目錄
- MNIST 數據集介紹
- LeNet 模型介紹
- LeNet 逐層分析
- 1. 第一個卷積層
- 2. 第一個池化層
- 3. 第二個卷積層
- 4. 第二個池化層
- 5. 全連接卷積層
- 6. 全連接層
- 7. 全連接層 (輸出層)
- 代碼實現
- 導包
- 讀取 查看數據
- 數據預處理
- 模型建立
- 訓練模型
- 保存模型
- 流程總結
- 完整代碼
MNIST 數據集介紹
MNIST 包含 0~9 的手寫數字, 共有 60000 個訓練集和 10000 個測試集. 數據的格式為單通道 28*28 的灰度圖.
LeNet 模型介紹
LeNet 網絡最早由紐約大學的 Yann LeCun 等人于 1998 年提出, 也稱 LeNet5. LeNet 是神經網絡的鼻祖, 被譽為卷積神經網絡的 “Hello World”.
卷積

池化 (下采樣)
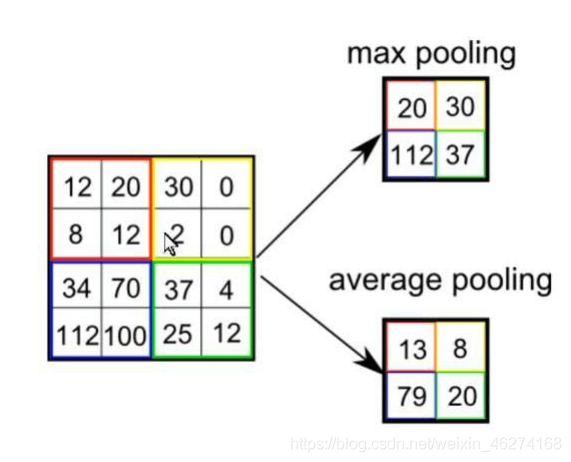
激活函數 (ReLU)

LeNet 逐層分析
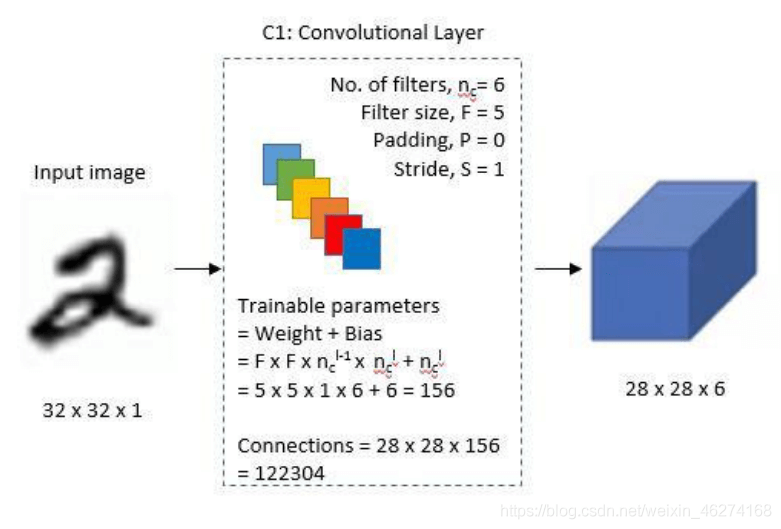
1. 第一個卷積層
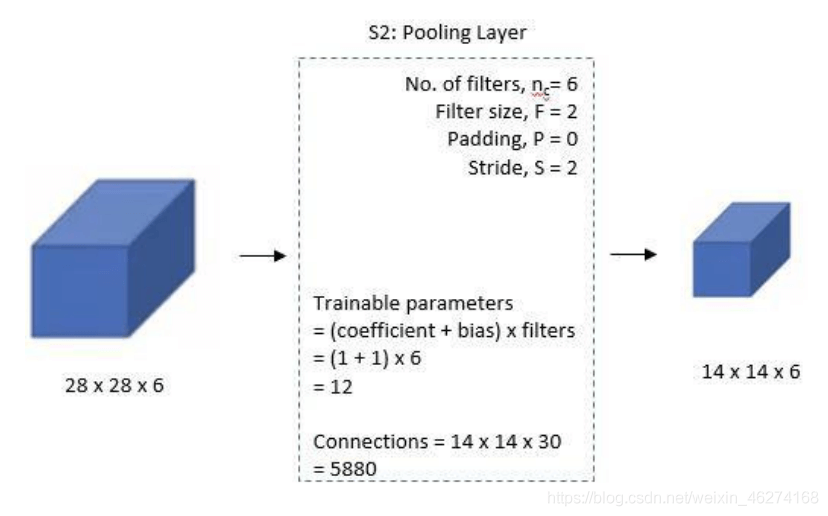
2. 第一個池化層
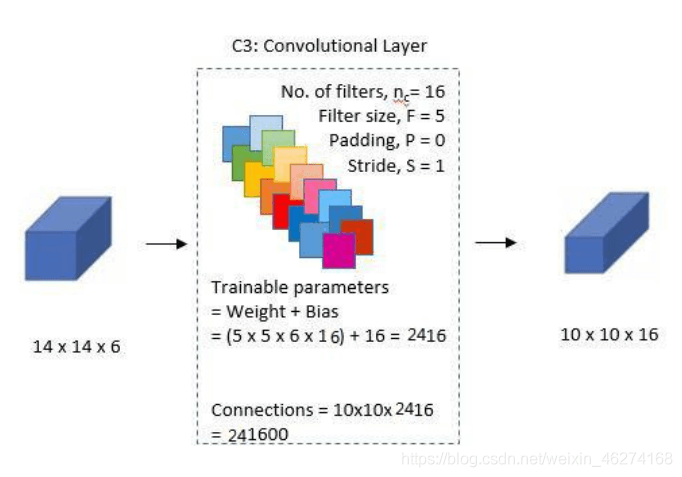
3. 第二個卷積層
4. 第二個池化層
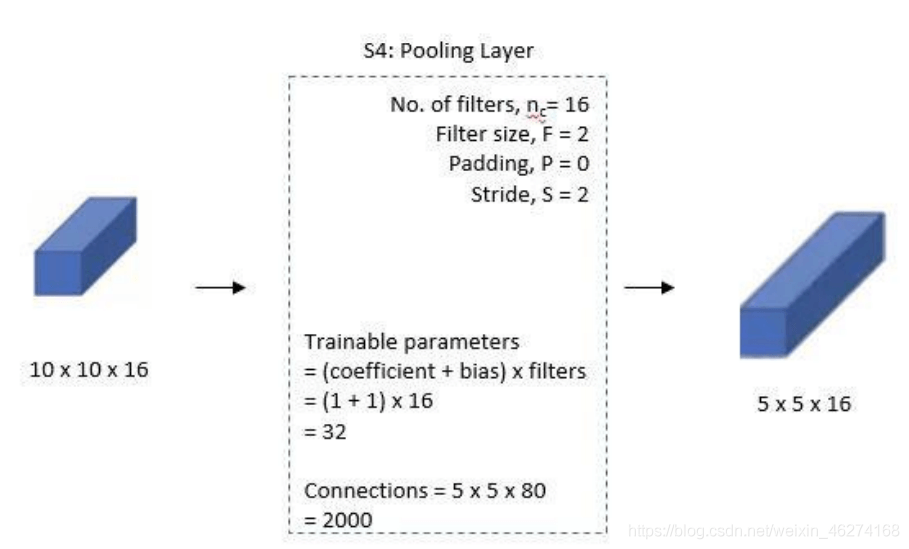
5. 全連接卷積層
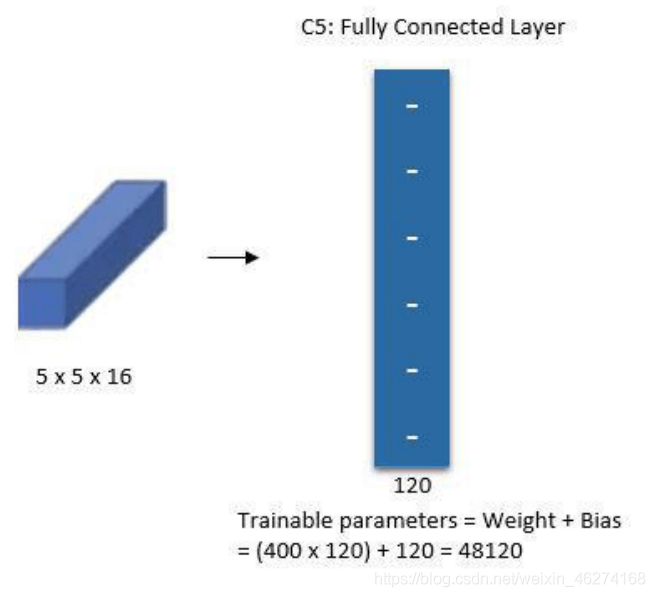
6. 全連接層

7. 全連接層 (輸出層)
代碼實現
導包
from tensorflow.keras.datasets import mnist
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
讀取 查看數據
# ------------------1. 讀取 查看數據------------------
# 讀取數據
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 數據集查看
print(X_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
print(X_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
print(type(X_train)) # class 'numpy.ndarray'>
# 圖片顯示
plt.imshow(X_train[0], cmap="Greys") # 查看第一張圖片
plt.show()
數據預處理
# ------------------2. 數據預處理------------------
# 格式轉換 (將圖片從28*28擴充為32*32)
X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
print(X_train.shape) # (60000, 32, 32)
print(X_test.shape) # (10000, 32, 32)
# 數據集格式變換
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
# 數據正則化
X_train /= 255
X_test /= 255
# 數據維度轉換
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
print(X_train.shape) # (60000, 32, 32, 1)
print(X_test.shape) # (10000, 32, 32, 1)
模型建立
# 第一個卷積層
conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第一個池化層
pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same")
# 第二個卷積層
conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第二個池化層
pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same")
# 扁平化
flatten = tf.keras.layers.Flatten()
# 第一個全連接層
fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
# 第二個全連接層
fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax)
# 輸出層
output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
卷積 Conv2D 的用法:
- filters: 卷積核個數
- kernel_size: 卷積核大小
- strides = (1, 1): 步長
- padding = “vaild”: valid 為舍棄, same 為補齊
- activation = tf.nn.relu: 激活函數
- data_format = None: 默認 channels_last
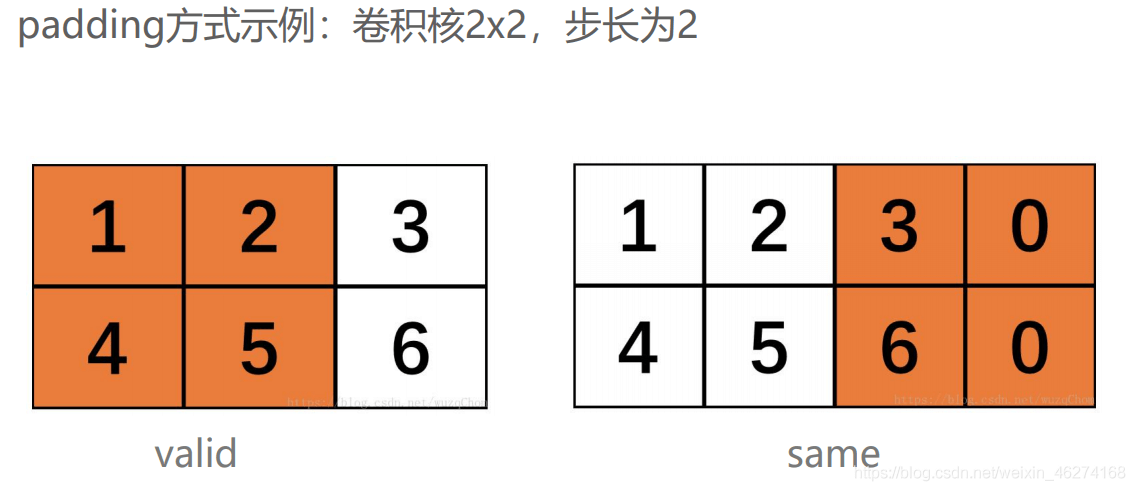
池化 AveragePooling2D 的用法:
- pool_size: 池的大小
- strides = (1, 1): 步長
- padding = “vaild”: valid 為舍棄, same 為補齊
- activation = tf.nn.relu: 激活函數
- data_format = None: 默認 channels_last
全連接 Dense 的用法:
- units: 輸出的維度
- activation: 激活函數
- strides = (1, 1): 步長
- padding = “vaild”: valid 為舍棄, same 為補齊
- activation = tf.nn.relu: 激活函數
- data_format = None: 默認 channels_last
# 模型實例化
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu,
input_shape=(32, 32, 1)),
# relu
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu),
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
])
# 模型展示
model.summary()
輸出結果:

訓練模型
# ------------------4. 訓練模型------------------
# 設置超參數
num_epochs = 10 # 訓練輪數
batch_size = 1000 # 批次大小
learning_rate = 0.001 # 學習率
# 定義優化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)
model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
complie 的用法:
- optimizer: 優化器
- loss: 損失函數
- metrics: 評價
with tf.Session() as sess:
# 初始化所有變量
init = tf.global_variables_initializer()
sess.run(init)
model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs)
# 評估指標
print(model.evaluate(X_test, y_test)) # loss value metrics values
輸出結果:

fit 的用法:
- x: 訓練集
- y: 測試集
- batch_size: 批次大小
- enpochs: 訓練遍數
保存模型
# ------------------5. 保存模型------------------
model.save('lenet_model.h5')
流程總結
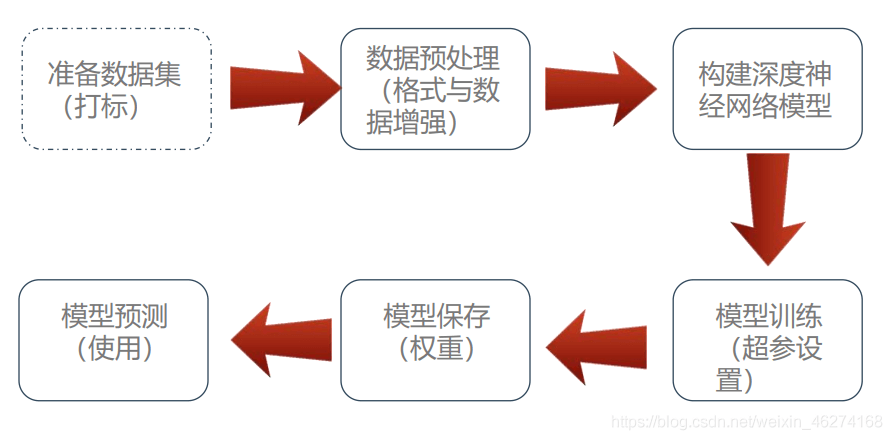
完整代碼
from tensorflow.keras.datasets import mnist
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
# ------------------1. 讀取 查看數據------------------
# 讀取數據
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 數據集查看
print(X_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
print(X_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
print(type(X_train)) # class 'numpy.ndarray'>
# 圖片顯示
plt.imshow(X_train[0], cmap="Greys") # 查看第一張圖片
plt.show()
# ------------------2. 數據預處理------------------
# 格式轉換 (將圖片從28*28擴充為32*32)
X_train = np.pad(X_train, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
X_test = np.pad(X_test, ((0, 0), (2, 2), (2, 2)), "constant", constant_values=0)
print(X_train.shape) # (60000, 32, 32)
print(X_test.shape) # (10000, 32, 32)
# 數據集格式變換
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
# 數據正則化
X_train /= 255
X_test /= 255
# 數據維度轉換
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
print(X_train.shape) # (60000, 32, 32, 1)
print(X_test.shape) # (10000, 32, 32, 1)
# ------------------3. 模型建立------------------
# 第一個卷積層
conv_layer_1 = tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第一個池化層
pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding="same")
# 第二個卷積層
conv_layer_2 = tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding="valid", activation=tf.nn.relu)
# 第二個池化層
pool_layer_2 = tf.keras.layers.MaxPool2D(padding="same")
# 扁平化
flatten = tf.keras.layers.Flatten()
# 第一個全連接層
fc_layer_1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
# 第二個全連接層
fc_layer_2 = tf.keras.layers.Dense(units=84, activation=tf.nn.softmax)
# 輸出層
output_layer = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
# 模型實例化
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu,
input_shape=(32, 32, 1)),
# relu
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu),
tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation=tf.nn.relu),
tf.keras.layers.Dense(units=84, activation=tf.nn.relu),
tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
])
# 模型展示
model.summary()
# ------------------4. 訓練模型------------------
# 設置超參數
num_epochs = 10 # 訓練輪數
batch_size = 1000 # 批次大小
learning_rate = 0.001 # 學習率
# 定義優化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)
model.compile(optimizer=adam_optimizer,loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
with tf.Session() as sess:
# 初始化所有變量
init = tf.global_variables_initializer()
sess.run(init)
model.fit(x=X_train,y=y_train,batch_size=batch_size,epochs=num_epochs)
# 評估指標
print(model.evaluate(X_test, y_test)) # loss value metrics values
# ------------------5. 保存模型------------------
model.save('lenet_model.h5')
到此這篇關于由淺入深學習TensorFlow MNIST 數據集的文章就介紹到這了,更多相關TensorFlow MNIST 數據集內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- TensorFlow 實戰之實現卷積神經網絡的實例講解
- PyTorch上實現卷積神經網絡CNN的方法
- CNN的Pytorch實現(LeNet)
- Python深度學習pytorch卷積神經網絡LeNet
