# coding=utf-8
from selenium import webdriver
import time
from PIL import Image, ImageGrab
from io import BytesIO
from selenium.webdriver.common.action_chains import ActionChains
import os
import sys
import re
import xlwt
import urllib
import datetime
'''
用于天眼查自動登錄,解決滑塊驗證問題
'''
# 獲取項目根目錄
def app_path():
if hasattr(sys, 'frozen'):
return os.path.dirname(os.path.dirname(os.path.dirname(sys.executable))) #使用pyinstaller打包后的exe目錄
return os.path.dirname(__file__)
app_path = app_path()
ready_list = []
#設置表格樣式
def set_style(name,height,bold=False):
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
# font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
# 寫excel
f = xlwt.Workbook()
sheet1 = f.add_sheet('企查查數據',cell_overwrite_ok=True)
row0 = ["企業名稱","法定代表人","注冊資本","成立日期","電話","郵箱","地址"]
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i], set_style('Times New Roman', 220, True))
# 寫列
def write_col(data, row, col):
for i in range(0,len(data)):
sheet1.write(row,col,data[i],set_style('Times New Roman',220,True))
row = row + 1
def parse_save_data(all_list):
row = 1
for data in all_list:
# 公司名稱
name_list = re.findall(r'div class="info">(.*?)/div>',data)
print(name_list)
# 標簽
tag_list = re.findall(r'div class="tag-list">(.*)/div>div class="info row text-ellipsis">', data)
tags = []
for list in tag_list:
tag = re.findall(r'div class="tag-common -primary -new">(.*?)/div>', list)
tags.append(tag)
# print(tags)
# 法定代表人
legal_list = re.findall(r'a title="(.*?)" class="legalPersonName link-click"',data)
# print(legal_list)
# 注冊資本
registered_capital_list = re.findall(r'注冊資本:span title="(.*?)">',data)
# print(registered_capital_list)
# 成立日期
date_list = re.findall(r'成立日期:span title="(.*?)">',data)
# print(date_list)
# 電話
tel_list = re.findall(r'div class="triangle" style="">/div>div class="">/div>/div>/div>span>(.*?)/span>',data)
# print(tel_list)
# 郵箱
email_list = re.findall(r'郵箱:/span>span>(.*?)/span>',data)
# print(email_list)
# 地址
adress_list = re.findall(r'地址:/span>span>(.*?)/span>',data)
# print(adress_list)
write_col(name_list,row,0)
# write_col(tags,1)
write_col(legal_list,row,1)
write_col(registered_capital_list,row,2)
write_col(date_list,row,3)
write_col(tel_list,row,4)
write_col(email_list,row,5)
write_col(adress_list,row,6)
row = row + len(name_list)
s = str([datetime.datetime.now()][-1])
name = '/天眼查數據' + s[:10] + s[-6:] + '.xls'
f.save(app_path + name)
def get_track(distance):
"""
根據偏移量獲取移動軌跡
:param distance: 偏移量
:return: 移動軌跡
"""
# 移動軌跡
track = []
# 當前位移
current = 0
# 減速閾值
mid = distance * 2 / 5
# 計算間隔
t = 0.2
# 初速度
v = 1
while current distance:
if current mid:
# 加速度為正2
a = 5
else:
# 加速度為負3
a = -2
# 初速度v0
v0 = v
# 當前速度v = v0 + at
v = v0 + a * t
# 移動距離x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 當前位移
current += move
# 加入軌跡
track.append(round(move))
return track
def autologin(account, password):
count = 0
global driver,page,keywords
driver.get('https://www.tianyancha.com/?jsid=SEM-BAIDU-PP-SY-000873bd_vid=7864822754227867779')
time.sleep(3)
try:
driver.find_element_by_xpath('//*[@id="tyc_banner_close"]').click()
except:
pass
driver.find_element_by_xpath('//div[@class="nav-item -home -p10"]/a').click()
time.sleep(3)
# 這里點擊密碼登錄時用id去xpath定位是不行的,因為這里的id是動態變化的,所以這里換成了class定位
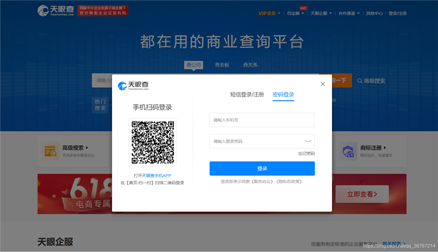
driver.find_element_by_xpath('.//div[@class="sign-in"]/div/div[2]').click()
time.sleep(1)
accxp = './/input[@id="mobile"]'
pasxp = './/input[@id="password"]'
driver.find_element_by_xpath(accxp).send_keys(account)
driver.find_element_by_xpath(pasxp).send_keys(password)
clixp = './/div[@class="sign-in"]/div[2]/div[2]'
driver.find_element_by_xpath(clixp).click()
# 點擊登錄之后開始截取驗證碼圖片
time.sleep(2)
img = driver.find_element_by_xpath('/html/body/div[10]/div[2]/div[2]/div[1]/div[2]/div[1]')
time.sleep(0.5)
# 獲取圖片位子和寬高
location = img.location
size = img.size
# 返回左上角和右下角的坐標來截取圖片
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size[
'width']
# 截取第一張圖片(無缺口的)
screenshot = driver.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
captcha1 = screenshot.crop((left, top, right, bottom))
print('--->', captcha1.size)
captcha1.save('captcha1.png')
# 截取第二張圖片(有缺口的)
driver.find_element_by_xpath('/html/body/div[10]/div[2]/div[2]/div[2]/div[2]').click()
time.sleep(4)
img1 = driver.find_element_by_xpath('/html/body/div[10]/div[2]/div[2]/div[1]/div[2]/div[1]')
time.sleep(0.5)
location1 = img1.location
size1 = img1.size
top1, bottom1, left1, right1 = location1['y'], location1['y'] + size1['height'], location1['x'], location1['x'] + \
size1['width']
screenshot = driver.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
captcha2 = screenshot.crop((left1, top1, right1, bottom1))
captcha2.save('captcha2.png')
# 獲取偏移量
left = 55 # 這個是去掉開始的一部分
for i in range(left, captcha1.size[0]):
for j in range(captcha1.size[1]):
# 判斷兩個像素點是否相同
pixel1 = captcha1.load()[i, j]
pixel2 = captcha2.load()[i, j]
threshold = 60
if abs(pixel1[0] - pixel2[0]) threshold and abs(pixel1[1] - pixel2[1]) threshold and abs(
pixel1[2] - pixel2[2]) threshold:
pass
else:
left = i
print('缺口位置', left)
# 減去缺口位移
left -= 52
# 開始移動
track = get_track(left)
print('滑動軌跡', track)
# track += [5,4,5,-6, -3,5,-2,-3, 3,6,-5, -2,-2,-4] # 滑過去再滑過來,不然有可能被吃
# 拖動滑塊
slider = driver.find_element_by_xpath('/html/body/div[10]/div[2]/div[2]/div[2]/div[2]')
ActionChains(driver).click_and_hold(slider).perform()
for x in track:
ActionChains(driver).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.2)
ActionChains(driver).release().perform()
time.sleep(1)
try:
if driver.find_element_by_xpath('/html/body/div[10]/div[2]/div[2]/div[2]/div[2]'):
print('能找到滑塊,重新試')
# driver.delete_all_cookies()
# driver.refresh()
# autologin(driver, account, password)
else:
print('login success')
except:
print('login success')
time.sleep(0.2)
driver.find_element_by_xpath('.//input[@id="home-main-search"]').send_keys(keywords)
driver.find_element_by_xpath('.//div[@class="input-group home-group"]/div[1]').click()
# 爬數據
data = driver.find_element_by_xpath('.//div[@class="result-list sv-search-container"]').get_attribute('innerHTML')
count = count + 1
# 添加待解析數據
ready_list.append(data)
while count page:
# 點擊下一頁
# driver.find_element_by_xpath('./ul[@class="pagination"]]/li/a[@class="num -next"]').click()
url = 'https://www.tianyancha.com/search/p{}?key={}'.format(count + 1,urllib.parse.quote(keywords))
driver.get(url)
time.sleep(2)
data = driver.find_element_by_xpath('.//div[@class="result-list sv-search-container"]').get_attribute('innerHTML')
count = count + 1
ready_list.append(data)
# 解析并寫數據
parse_save_data(ready_list)
print('獲取數據完畢')
# if __name__ == '__main__':
# driver_path = 'C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe'
# chromeoption = webdriver.ChromeOptions()
# chromeoption.add_argument('--headless')
# chromeoption.add_argument('user-agent='+user_agent)
keywords = input('請輸入關鍵詞:')
account = input('請輸入查天眼賬號:')
password = input('請輸入查天眼密碼:')
page = int(input('請輸入獲取頁數:'))
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
print('開始獲取數據。。。')
autologin(account, password)
到此這篇關于Python自動化爬取天眼查數據的文章就介紹到這了,更多相關Python自動化爬取天眼查數據內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!