from multiprocessing import Process
def show(name):
print("Process name is " + name)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
方法2:繼承Process來自定義進程類,重寫run方法
代碼如下:
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super(MyProcess, self).__init__()
self.name = name
def run(self):
print('process name :' + str(self.name))
time.sleep(1)
if __name__ == '__main__':
for i in range(3):
p = MyProcess(i)
p.start()
for i in range(3):
p.join()
from multiprocessing import Process, Pipe
def show(conn):
conn.send('Pipe 用法')
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
pro = Process(target=show, args=(child_conn,))
pro.start()
print(parent_conn.recv())
pro.join()
2.3 進程池
創建多個進程,我們不用傻傻地一個個去創建。我們可以使用Pool模塊來搞定。
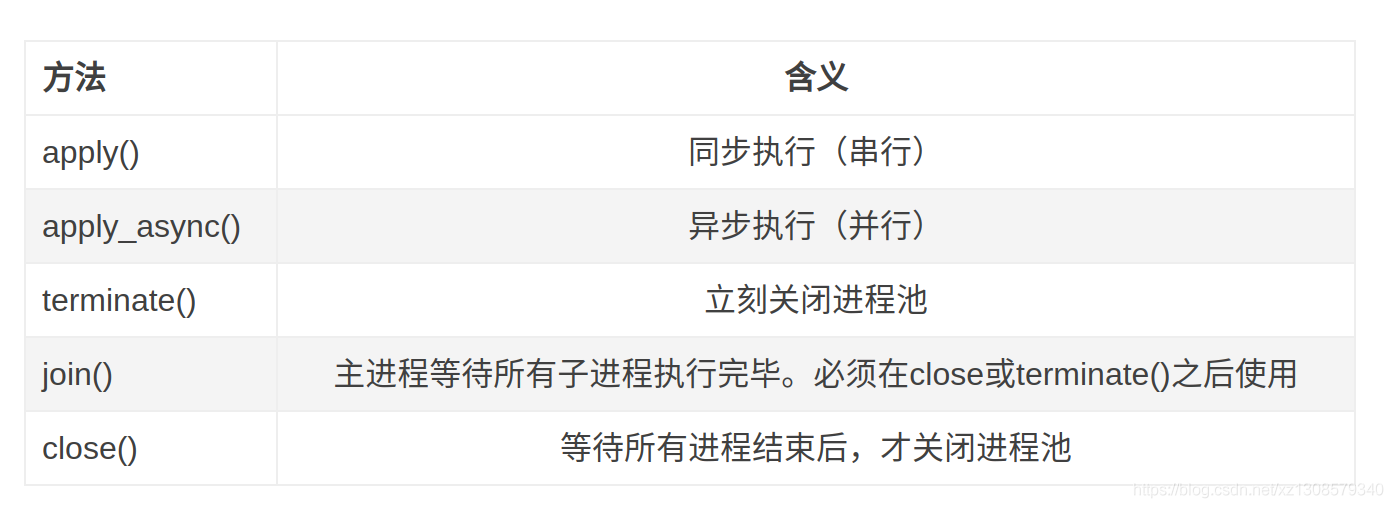
Pool 常用的方法如下:
具體用法見示例代碼:
from multiprocessing import Pool
def show(num):
print('num : ' + str(num))
if __name__=="__main__":
pool = Pool(processes = 3)
for i in xrange(6):
# 維持執行的進程總數為processes,當一個進程執行完畢后會添加新的進程進去
pool.apply_async(show, args=(i, ))
print('====== apply_async ======')
pool.close()
#調用join之前,先調用close函數,否則會出錯。執行完close后不會有新的進程加入到pool,join函數等待所有子進程結束
pool.join()
3 Python 多線程
3.1 GIL
其他語言,CPU 是多核時是支持多個線程同時執行。但在 Python 中,無論是單核還是多核,同時只能由一個線程在執行。其根源是 GIL 的存在。
GIL 的全稱是 Global Interpreter Lock(全局解釋器鎖),來源是 Python 設計之初的考慮,為了數據安全所做的決定。某個線程想要執行,必須先拿到 GIL,我們可以把 GIL 看作是“通行證”,并且在一個 Python 進程中,GIL 只有一個。拿不到通行證的線程,就不允許進入 CPU 執行。
import threading
import time
num = 0
mutex = threading.Lock()
class MyThread(threading.Thread):
def run(self):
global num
time.sleep(1)
if mutex.acquire(1):
num = num + 1
msg = self.name + ': num value is ' + str(num)
print(msg)
mutex.release()
if __name__ == '__main__':
for i in range(5):
t = MyThread()
t.start()