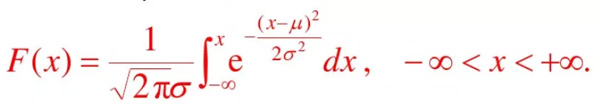很多人將座席規模作為衡量預測外呼的一個標準,即座席數量越多,預測外呼的技術難度越大。
這也是一個誤解,誤解產生的原因是對預測算法的不了解。
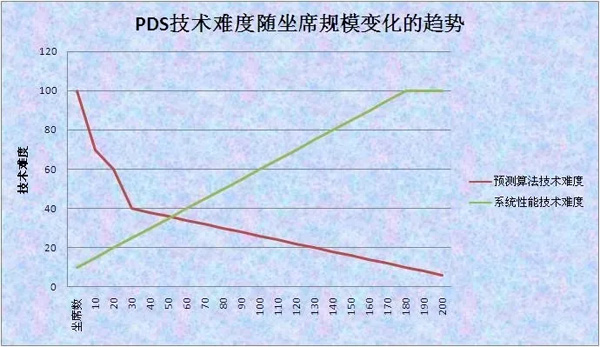
1、奇怪的曲線圖
實際上是30座席以下的預測外呼對預測算法技術要求很高,100座席以上,對呼叫中心本身性能要求很高。
下面這張圖形象的說明技術難度隨座席規模變化的趨勢。
系統性能技術難度非常容易理解,我們主要談一下預測算法的技術難度。
2、預測算法基礎—概率論
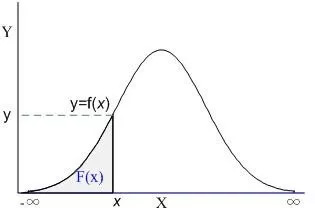
大學都學過,這下面這張圖都見過,有用啊,就算你什么都不明白,只需要明白一個規律:數量越大,公式越準。
發現對于單個座席來說,座席人員在一段時間區間內外呼通話時長呈正態分布;用戶接通電話的時長是呈正態分布。
如下圖所示:
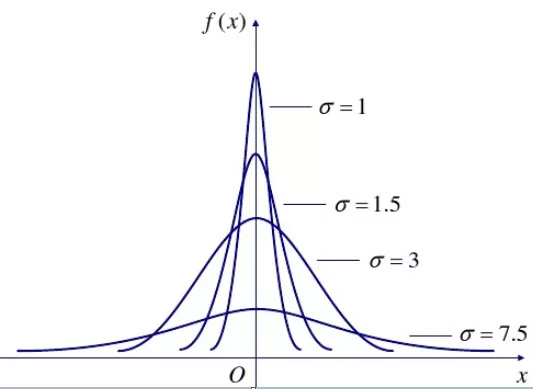
正態分布有兩個關鍵參數。
第一參數是服從正態分布的隨機變量的均值(μ)。第二個參數是此隨機變量的方差(σ^2)。服從正態分布的隨機變量的概率規律為與μ鄰近的值的概率大,而離μ越遠的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。
通過概率密度函數,可以計算出正態分布曲線中每一點的概率。概率密度函數的公式如下:
在實際應用中,正態分布圖兩端的點要被忽略。也就是不考慮概率極小事件。從而獲得一個概率區間。只在這個區間內取點。
3、預測算法的參數
預測算法的參數主要有三:
很不巧,這些都是服從正態分布的概率論。數量越多,準確率越高。
這也是為什么30座席以下的預測外呼效果很可能不好的原因。
4、此誤解的危害場景
誤解的危害場景我見過不少:
1、客戶要求廠商建設一個5座席的預測外呼先測試一下;
2、客戶認為因為一個廠商5座席的預測外呼效果不好,50個座席的預測外呼就會更差勁了;
3、客戶計劃是50座席的預測外呼,但是分成10個組,每5個座席一個組,獨立運行。