首先���,假設我們有如下餐廳數據集:
import pandas as pd
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})
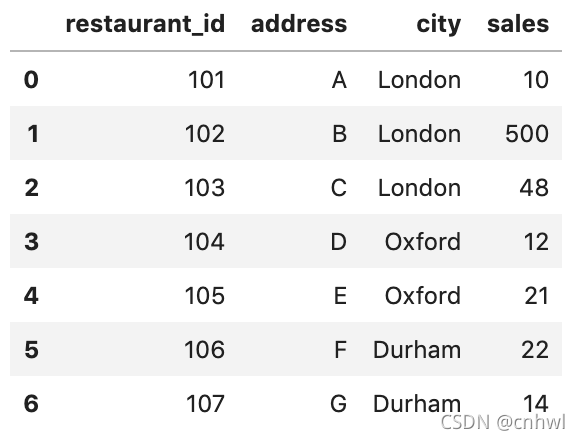
如果我們想知道:每個餐廳在城市中所占的銷售額百分比是多少��?預期得到的輸出是:
相比于原來的數據集,多了兩列,分別是某個城市所有餐廳的銷售總額,以及每個餐廳在城市中所占的銷售額百分比。解決方案有兩個:
方案一(較麻煩):
1、使用 groupby('city') 基于城市進行分組����,對于這些組中的每一個組����,選中其銷售額列 ['sales']����,然后使用函數 apply(sum) 或者sum() 對城市的銷售額進行求和��。
之后�����,新列被重命名為 city_total_sales 并且索引被重置(注意不能漏了 reset_index() ,因為 groupby('city') 生成的索引是城市�����,而我們希望城市作為普通列)���。
city_sales = df.groupby('city')['sales']
.sum().rename('city_total_sales').reset_index()
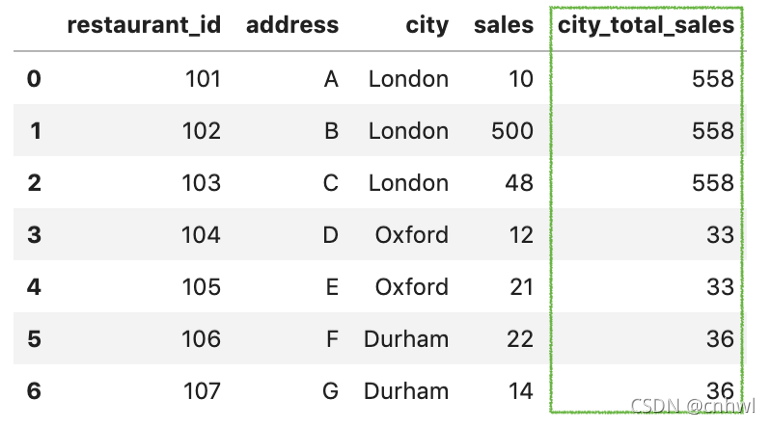
得到的 city_sales 如下:

2�����、用 merge() 函數把 city_sales 合并回去�����,得到的 df_new 如下:
df_new = pd.merge(df, city_sales, how='left')
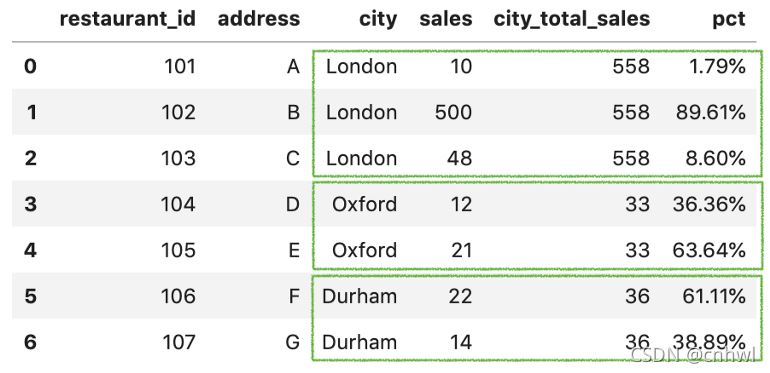
3、最后���,求百分比并保留兩位小數,結果如下:
df_new['pct'] = df_new['sales'] / df_new['city_total_sales']
df_new['pct'] = df_new['pct'].apply(lambda x: format(x, '.2%'))
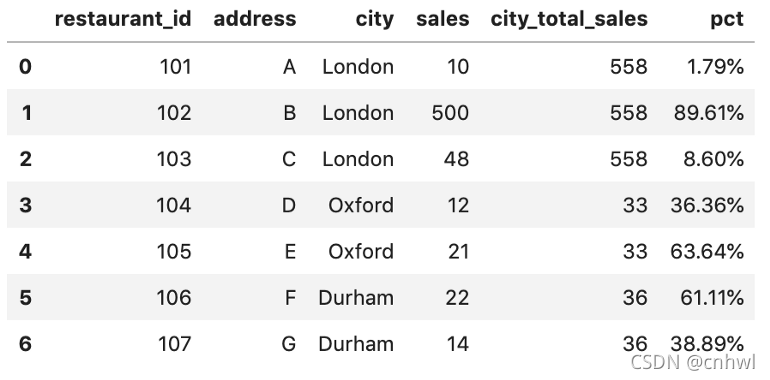
方案二(便捷):
1���、
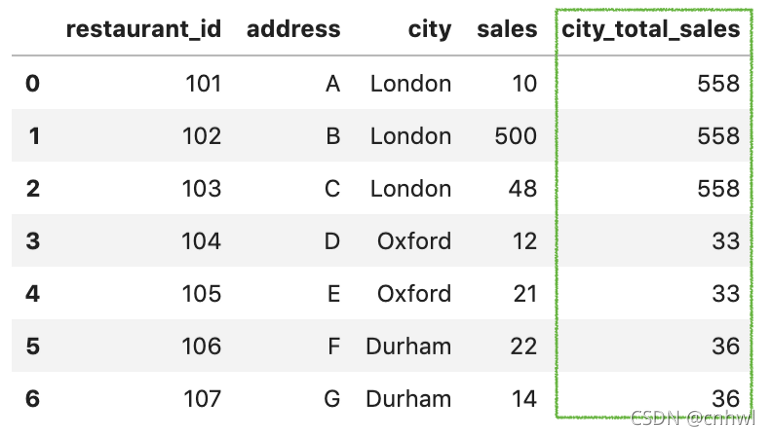
transform() 函數在執行轉換后保留與原始數據集相同數量的項目�。因此��,使用 groupby() 然后使用 transform(sum) 會返回相同的輸出����,結果如下圖:
df['city_total_sales'] = df.groupby('city')['sales']
.transform('sum')
代碼翻譯過來就是:數據集基于城市進行分組��,然后選定銷售額列,對每組的銷售額進行求和����,返回一個和原列長度一樣的新列����。
2���、
與方案一相同��。
df['pct'] = df['sales'] / df['city_total_sales']
df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
總結:可以看出���,在對 DataFrame 進行分組 groupby() 之后�����,如果是使用 apply() 或者直接使用某個統計函數,得到的新列的長度與分組得到的組數是一樣的����;而如果使用 transform() �,得到的新列與 DataFrame 中列的長度是一樣的�����。
到此這篇關于Pandas中的 transform()結合 groupby()用法示例詳解的文章就介紹到這了,更多相關Pandas groupby() 用法內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- pandas數據分組groupby()和統計函數agg()的使用
- pandas之分組groupby()的使用整理與總結
- 分享Pandas庫中的一些寶藏函數transform()
