京東商品搜索引擎是搜索推薦部自主研發的商品搜索引擎����,主要功能是為海量京東用戶提供精準、快速的購物體驗�����。雖然只有短短幾年的時間��,我們的搜索引擎已經經過了多次618店慶和雙11的考驗�,目前已經能夠與人們日常使用的如谷歌��、百度等全文搜索引擎相比,我們的產品與其有相通之處,比如涵蓋億級別商品的海量數據����、支持短時超高并發查詢���、又有自己的業務特點:
1��、海量的數據,億級別的商品量;
2����、高并發查詢��,日PV過億;
3、請求需要快速響應����。
搜索已經成為我們日常不可或缺的應用����,很難想象沒有了Google�����、百度等搜索引擎���,互聯網會變成什么樣��。京東站內商品搜索對京東�,就如同搜索引擎對互聯網的關系���。
他們的共同之處:1. 海量的數據�,億級別的商品量�;2. 高并發查詢,日PV過億;3. 請求需要快速響應�。這些共同點使商品搜索使用了與大搜索類似的技術架構����,將系統分為:1. 離線信息處理系統�����;2. 索引系統�����;3. 搜索服務系;4.反饋和排序系統。
同時�,商品搜索具有商業屬性�,與大搜索有一些不同之處:1. 商品數據已經結構化����,但散布在商品、庫存、價格�����、促銷�、倉儲等多個系統;2. 召回率要求高,保證每一個正常的商品均能夠被搜索到��;3. 為保證用戶體驗�,商品信息變更(比如價格、庫存的變化)實時性要求高,導致更新量大��,每天的更新量為千萬級別�;4. 較強的個性化需求,由于是一個相對垂直的搜索領域,需要滿足用戶的個性化搜索意圖�,比如用戶搜索“小說”有的用戶希望找言情小說有的人需要找武俠小說有的人希望找到勵志小說�。
另外不同的人消費能力�、性別、對配送時間的忍耐程度、對促銷的偏好程度以及對屬性比如“風格”�、“材質”等偏好不同�����。以上這些需要有比較完善的用戶畫像系統來提供支持�。
總體架構圖
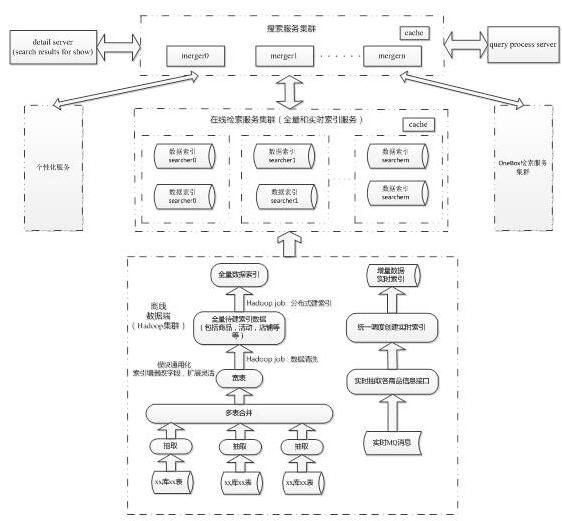
搜索服務集群:由很多個merger節點組成的集群。接收到查詢query后����,將請求通過qp觸發有策略地下發到在線檢索服務集群和其他服務集群�,并對各個服務的返回結果進行合并排序��,然后調用detail server包裝結果���,最終返回給用戶�����。
query processor server:搜索query意圖識別服務。
在線檢索服務集群:由很多個searcher節點組成����,每個searcher列對應一個小分片索引(包含全量數據和實時增量數據)�����。
detail server:搜索結果展示服務。
索引生產端:包含全量和增量數據生產���,為在線檢索服務集群提供全量索引和實時索引數據。
離線信息處理系統
由于商品數據分布在不同的異構數據庫當中有KV有關系型數據庫���,需要將這些數據抽取到京東搜索數據平臺中�,這分為全量抽取和實時抽取��。
對于全量索引��,由于商品數據散布于多個系統的庫表中����,為了便于索引處理,對多個系統的數據在商品維度進行合并���,生成商品寬表。然后在數據平臺上�����,使用MapReduce對商品數據進行清洗�����,之后進行離線業務邏輯處理��,最終生成一份全量待索引數據。
對于實時索引���,為了保證數據的實時性,實時調用各商品信息接口獲取實時數據���,將數據合并后采用與全量索引類似的方法處理數據,生成增量待索引數據��。
索引系統
此系統是搜索技術的核心�,在進入這個系統之前,搜索信息仍然是以商品維度進行存儲的��。索引系統負責生成一種以關鍵字維度進行存儲的信息�,一般稱之為倒排索引。
此系統對于全量和增量的處理是一致的��,唯一的區別在于待處理數據量的差異����。一般情況下,全量數據索引由于數據量龐大�,采用Hadoop進行;實時數據量小,采用單機進行索引生產。
搜索服務系統
搜索服務系統是搜索真正接受用戶請求并響應的系統。這個系統最初只有1列searcher組成在線檢索服務。由于用戶體驗的需要,首先增加Query Processor服務,負責查詢意圖分析����,提升搜索的準確性���。隨著訪問量的增長�����,接著增加緩存模塊,提升請求處理性能。接著隨著數據量(商品量)的增長,將包裝服務從檢索服務中獨立出去���,成為detail server服務。數據量的進一步增長,對數據進行類似數據庫分庫分表的分片操作���。這時候,在線檢索服務由多個分片的searcher列組成。自然而然�����,需要一個merger服務���,將多個分片的結果進行合并���。至此�����,搜索基礎服務系統完備����。
之后���,無論是搜索量的增長或者數據量的增長��,都可以通過擴容來滿足�。對于618���、1111之類的搜索量增長����,可通過增加每個searcher列服務器的數量來滿足。而對于商品數據的不斷增加,只需要對數據做更多的分片,相應地增加searcher列來滿足��。
搜索服務系統內部的處理流程如下:
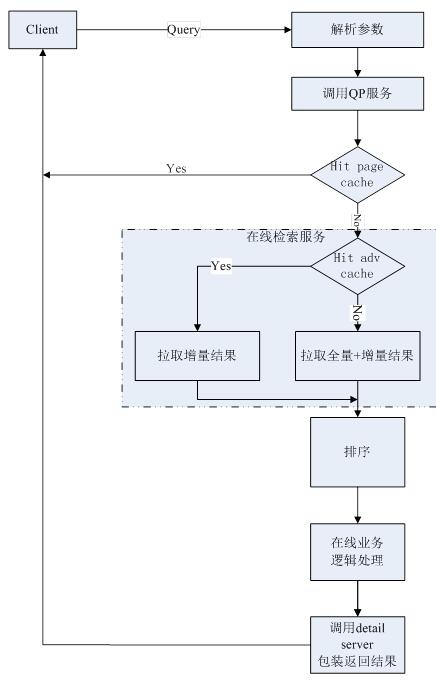
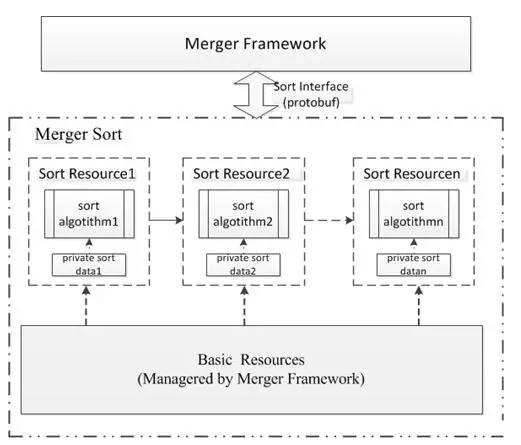
在這個流程中�����,緩存模塊和拉取結果模塊非常穩定��。而排序模塊和在線業務邏輯處理模塊經常需要改動。架構需要穩定,高效和通用��。排序業務特點是實驗模型多����,開發迭代速度快,講求效果����。為了解決這一沖突���,需要將排序業務與架構分離����,以動態鏈接庫的方式集成到搜索整體架構中����,具體包括文本策略和其他策略兩個維度的相關性��,文本策略相關性集成在searcher當中����;其他策略相關性(包括反饋�����,個性化和業務調權等等)集成在merger當中�。實現架構與排序業務各司其職����,互不影響干擾。
反饋和排序系統反饋系統主要包含用戶行為數據的實時收集�����、加工���,并將數據存儲到數據集市當中���,并對這些數據進行特征提取�����,排序最主要考核的線上指標是UV價值和轉化率��,所以還會利用這些數據根據優化目標構建起標注數據。然后基于機器學習的排序系統會針對特征構建出模型����。京東排序模型是每天更新的訓練之前大概半年的數據。京東搜索在基于模型的排序基礎之上����,上層還會有一層規則引擎���,比如保障店鋪和品牌的多樣性���,以及京東戰略扶持的品牌等都通過業務引擎來實現���。一般基于機器學習的排序模型需要較長期的投入但是模型更加健壯不容易被作弊手段找到漏洞����,并且可以讓轉化率和UV價值可持續的提升。 規則引擎主要是為了快速反應市場�����。
針對雙11的性能優化
1.故障秒級切換
今年搜索集群做到了三機房部署����,任何一個機房出現斷網、斷電等問題可以秒級將流量切換到其它機房����。并且搜索的部分應用部署到了彈性云上���,可以進行動態擴容��。
2.大促期間索引數據實時更新
每年大促由于商品內容等信息更改頻繁,涉及千萬級的索引寫操作����,今年針對索引結構進行了調整徹底消滅掉了索引更新存在的一切鎖機制,商品新增和修改操作變為鏈式更新。使大促期間商品的索引更新達到了妙極���。
3.大促期間的個性化搜索不降級
往年大促期間由于流量在平時5倍以上,高峰流量會在平時的7倍,為了保障系統穩定,個性化搜索都進行了降級處理�。今年針對搜索的緩存進行了針對性的優化���,實現了三級緩存結構�����。從底向上分別是針對term的緩存,相關性計算緩存和翻頁緩存。最上層的翻頁緩存很多時候會被用戶的個性化請求擊穿����,但是底層的相關性緩存和term緩存的結果可以起到作用�����,這樣不至于使CPU負載過高。
京東在電商搜索方面產品和技術的創新
1��、個性化搜索
個性化之前的搜索對于同一個查詢��,不同用戶看到的結果是完全相同的�����。這可能并不符合所有用戶的需求。在商品搜索中,這個問題尤為特出����。因為商品搜索的用戶可能特別青睞某些品牌�、價格��、店鋪的商品�,為了減少用戶的篩選成本�����,需要對搜索結果按照用戶進行個性化展示。
個性化的第一步是對用戶和商品分別建模�,第二步是將模型服務化��。有了這兩步之后,在用戶進行查詢時��,merger同時調用用戶模型服務和在線檢索服務�����,用戶模型服務返回用戶維度特征����,在線檢索服務返回商品信息,排序模塊運用這兩部分數據對結果進行重排序���,最后給用戶返回個性化結果。
2、整合搜索
用戶在使用搜索時����,其目的不僅僅是查找商品���,還可能查詢服務���、活動等信息���。為了滿足這一類需求����,首先在Query Processor中增加對應意圖的識別�����。第二步是將服務、活動等一系列垂直搜索整合并服務化��。一旦QP識別出這類查詢意圖����,就條用整合服務,將對應的結果返回給用戶�����。
3��、情感搜索
情感搜索在于盡可能滿足更多的搜索意圖�����,這需要在后臺構建一個強大的知識庫體系。比如從海里評論中挖掘有意義的標簽“成像效果好的相機”��、“聚攏效果好的胸罩”�、“適合送丈母娘”等,將這些信息一同構建到索引中去比如搜索“適合送基友的禮物”結合搜索意圖分析相關的結果可以搜索出來�。另外也可以從外部網站抓取有價值信息輔助構建知識庫體系�。
4�、圖像檢索
很多時候用戶并不知道如何描述一個商品。通過搜索意圖分析����、情感分析可以盡可能挖掘搜索意圖���,很多時候用戶根本無法描述�,比如在超市看到一個進口食品或者一件時尚的衣服����,可以通過拍照檢索迅速在網上找到并比較價格���,另外看到同事穿著一件比較喜歡的衣服也可以通過拍照檢索來找到����。目前京東正在開始展開這方面的開發。離線方面主要通過CNN算法,對圖片進行主題提取、提取相似特征、相同特征提取�。引擎端主要是和搜索引擎類似的技術�。圖像搜索未來將可以開辟一個新的電商購物入口��。京東目前正在研發新的圖像檢索引擎�����。
以上就是針對京東的商品搜索系統架構設計進行的詳細探討,希望對大家有所啟發��。
