發現問題
今天準備學習下tomcat源碼,于是從官網下載了tomcat的源碼,導入到IDEA中,使用maven工具build完項目之后,啟動項目,控制臺打印了tomcat日志,但是中文都是亂碼。
一開始我懷疑是IDEA的問題,于是在網上找了各種解決辦法嘗試。大致有這幾種:
1、修改run/debug configurations,添加VM options參數:-Dfile.encoding=utf-8;
2、修改run/debug configurations,添加Enviroment variables參數:JAVA_TOOL_OPTIONS:-Dfile.encoding=utf-8和JAVA_OPTS:-Dfile.encoding=utf-8;
3、修改IDEA配置file encodings的3處編碼為UTF-8;
4、修改IDEA的Custom VM options,添加-Dfile.encoding=utf-8;
5、修改IDEA的安裝目錄bin下的idea.exe.vmoptions和idea64.exe.vmoptions文件,添加-Dfile.encoding=utf-8;
6、修改項目下的.idea文件夾下的encodings.xml文件,不是UTF-8的改為UTF-8;
7、修改tomcat的配置文件logging.properties,將里面的UTF-8改為GBK;
8、修改完刪除target文件夾重新編譯;
9、修改完重啟IDEA。
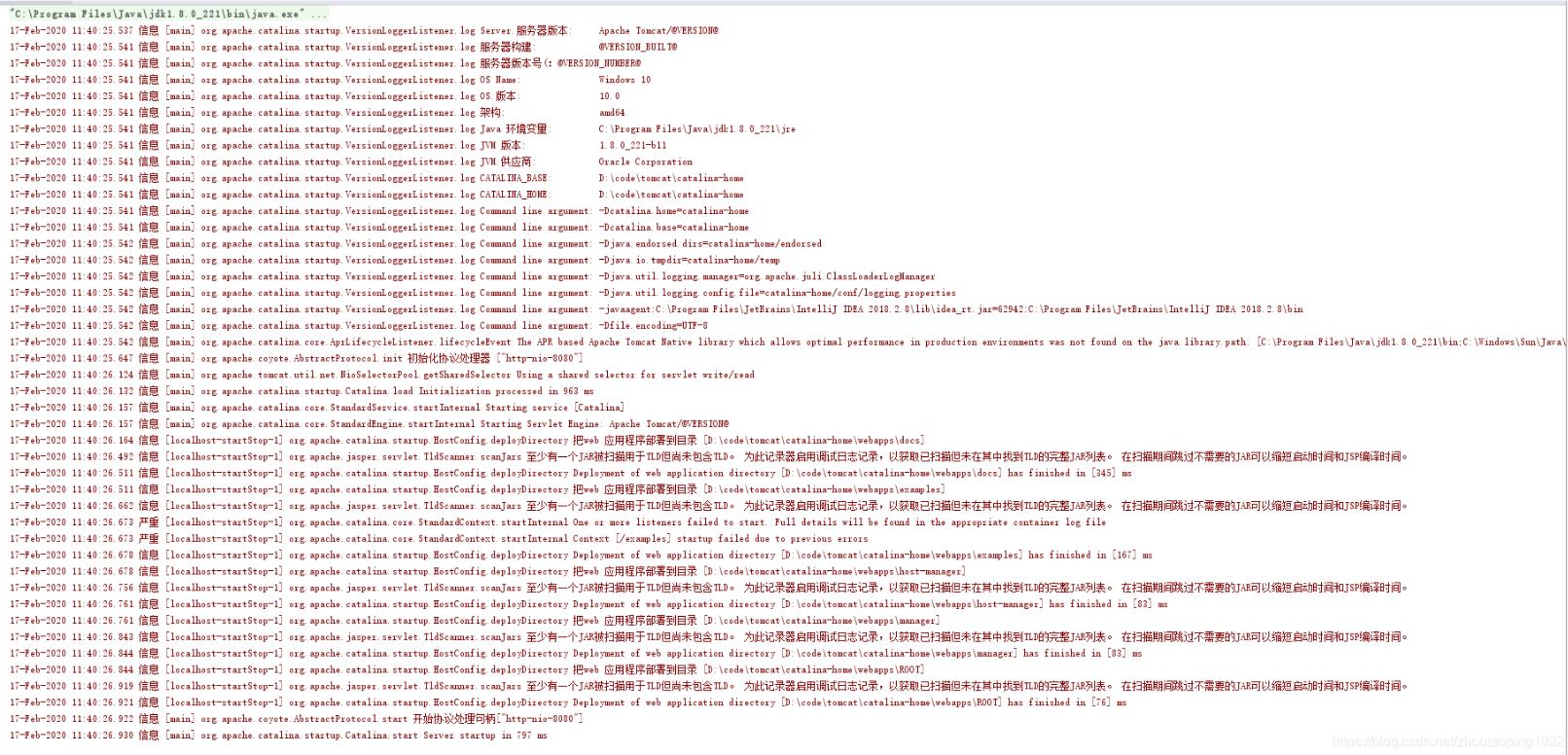
嘗試完所有方法后,控制臺日志亂碼問題并沒有解決,如圖:

仔細觀察后,發現日志左邊的日志等級”信息”和”嚴重”之類的中文亂碼解決了,但是日志中還有亂碼。
感覺應該是代碼的問題,于是決定debugger代碼,先從日志的第一行開始。
17-Feb-2020 10:10:08.585 信息 [main] org.apache.catalina.startup.VersionLoggerListener.log Server.æœåŠ¡å™¨ç‰ˆæœ¬: Apache Tomcat/@VERSION@
找到org.apache.catalina.startup.VersionLoggerListener類的log()方法,打斷點一步一步跟蹤
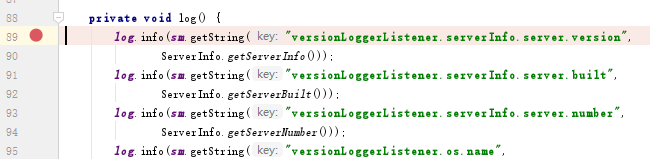
最終發現所有的值存在了PropertyResourceBundle類的lookup的map集合中,集合中的數據已經亂碼了。

于是繼續debugger查看lookup的加載,通過源碼查看lookup集合中的數據是從properties文件中讀取出來的。查看該properties文件編碼也是UTF-8。于是繼續查看源碼。
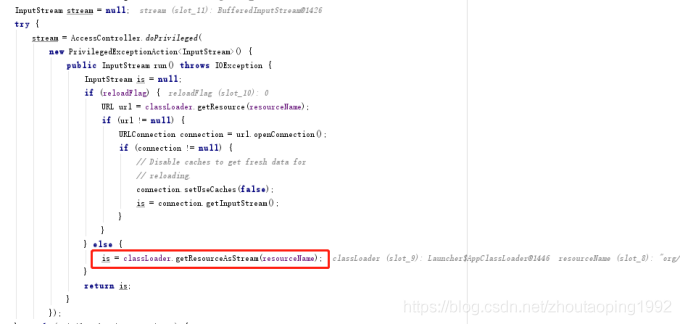
ResourceBundle中的is = classLoader.getResourceAsStream(resourceName);加載的這個properties文件

再通過PropertyResourceBundle構造方法加載的數據。
正準備修改這塊代碼時,發現這竟是JDK中的類,無法修改。(后來才知道ResourceBundle是用來做國際化的)。
后來查資料知道了:在java中, 讀取文件的默認格式是iso8859-1, 而我們中文存儲的時候一般是UTF-8. 所以導致讀出來的是亂碼。
解決方案有兩種:
1、使用JDK下的工具native2ascii.exe將properties文件轉為Unicode編碼。轉換后如圖:

2、在代碼中獲取到了值之后手動重新編碼解碼下
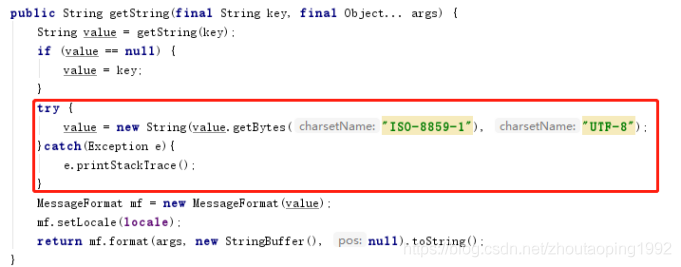
try {
value = new String(value.getBytes("ISO-8859-1"), "UTF-8");
}catch(Exception e){
e.printStackTrace();
}
經過測試,兩種方法都可以解決問題。
因為tomcat中properties文件過多,我采用了第二種方法,修改了tomcat源碼,修改如下:
1)org.apache.tomcat.util.res.StringManager類中的getString(final String key, final Object... args)方法。
2)org.apache.jasper.compiler.Localizer類的getMessage(String errCode)方法
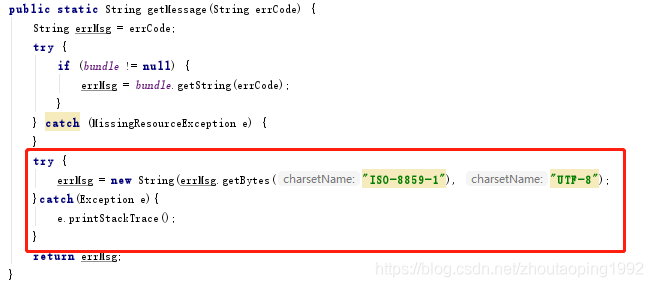
至此,亂碼問題解決
總結
到此這篇關于一次tomcat源碼啟動控制臺中文亂碼調試過程記錄的文章就介紹到這了,更多相關tomcat源碼啟動控制臺中文亂碼內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
