TA(Tencent Analytics,騰訊分析)是一款面向第三方站長的免費網站分析系統,在數據穩定性����、及時性方面廣受站長好評����,其秒級的實時數據更新頻率也獲得業界的認可。本文將從實時數據處理����、數據存儲等多個方面帶你深入探尋TA的系統架構及實現原理�。
網站分析(Web Analytics)主要指的是基于網站的用戶瀏覽行為��,對網站的點擊流數據和運營數據進行分析����,以監控網站的運營狀況�����,為網站的優化提供決策依據�。網站分析系統已成為站長日常運營必不可少的工具�����,業界比較流行的網站分析系統主要有Google Analytics、CNZZ和百度統計等產品。
TA作為網站分析產品的后起之秀在社區分析、用戶畫像��、網站工具等多方面形成了自己的特色���,其秒級的實時數據更新頻率更是業界翹楚�����。在數據穩定性���、準確性和及時性方面���,TA在站長圈也是享有良好的口碑����。隨著接入業務量的不斷發展�����,TA日均需要處理和計算的數據量達到TB級��。如此龐大的數據量想要達到秒級實時且保證系統的高可用并非件易事。
TA的實時計算框架借鑒了一些業界流行的流式計算系統的思路。雖然在構建系統中遇到了一些問題,但由于海量數據的實時處理���、實時存儲具備一定的典型性與通用性,所以將TA的解決方案分享出來,希望能給大家一些啟示����。
基本原理及系統架構
TA的基本原理是通過嵌入站長網站的JavaScript腳本收集用戶訪問行為數據�,并發送TA采集集群��,采集集群收到數據后將其過濾、編碼����、格式化后繼續向后分發�����。數據處理集群負責按照業務邏輯計算數據,并將計算結果“寫入”到數據存儲集群���,最后將結果數據展現給廣大站長使用。TA的基本原理如圖所示���。
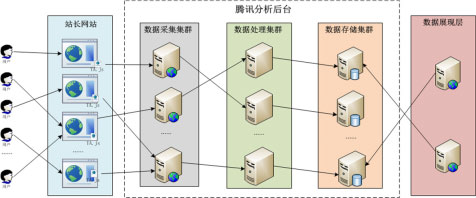
TA后臺是一套完整的數據流處理系統:由JavaScript采集的用戶行為數據像川流不息的河水一樣流入TA后臺,經過清洗���、計算后源源不斷地流出到TA存儲集群,供用戶瀏覽和查詢��。TA的具體架構及核心部件如圖所示。
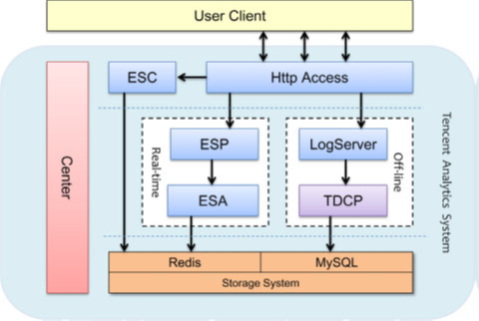
TA的后臺分為離線和實時兩部分:實時部分負責系統的主要功能計算,數據更新頻率為秒級�����;離線部分負責系統復雜的關聯分析及跨天計算�,數據更新頻率為天級。
Http Access:主要負責HTTP協議的解析,數據的清洗及格式化����。
ESC:Event Streaming Coder�,主要負責將系統不可枚舉的數據類型編碼成為整型�����,并將對應關系持久化����。
ESP:Event Streaming Processor�����,主要負責將數據按照站點、UID重新組織并計算PV�、UV�、停留時長和蹦失率等網站分析指標��。
ESA:Event Streaming Aggregator��,主要負責匯總ESP計算后的數據按照站點,并寫入到Redis����。
Center:系統的中心節點��,負責系統配置、數據路由管理���,并承擔容災切換功能。
Logserver:負責將Access收集到的數據以字符串形式寫入文件��,并上傳到TDCP上�����。
TDCP:騰訊分布式計算平臺�,負責離線數據的計算���,并由腳本將結果數據寫入MySQL中�����。
實時解決方案
前TA日均需要處理幾十萬網站的上TB級數據�����,處理過后的URL個數仍有上億條���,系統存儲的key個數超過十億����。如何高效、低延遲地處理如此大量的業務數據是TA實時系統面臨的主要挑戰。TA解決方案的主要思路可以概括為數據全二進制化���、計算全內存化、存儲NoSQL化��。下面就實時計算和實時存儲這兩大子系統進行深入的討論��。
實時計算
對于計算子系統��,我們參考了Hadoop、S4和Storm等開源項目��,力圖設計為一個較為通用�����,擴展性較強的全內存實時Event處理系統(或者套用流行的術語稱為流式實時Event處理系統)���。對于這樣的一個系統����,我們設計支持的典型輸入輸出流程大致如圖所示。
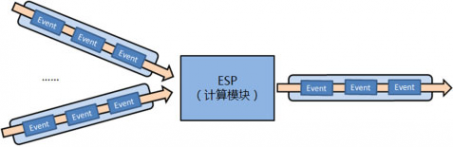
實時計算系統的設計要點在數據組織�����、協議和增量計算模型上�����。
數據組織。萬物皆int,考慮到內存以及計算過程的性能需求�,我們將所有非int的數據類型轉化為int�?��?梢悦杜e的數據類型���,將其配置化映射為唯一int��;不可枚舉的數據類型�����,則利用MD5算法近似得到唯一的int。例如,頁面URL屬于不可枚舉的類型,則預處理通過MD5算法近似得到唯一的int���;UserAgent里的瀏覽器類型字符串則屬于可枚舉的數據,則預先配置化映射為int。這個方法節省了較多內存,提高了整個系統的計算性能����。
協議����。協議層面上�����,我們首先設計實現了一種可擴展的Event結構�����,這種Event結構支持半自動化的序列化/反序列化機制(參考自msgpack的設計)和緊湊的二進制編碼(基于Zigzag編碼�,參考Protobuf的實現)。這種Event結構在流式高性能I/O(網絡傳輸和持久化)方面表現得相當良好�����。實時計算子系統被設計為可以擴展支持任意的Event實現�。
增量計算模型。增量計算模型�,指的是基本計算過程����,被定義為以下三部分(如圖所示)
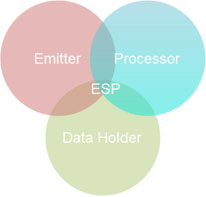
Processor:負責具體業務邏輯的計算處理���。
Data Holder:負責保存增量結果數據���,以及計算依賴的中間狀態數據�����。
Emitter:負責定期輸出清空增量計算結果����。
具體到流程方面����,分為以下三步(如圖所示)。
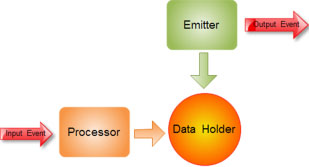
接收Event���,計算處理—Processor�����。
保存計算結果以及計算依賴中間數據—DataHolder��。
定時觸發輸出時間片內計算結果���,清空計算結果—Emitter����。
增量計算模型弱化了分布式系統中單臺機器的事務狀態�,相應地簡化了分布式計算系統的實現,同時也提高了整個系統的性能�����。
實時存儲
在TA系統中�,實時存儲的數據都是需要通過Web展示層讀取的統計數據。這類數據存在兩個典型特點�。
頻繁更新寫��。更新頻度視系統實時性而定,每條統計結果更新頻度最快可以達到1秒����。
少量讀取���。“少量”是相對上述更新而言的�。同時根據業務邏輯����,可將統計數據劃分為兩類。
固定不變數據:主要是URL���、搜索關鍵詞等數據。這一部分數據理論上是在不停地增加�����,不會修改舊有數據��。
動態數據:主要是頻繁更新的結果統計數據。這一部分數據則需要不停地更新��。例如����,www.qq.com域名下的PV和UV統計結果。
考慮到上述的TA實時統計數據的特點����,我們選擇NoSQL實現我們的存儲系統���;同時����,針對兩類不同的數據類型�����,分別選用LevelDB和Redis來存儲����。
Redis
TA實時存儲的主要構件����。考慮到TA系統本身就是一個比較完善的分布式集群系統,因此我們需要的存儲構件是“not clustering, but sharding”。也就是說像HBase和MongoDB這樣的“重武器”并不適合TA���,而NoSQL數據庫中的“瑞士軍刀”Redis憑借其出色的性能走入我們的視野。同時TA的結果數據類型也比較豐富��,有像站點PV�、UV�����、VV和IP等Hash類型的數據��,也有像用戶訪問軌跡這樣set類型的“動態數據”����,而Redis豐富的數據結構很好地完成了這項任務�����。
選擇Redis的另一個原因是它足夠簡單且易于擴展�����。在實際應用的過程中,我們發現的問題都可以通過擴展Redis命令來解決。
例如�����,TA中有這樣的一種應用場景:為了消除ESA模塊的狀態�,存儲在Redis中的數據往往并不是最終的結果數據,而是還需要進一步運算的中間數據。像bounce rate這個指標(bouncerate=bounce session數/total session數)��,需要前臺查詢兩次再做一次運算后最終展示給用戶����。在高并發的情況下,無疑會影響系統的響應速度。
本著“移動計算,而不是移動數據”的原則�,我們對Redis的sort���、hmget命令進行了擴展使其支持四則運算��,成功地將原來的兩次查詢優化為一次���。擴展四則運算的另外一個目的是可以“通過計算換取存儲”�,例如需要將兩種類型加總成總和的類型數據,可以只存儲兩份�,加總數據“通過計算換取”���。
除了數據讀取���,數據的寫入也可以進行類似合并數據的優化����。例如���,TA在寫入URL的PV�����、UV�、VV����、IP、停留時長和bounce rate這6個指標時���,需要調用6次Redis命令。而實際上這6個指標是存儲在同一個Hash內的�����,通過擴展hmincrby命令��,支持將Hash的所有field一次更改��,便能將調用次數優化至一次����。上線之后也取得了良好的效果,峰值時的CPU利用率幾乎下降了一半�,同時也大幅提升了上層模塊ESA的吞吐量���。
LevelDB
它是Redis的有效補充���?��?紤]到Redis為內存數據庫�����,而使用內存的成本要高于硬盤�,因此選擇引入了基于磁盤存儲的LevelDB作為補充��。由于LevelDB的寫性能足夠好����,而讀性能也遠遠超過目前“在線少量讀取”的需求����,所以我們選擇LevelDB存儲“固定不變數據”。
在數據存儲的架構設計上����,由于實時數據服務與在線系統����,可靠性要求較高���,因此我們主要采取雙寫復制+Sharding的設計方法����。
雙寫復制�。所有的數據存儲都會至少同步寫兩份,以提高在線系統服務的可用性。
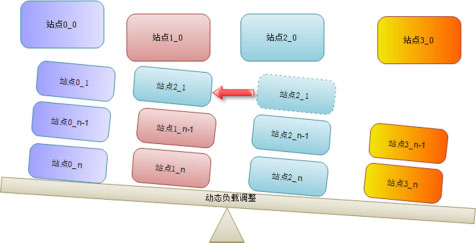
數據分片(Sharding)����。
基于域名:所有的數據以域名為單位組織分片�����;任何域名可以調整到任意分片中;單個域名數據原則上存儲在一個分片中。
動態調整(如圖所示):只調整分片策略����,不移動數據���;基于數據量計算分片負載��。
此外,針對分片集群數據的查詢,我們主要做了三項工作(如圖所示)。
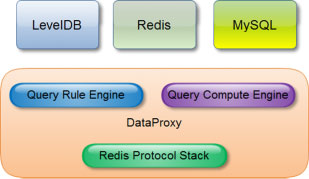
Redis Protocol Stack是一個較為完整的Redis協議棧,是上層應用的基礎�����。直接用Redis協議作為對外提供查詢的通用協議��,這樣外部用戶可直接通過目前各種Redis Client實現來查詢訪問數據�。Query Rule Engine是一個靈活的查詢引擎����。能夠根據規則智能地在多個Redis、LevelDB數據源中查詢,執行類join的操作;也簡單擴展支持其他的異構數據源,如MySQL、HBase等����。
Query Compute Engine是一個實時查詢計算引擎,能根據基礎查詢結果實時計算�。引入此部分的主要目的在于減少Redis數據空間占用�。
未來展望
目前TA雖然在后臺上已經做到數據秒級更新��,但展示方式仍為傳統的靜態方式�。后續TA會在數據的動態刷新上進行更多嘗試��,讓站長可以第一時間了解網站營銷效果��,時刻感受網站心跳。
