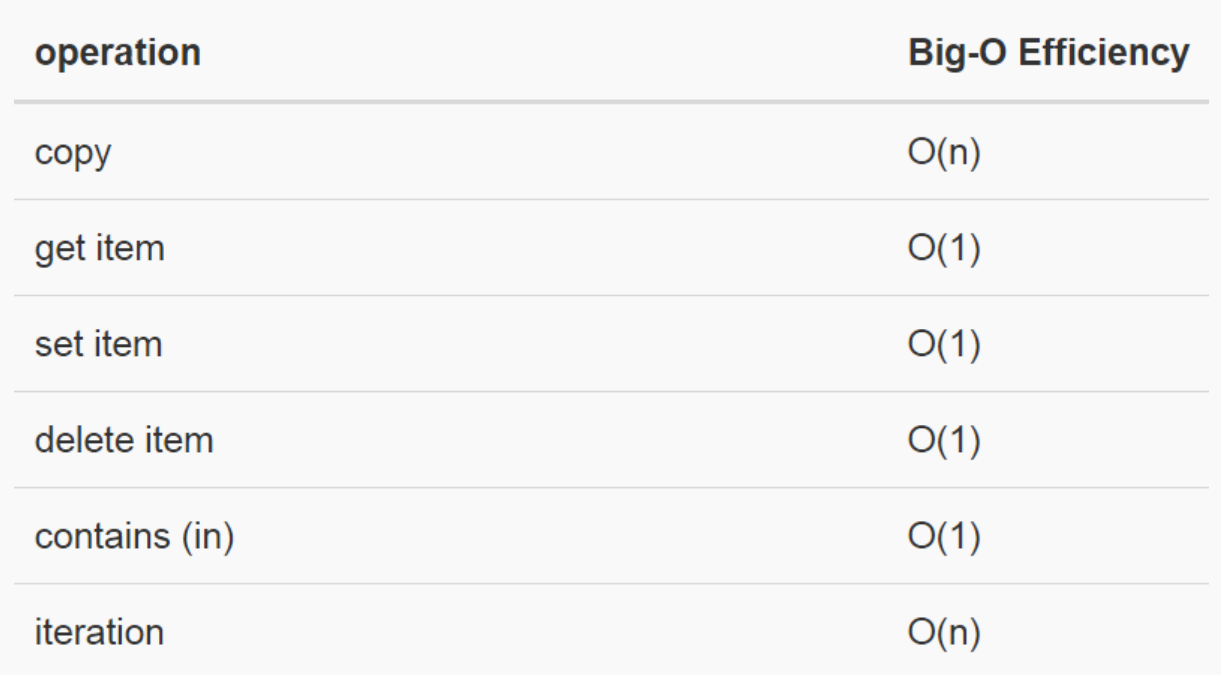
字典與列表不同,是根據鍵值(key)找到數據項,而列表是根據索引(index)。最常用的取值和賦值,其性能均為O(1)。另一個重要操作contains(in)是判斷字典中是否存在某個鍵值(key),這個性能也是O(1)。
做一個性能測試試驗來驗證 list 中檢索一個值,以及 dict 中檢索一個值的用時對比,生成包含連續值的 list 和包含連續鍵值 key 的
dict,用隨機數來檢驗操作符 in 的耗時。
import timeit
import random
y_1 = []
y_2 = []
print("lst_time dict_time")
for i in range(10000, 1000001, 25000):
t = timeit.Timer("random.randrange(%d) in x" % i, "from __main__ import random, x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x = {j: 'k' for j in range(i)}
dict_time = t.timeit(number=1000)
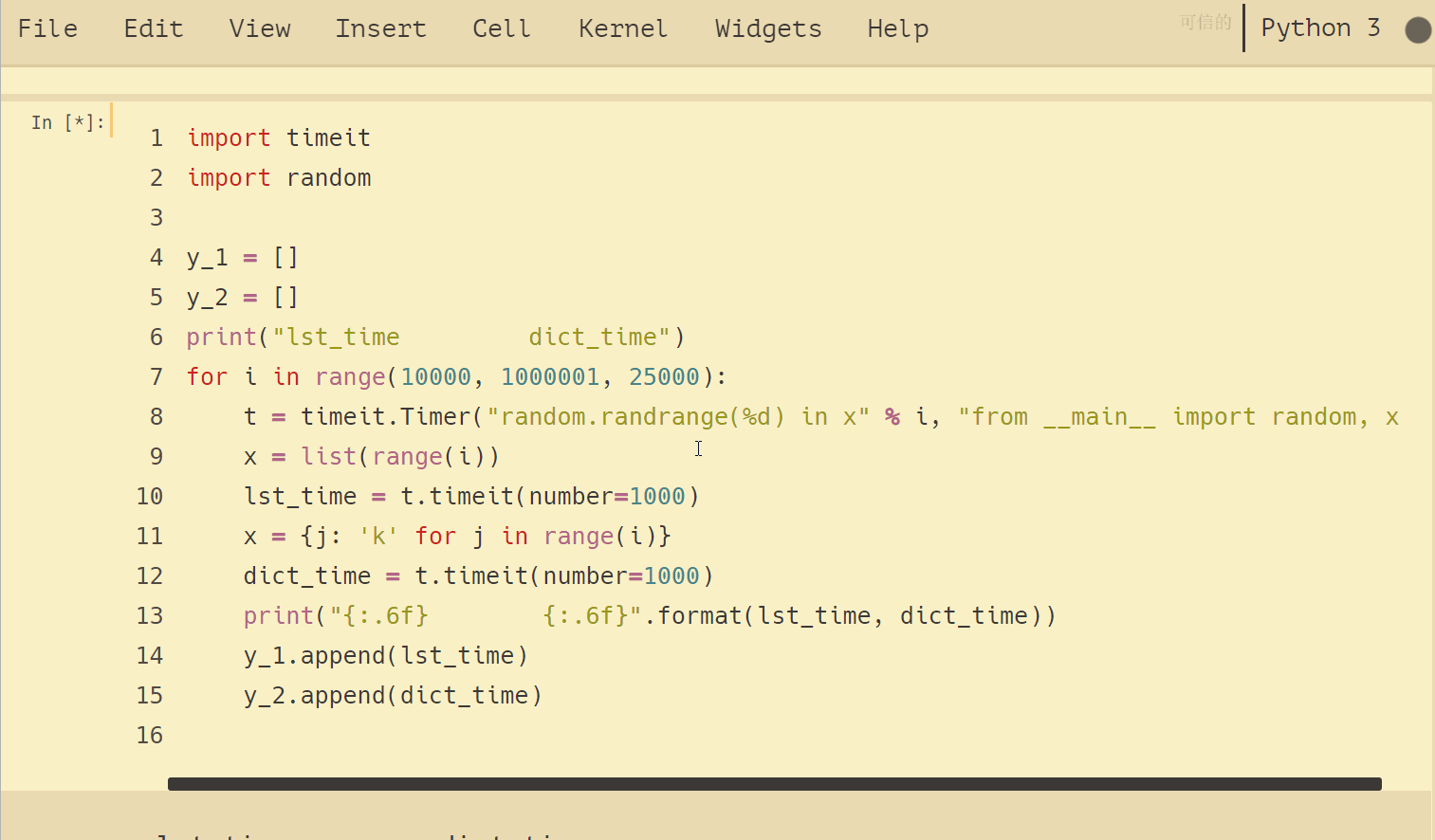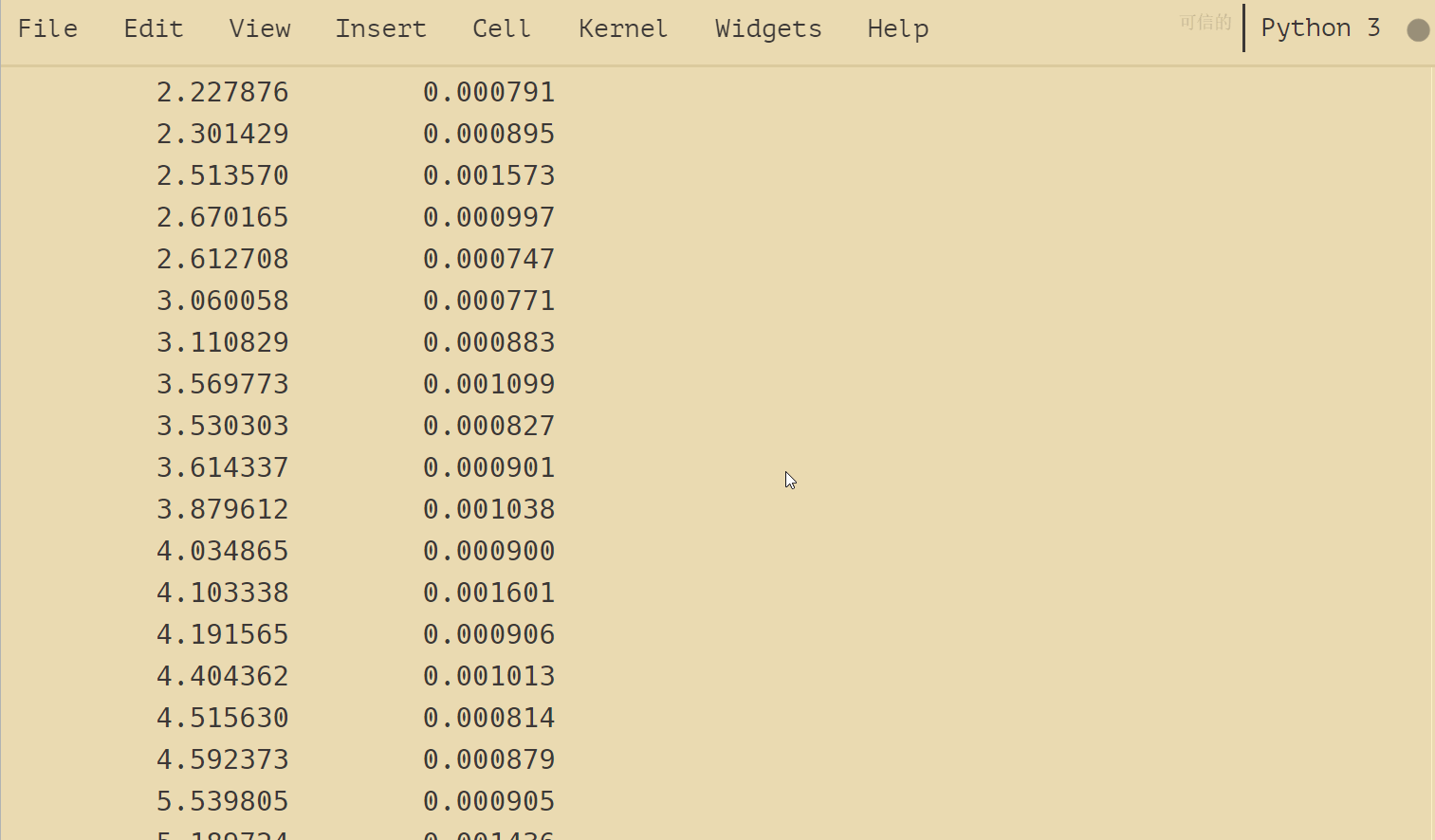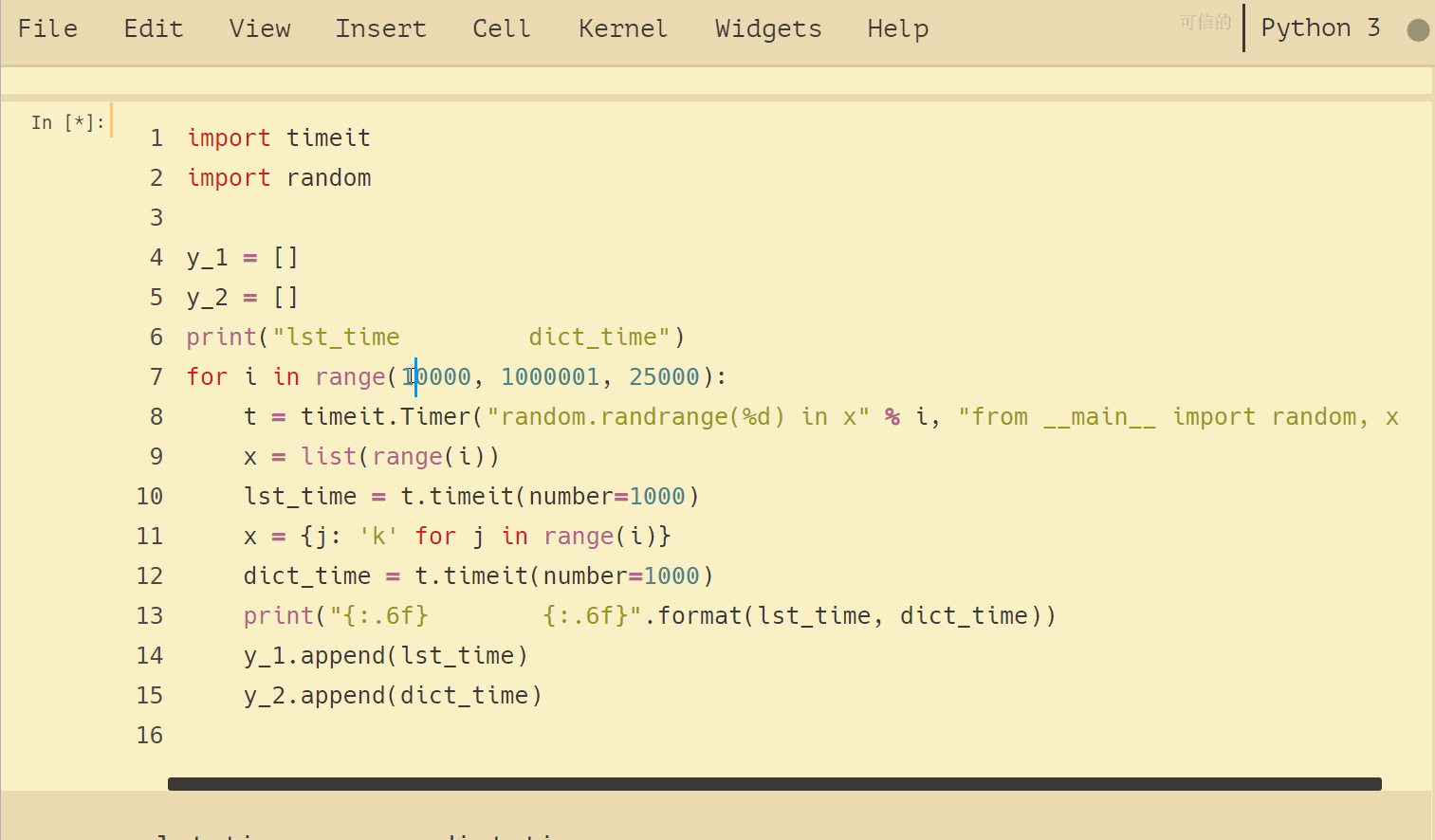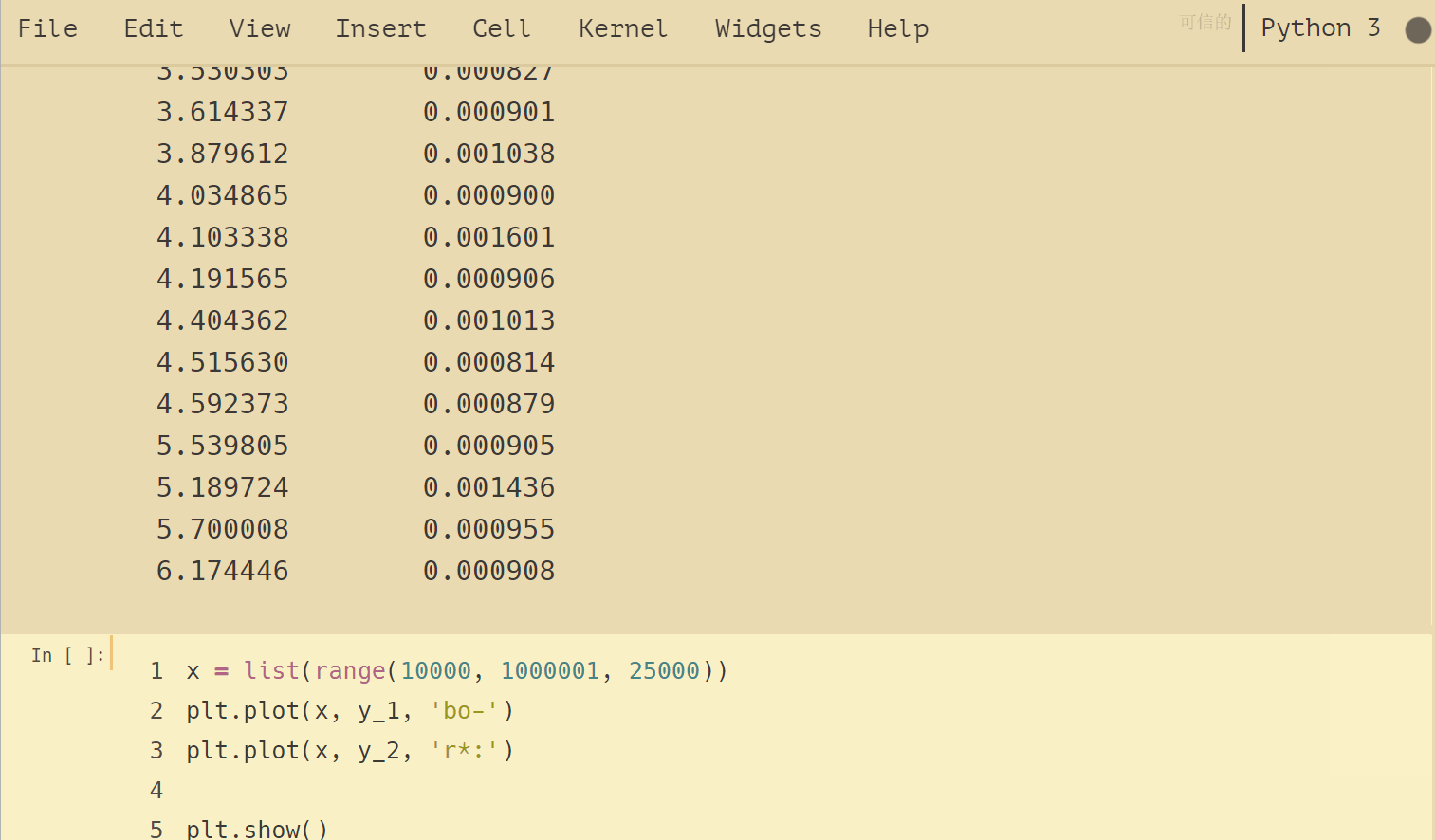
print("{:.6f} {:.6f}".format(lst_time, dict_time))
y_1.append(lst_time)
y_2.append(dict_time)
結果如下:
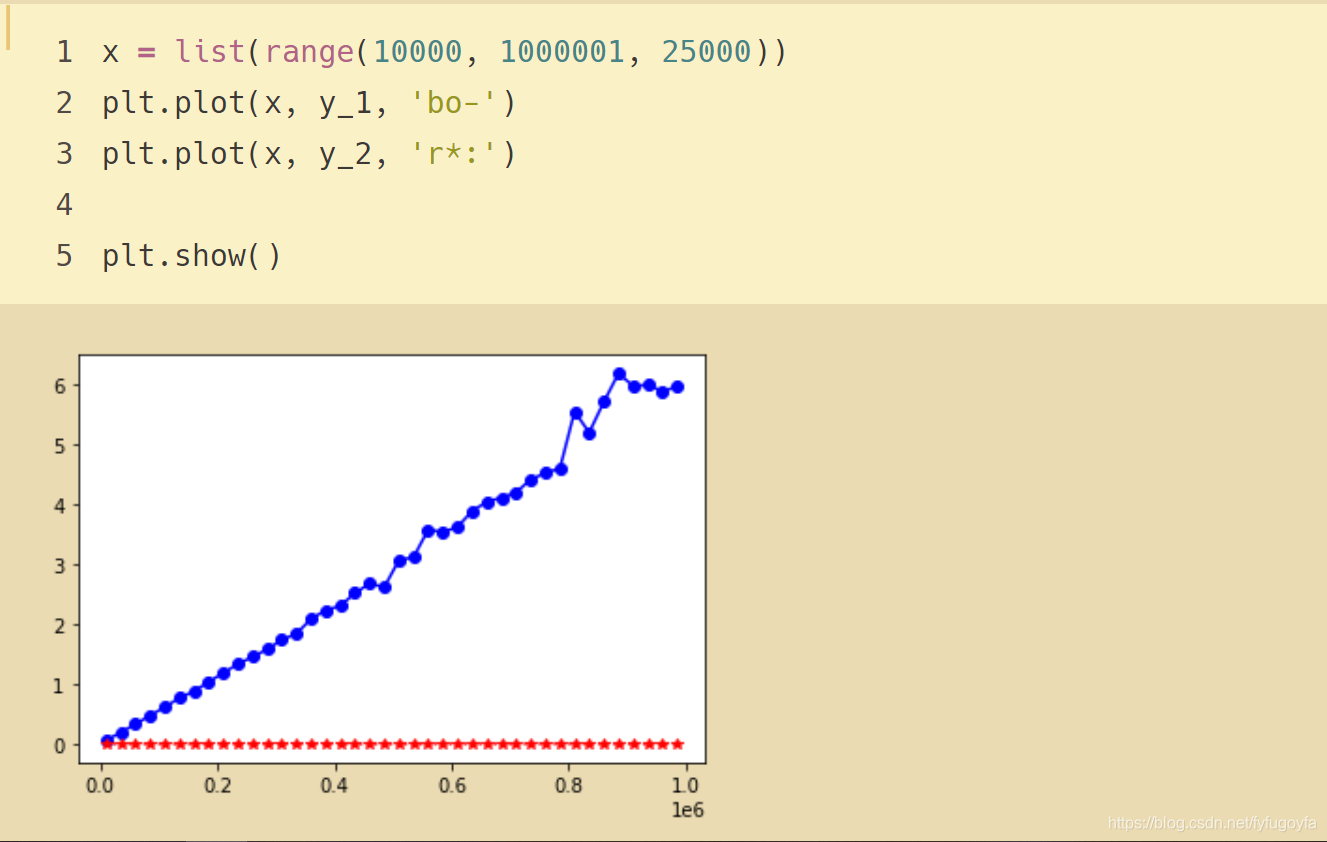
- 可見字典的執行時間與規模無關,是常數。
- 而列表的執行時間則會隨著列表的規模加大而線性上升。
更多 Python 數據類型操作復雜度可以參考官方文檔:
https://wiki.python.org/moin/TimeComplexity
到此這篇關于Python字典和列表性能之間的比較的文章就介紹到這了,更多相關Python列表和字典內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python實現字典序列ChainMap
- python基礎入門之字典和集合
- python字典與json轉換的方法總結
- python用函數創造字典的實例講解
