現如今,智能語音技術在移動終端上的應用極為熱門,語音對話機器人、語音助手、互動工具等應用層出不窮,那么智能語音技術是什么?其發展過程有哪些難點?發展過程中要注意哪些問題呢?
首先,我們以車載語音系統為例展開討論:
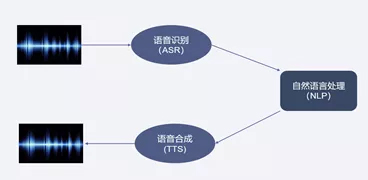
這個過程是怎樣實現的?首先,車載語音系統把聽到的聲音轉化成文字,然后理解內容,最后做出響應策略,并把響應策略轉化成語音。
上述過程體現了以下核心能力:
音轉字,也就是自動語音識別(ASR),讓機器通過識別和理解過程把語音信號轉化為相應的文本或命令的技術。
字轉音,即從文本到語音(TTS),是把計算機中任意出現的文字轉換成自然流暢的語音輸出。
自然語言處理(NLP),用計算機來處理、理解以及運用人類語言,讓人與計算機之間進行有效通訊。所謂自然乃是寓意自然進化形成,是為了區分一些人造語言,如C、C++、Java等人為設計的計算機語言。
ASR是讓機器實現聽的能力,而TTS是讓機器實現說的能力,結合自NLP的思考運算,理解并處理文本,即組成了人機交互的基本能力。
語音交互的基本模型
智能語音技術除了基本的語音技術,還主要依托于信息系統技術和文本處理技術。如果缺乏強大的計算能力以及更高級算法模型的前提條件,語音識別及分析技術終究是實驗室以及小眾場景領域的理論成果。
在過去的幾年,硬件技術以及云計算快速發展,計算機算力一直在提升,加上人工神經網絡算法的支持,讓語音的訓練變得越來越容易和高效。以往可能需要數周甚至數月時間的訓練過程被縮短到數天乃至數小時,使得各種語音應用變得隨用可取,極大加速了智能語音應用的蓬勃發展。
語音識別技術由來已久,但在很長一段時間都沒有很成熟的應用出現。在技術上要準確地識別一段語音,其實是件非常困難的事情,除了不同語種的區別,方言口音各異、新詞新語的涌現等也對識別準確率造成較大的影響。
許多國外英語環境下非常優秀的智能語音廠商,其技術應用表現在英語環境下非常不錯。但對于中文環境,一開始有點水土不服,其實就是中文語音的數據訓練太少導致。很多同事在調研或了解某個實際語音應用產品時,發現其方言識別能力逐漸增強,為什么會有這樣的結果呢?其實是訓練了大量的數據。
隨著互聯網的快速發展,以及手機等移動終端的普及應用,各AI語音公司可以從多個渠道獲取大量文本或語音方面的語料,這為語音識別中的語言模型和聲學模型訓練提供了豐富的資源,使得構建通用大規模語言模型和聲學模型成為可能。在語音識別中,訓練數據的匹配度和豐富性是推動系統性能提升的最重要因素之一。
相對十年前的情況來看,目前絕大部分語音識別技術的翻譯準確率都已達較高水平,在噪音處理、語氣語調、語義理解等方面均已大大提升,而最終能力上的差異關鍵在于:一,是否擁有核心的專利技術與能力;二,是否有足夠多的商業落地場景和實施經驗。
人工智能時代,智能語音已經脫離簡單的信息查詢功能,通過與內容服務的深度融合,拓展出各種新產品、新應用和新服務,進而帶動智能語音向垂直行業更深入地拓展。
語音交互作為人機交互的重要演進方向,正逐步滲透到人們的日常生活與應用當中,構建一種全新的信息生活方式。
普強多年來一直以語音為中心,專注金融大數據、AI芯片、智能汽車領域。回過頭來看普強的成功經驗,語音在產品化的過程中,必須與真實使用場景緊密貼合,符合不同目標群體對于語音產品實時性和準確性的需求。同時,由于不同的環境具有不同的聲音特質針對化處理,普強在降噪、方言、遠場所需要的解決方案也頗有建樹。
智能語音在行業及商業上的落地需要腳踏實地做實際的事情,解決真實業務上的痛點。
關于智能語音技術的應用和落地,我們將進一步進行討論。