場景描述:語音合成解決的主要問題就是如何將文字信息轉化為可聽的聲音信息,涉及語言和語音兩部分。TTS技術(又稱文語轉換技術)隸屬于語音合成,它是將計算機自己產生的、或外部輸入的文字信息轉變為可以聽得懂的、流利的漢語口語輸出的技術。
關鍵詞:多語言語音合成和跨語言語音克隆
我們知道目前端到端神經TTS模型已經可以實現對說話者身份和未標記的語音屬性(如韻律)的控制。當使用language-dependent輸入表示或模型組件時,特別是當每種語言的訓練數據量不平衡時,擴展這些模型以支持多種不相關的語言并非易事。例如,在漢語和英語等語言之間的文本表示沒有重疊。此外,收集雙語者的錄音也很昂貴。因此,最常見的情況是訓練集中的每個說話者只說一種語言,所以說話者的身份與語言是完全相關的。這使得在不同語言之間語音轉換變得困難。此外,對于外來詞或共享詞的語言,如西班牙語(ES)和英語(EN)中的專有名詞,同一文本的發音可能不同。當經過簡單訓練的模型有時為特定的說話者生成重音時,這就更加難以捉摸。
針對以上問題,最近學者們提出了一種基于Tacotron(中文語音合成)的多人多種語言文本到語音(TTS)的合成算法。
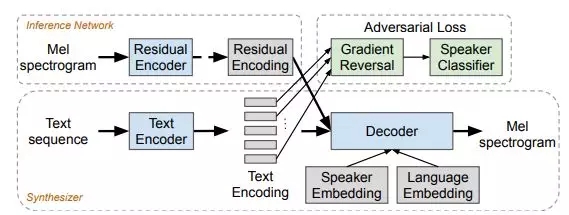
這種算法能夠在多種語言中生成高質量的語音。此外,模型是能夠跨語言傳遞聲音。模型結構采用基于注意力機制的序列到序列模型,根據輸入文本序列生成倒譜梅頻(log-mel,來自MFCC梅爾頻率倒譜系數)圖幀序列。
該模型是通過使用音位輸入表示來設計的,以激勵跨語言的模型容量共享。它還包含了一個對抗性的損失,以幫助理清它的說話者表示。通過對每種語言的多名使用者進行訓練,加入自動編碼輸入,并在訓練期間來幫助穩定注意力,從而進一步擴大了訓練規模。
經過計算,實現了語音克隆和重音控制效果的可視化。嵌入向量集群聚在一起(左下角和右下角),這意味著當說話者的原始語言與嵌入的語言匹配時,無論文本語言是什么,都會有很高的相似性。然而,使用文本中的語言ID(正方形),修改說話者的口音使其能夠流利地說話,與母語和口音(圓形)相比,會損害相似性。
該模型對三種語言的高質量語音合成和語音訓練的跨語言傳輸具有重要的應用潛力。例如,不需要任何雙語或并行語言的訓練,它就能夠使用英語使用者的聲音合成流利的西班牙語。此外,該模型在學習說外語的同時還會適量調節口音,并對代碼切換有基本的支持。
在未來的工作中,學者們還將計劃研究擴大利用大量低質量培訓數據的方法,并支持更多的使用者和語言。
論文鏈接:https://arxiv.org/pdf/1907.04448.pdf