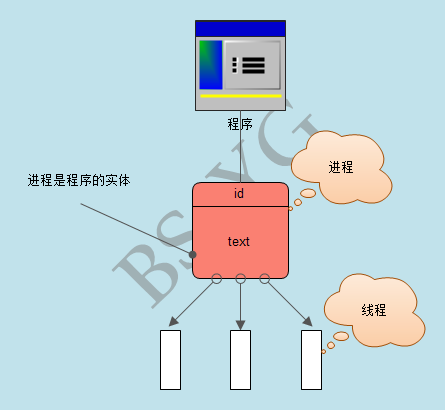
進程是什么?
進程就是一個程序在一個數據集上的一次動態執行過程。進程一般由程序、數據集、進程控制塊三部分組成。我們編寫的程序用來描述進程要完成哪些功能以及如何完成;數據集則是程序在執行過程中所需要使用的資源;進程控制塊用來記錄進程的外部特征,描述進程的執行變化過程,系統可以利用它來控制和管理進程,它是系統感知進程存在的唯一標志。
線程是什么?
線程也叫輕量級進程,它是一個基本的CPU執行單元,也是程序執行過程中的最小單元,由線程ID、程序計數器、寄存器集合和堆棧共同組成。線程的引入減小了程序并發執行時的開銷,提高了操作系統的并發性能。線程沒有自己的系統資源。
進程和線程的區別
進程是計算機中的程序關于某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎。或者說進程是具有一定獨立功能的程序關于某個數據集合上的一次運行活動,進程是系統進行資源分配和調度的一個獨立單位。
線程則是進程的一個實體,是CPU調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位。
進程和線程的關系:
(1)一個線程只能屬于一個進程,而一個進程可以有多個線程,但至少有一個線程。
(2)資源分配給進程,同一進程的所有線程共享該進程的所有資源。
(3)CPU分給線程,即真正在CPU上運行的是線程。
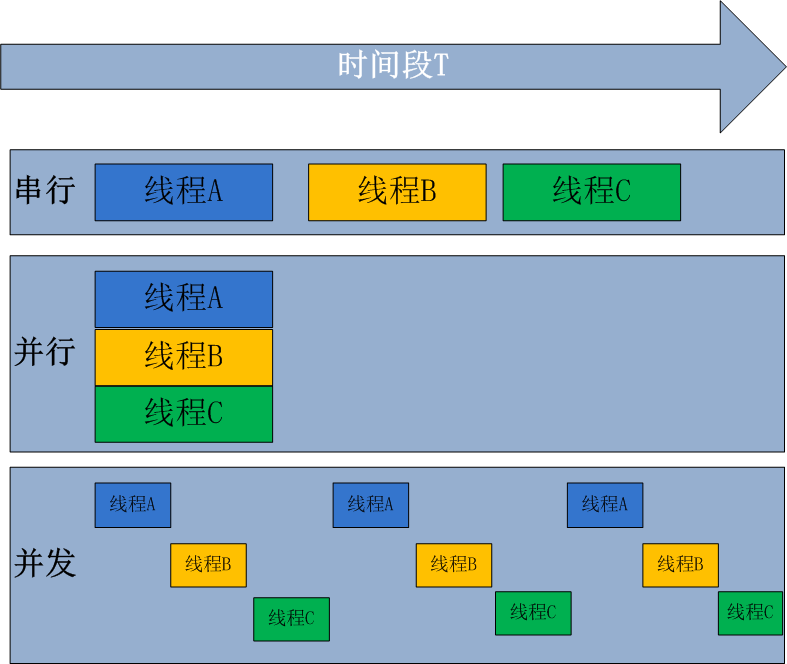
并行和并發
并行處理(Parallel Processing)是計算機系統中能同時執行兩個或者更多個處理的一種計算方法。并行處理可同時工作于同一程序的不同方面,并行處理的主要目的是節省大型和復雜問題的解決時間。
并發處理(concurrency Processing)是指一個時間段中有幾個程序都處于已經啟動運行到運行完畢之間,而且這幾個程序都是在同一處理機(CPU)上運行,但任意時刻點上只有一個程序在處理機(CPU)上運行
同步和異步
同步就是指一個進程在執行某個請求的時候,若該請求需要一段時間才能返回信息,那么這個進程將會一直等待下去,直到收到返回信息才繼續執行下去;
異步是指進程不需要一直等下去,而是繼續執行下面的操作,不管其他進程的狀態。當有消息返回時系統會通知進程進行處理,這樣可以提高執行的效率。
舉個例子,打電話時就是同步通信,發短息時就是異步通信。
單例執行
from random import randint
from time import time, sleep
def download_task(filename):
print('開始下載%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下載完成! 耗費了%d秒' % (filename, time_to_download))
def main():
start = time()
download_task('Python入門.pdf')
download_task('av.avi')
end = time()
print('總共耗費了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
運行是順序執行,所以耗時是多個進程的時間總和
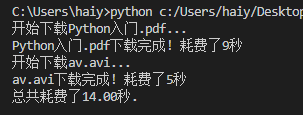
因為是單進程任務,所有任務都是排隊進行所以這樣執行效率非常的低。我們來添加多進程模式進行多進程同時執行,這樣一個進程執行時,另一個進程無需等待,執行時間將大大縮短。
多進程
from random import randint
from time import time, sleep
from multiprocessing import Process
from os import getpid
def download_task(filename):
print('啟動下載進程,進程號:[%d]'%getpid())
print('開始下載%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下載完成! 耗費了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task,args=('python入門.pdf',))
p2 = Process(target=download_task,args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
# download_task('Python入門.pdf')
# download_task('av.avi')
end = time()
print('總共耗費了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
多個進程并排執行,總耗時就是最長耗時的那個進程的時間。
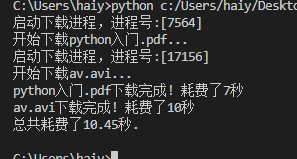
大致的執行流程如下圖
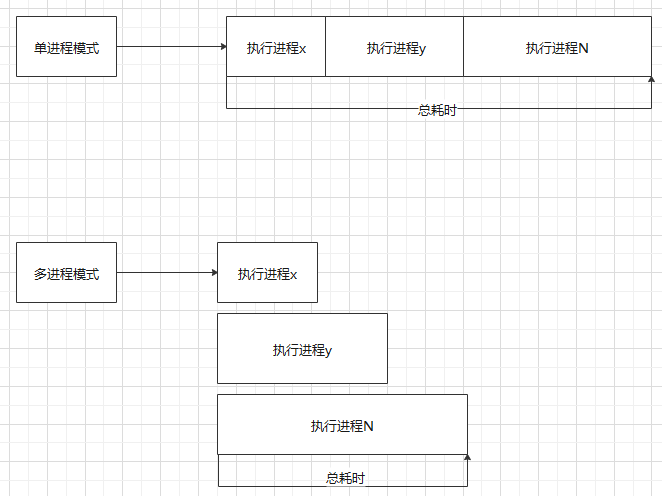
多進程的特點是相互獨立,不會共享全局變量,即在一個進程中對全局變量修改過后,不會影響另一個進程中的全局變量。
進程間通信
from random import randint
from time import time,sleep
from multiprocessing import Process
from os import getpid
time_to_download = 3
def download_task(filename):
global time_to_download
time_to_download += 1
print('啟動下載進程,進程號:[%d]'%getpid())
print('開始下載%s...' % filename)
sleep(time_to_download)
print('%s下載完成! 耗費了%d秒' % (filename, time_to_download))
def download_task2(filename):
global time_to_download
print('啟動下載進程,進程號:[%d]'%getpid())
print('開始下載%s...' % filename)
sleep(time_to_download)
print('%s下載完成! 耗費了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task,args=('python入門.pdf',))
p2 = Process(target=download_task2,args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
end = time()
print('總共耗費了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
從執行結果可以看出,兩個進程間的全局變量無法共享,所以它們是相互獨立的
當然多進程也是可以進行通過一些方法進行數據共享的。可以使用multiprocessing模塊的Queue實現多進程之間的數據傳遞,Queue本身是一個消息列隊程序。
這里介紹Queue的常用進程通信的兩種方法:
put 方法用以插入數據到隊列中, put 方法還有兩個可選參數: blocked 和 timeout。如果 blocked 為 True(默認值),并且 timeout 為正值,該方法會阻塞 timeout 指定的時間,直到該隊列有剩余的空間。如果超時,會拋出 Queue.full 異常。如果 blocked 為 False,但該 Queue 已滿,會立即拋出 Queue.full 異常。
get 方法可以從隊列讀取并且刪除一個元素。同樣, get 方法有兩個可選參數: blocked和 timeout。如果 blocked 為 True(默認值),并且 timeout 為正值,那么在等待時間內沒有取到任何元素,會拋出 Queue.Empty 異常。如果 blocked 為 False,有兩種情況存在,如果Queue 有一個值可用,則立即返回該值,否則,如果隊列為空,則立即拋出Queue.Empty 異常。
Queue 隊列實現進程間通信
from random import randint
from time import time,sleep
from multiprocessing import Process
import multiprocessing
from os import getpid
time_to_download = 3
def write(q):
for i in ['python入門','av.avi','java入門']:
q.put(i)
print('啟動寫入進程,進程號:[%d]'%getpid())
print('開始寫入%s...' % i)
sleep(time_to_download)
def read(q):
while True:
if not q.empty():
print('啟動讀取進程,進程號:[%d]'%getpid())
print('開始讀取%s...' % q.get())
sleep(time_to_download)
else:
break
def main():
q = multiprocessing.Queue()
p1 = Process(target=write,args=(q,))
p2 = Process(target=read,args=(q,))
p1.start()
p1.join()
p2.start()
p2.join()
if __name__ == '__main__':
main()
上一個進程寫入的數據通過Queue隊列共享給了下一個進程,然后下一個進程可以直接進行使用,這樣就完成了多進程間的數據共享。

進程池
Pool類可以提供指定數量的進程供用戶調用,當有新的請求提交到Pool中時,如果池還沒有滿,就會創建一個新的進程來執行請求。如果池滿,請求就會告知先等待,直到池中有進程結束,才會創建新的進程來執行這些請求。
進程池中常見三個方法:
◆apply:串行
◆apply_async:并行
◆map
多線程
from random import randint
from time import time, sleep
from threading import Thread
from os import getpid
def download_task(filename):
print('啟動下載進程,進程號:[%d]' % getpid())
print('開始下載%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下載完成! 耗費了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Thread(target=download_task, args=('python入門.pdf',))
p2 = Thread(target=download_task, args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
end = time()
print('總共耗費了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
多線程執行因為GIL鎖的存在,實際上執行是進行單線程,即一次只執行一個線程,然后在切換其他的線程進行執行,因為其中切換的時間非常的短,所以看上去依然像是多線程一起執行。
通過繼承Thread類的方式來創建自定義的線程類,然后再創建線程對象并啟動線程
from random import randint
from threading import Thread
from time import time, sleep
class DownloadTask(Thread):
def __init__(self, filename):
super().__init__()
self._filename = filename
def run(self):
print('開始下載%s...'% self._filename)
time_to_download = randint(5,10)
sleep(time_to_download)
print('%s下載完成!耗費了%d秒' %(self._filename, time_to_download))
def main():
start = time()
t1 = DownloadTask('python入門')
t2 = DownloadTask('av.avi')
t1.start()
t2.start()
t1.join()
t2.join()
end = time()
print('共耗費了%.2f秒'%(end - start))
if __name__ == '__main__':
main()
多線程使用類還是函數執行的結果完全一致,具體怎么使用可以結合自己的使用場景。

到此這篇關于詳解Python中的進程和線程的文章就介紹到這了,更多相關Python進程和線程內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python多線程與多進程相關知識總結
- Python多進程與多線程的使用場景詳解
- Python之多進程與多線程的使用
- Python 多進程、多線程效率對比
- python中線程和進程有何區別
- python 在threading中如何處理主進程和子線程的關系
- Python隊列、進程間通信、線程案例
