在分布式應用系統中,mongodb 已經成為 NoSQL 經典數據庫。要想很好的使用 mongodb,僅僅知道如何使用它是不夠的。只有對其架構原理等有了充分認識,才能在實際運用中使其更好地服務于應用,遇到問題知道怎么處理,而不是抓瞎抹黑。這篇文章就帶你進入 mongodb 集群的大門。
集群概覽
mongodb 相關的進程分為三類:
- mongo 進程 – 該進程是 mongodb 提供的 shell 客戶端進程,通過該客戶端可以發送命令并操作集群;
- mongos 進程 – mongodb 的路由進程,負責與客戶端連接,轉發客戶端請求到后端集群,對客戶端屏蔽集群內部結構;
- mongod 進程 – 提供數據讀寫的 mongodb 實例進程。
類比銀行服務,mongo 進程相當于客戶,mongos 進程是柜臺服務員,mongod 進程是銀行后臺實際處理業務的人員或者流程。客戶只需要和柜臺服務員溝通,告知辦什么業務,柜臺服務員將業務轉往后臺,后臺實際處理。
下圖是 mongodb 集群的一般拓撲結構。
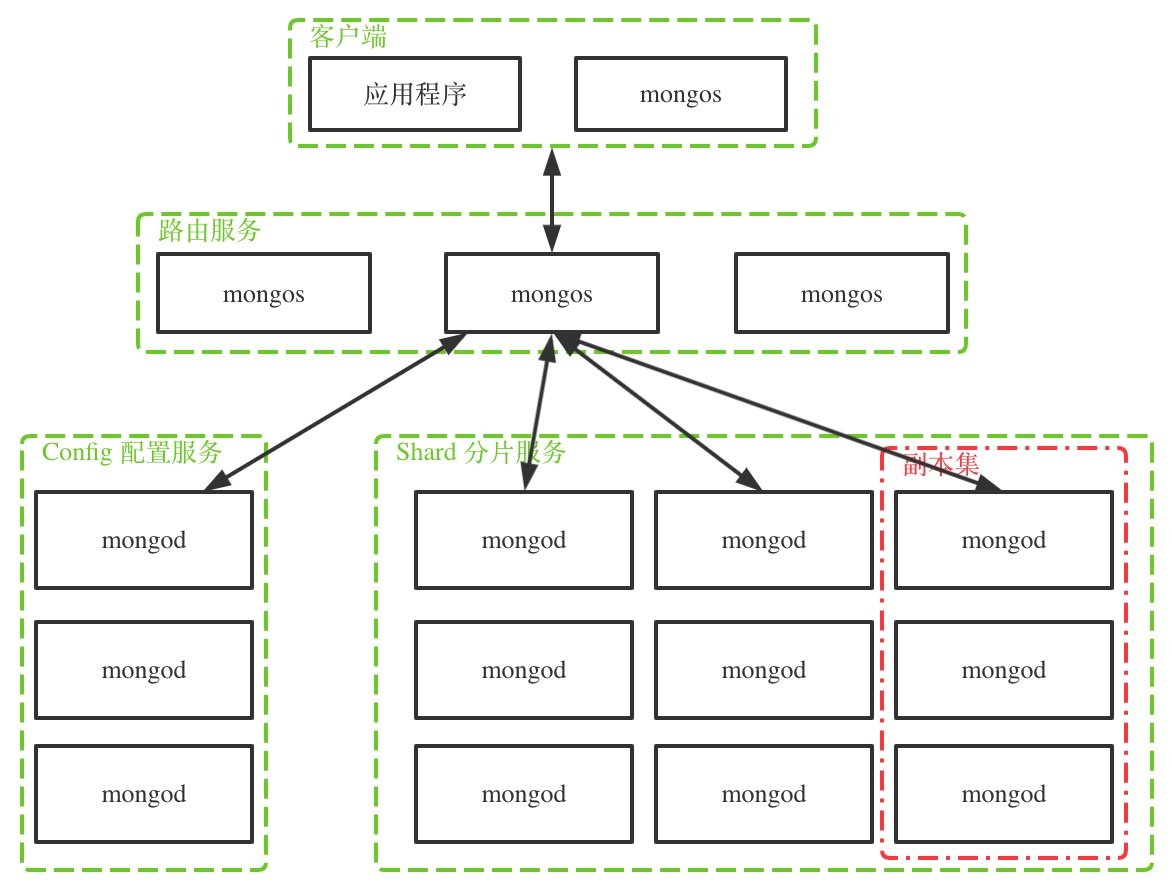
如圖,mongodb 集群的節點分為三類:
- mongos 路由節點:處理客戶端的連接,扮演存取路由器的角色,將請求分發到正確的數據節點上,對客戶端屏蔽分布式的概念;
- config 配置節點:配置服務,保存數據結構的元數據,比如每個分片上的數據范圍,數據塊列表等。配置節點也是 mongod 進程,只是它存儲的數據是集群相關的元數據;
- shard 分片節點:數據存儲節點,分片節點由若干個副本集組成,每個副本集存儲部分全體數據,所有副本集的數據組成全體數據,而副本集內部節點存放相同的數據,做數據備份與高可用。
還是拿銀行業務類比,當客戶辦理保單保存業務時,
- 柜臺服務員接受客戶的保單業務請求(mongos 路由節點接收客戶端的操作請求);
- 柜臺服務員查詢文件目錄系統查看該保單應該保存到哪個倉庫(mongos 節點與 config 配置節點通信,查詢相關操作數據在哪個分片節點);
- 知道哪個倉庫后,柜臺服務員將保單給倉庫管理員,倉庫管理員將保單放到指定倉庫中(mongos 節點將請求發送給數據所在分片節點,分片節點進行讀寫處理)。
mongos 路由服務
mongos 服務類似網關,連接 mongodb 集群與應用程序,對外屏蔽 mongodb 內部結構,應用程序只需要將請求發送給 mongos,而無需關心集群內部副本分片等信息。
mongos 本身不保存數據與索引信息,它通過查詢 config 配置服務來獲取,所以可以考慮將 mongos 與應用程序部署在同一臺服務器上,當服務器宕機時 mongos 也一起失效,防止出現 mongos 閑置。
mongos 節點也可以是單個節點,但為了高可用,一般部署多個節點。就像柜臺服務員一樣,可以有多個,相互之間沒有主備關系,都可以獨立處理業務。
需要注意的是,在開啟分片的情況下,應用程序應該避免直接連接分片節點進行數據修改,因為這種情況下很可能造成數據不一致等嚴重后果,而是通過 mongos 節點來操作。
config 配置服務
config 配置節點本質也是一個副本集,副本集中存放集群的元數據,如各個分片上的數據塊列表,數據范圍,身份驗證等信息。如下,可以看到數據庫 config,數據庫中集合保存了集群的重要元數據。
mongos> use config;
switched to db config
mongos> show collections;
changelog
chunks
collections
databases
lockpings
locks
migrations
mongos
shards
tags
transactions
version
一般情況下,用戶不應該直接變更 config 的數據,否則很可能造成嚴重后果。
shard 分片服務
分布式存儲要解決的是兩個問題:
隨著業務不斷發展,數據量越來越大,單機存儲受限于物理條件,必然要通過增加服務器來支持不斷增大的數據。所以分布式下,不可能全部數據存儲在一個節點上,必然是將數據劃分,部分數據放到這個節點,另外部分數據放到另外的節點上。也就是數據的伸縮性。
考慮高可用。如果同一份數據只存在一個節點上,當這個節點發生異常時,數據不可用。這就要求分布式下同一份數據需要存儲在多個節點上,以達高可用效果。
在 mongodb 集群中,數據的伸縮性通過分片集來實現,高可用通過副本集來實現。
如圖,全部數據為1-6,將其劃分為3部分,1-2為一個分片,3-4為一個分片,5-6為一個分片。每個分片存儲在不同的節點上。而每個分片有3個副本,組成副本集,每個副本都是獨立的 mongod 實例。
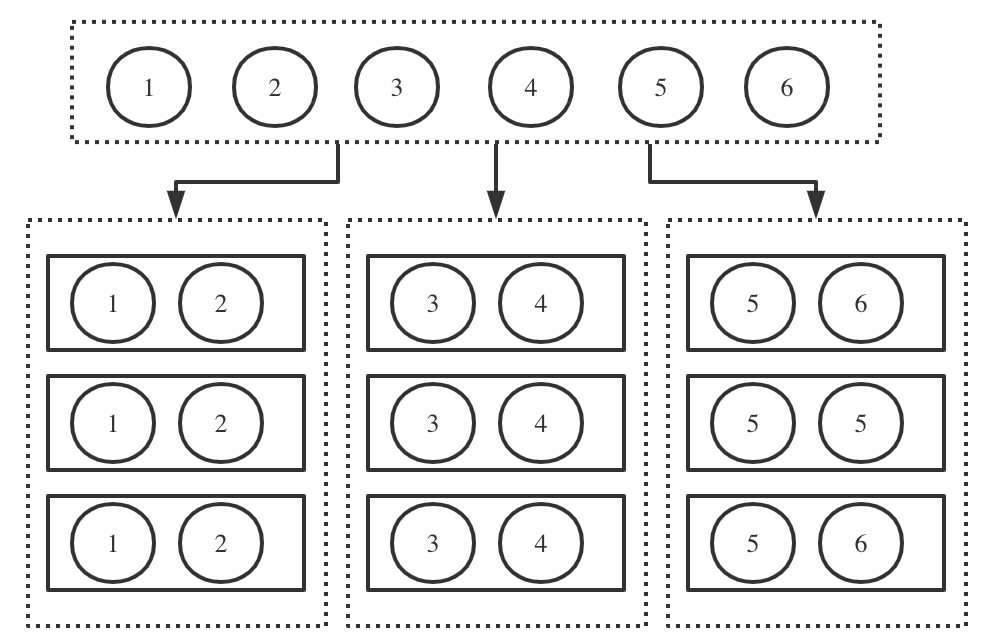
所以副本集是一個縱向概念,描述的是相同的數據存儲在多個節點上;而分片是一個橫向概念,描述的是全量數據被切成不同的片段,每個片段獨立存儲。這個片段就是分片,而分片通過副本集進行存儲。
副本集
副本集包含三種角色:
- 主節點(Primary)
- 副節點(Secondary)
- 仲裁節點(Arbiter)
一個副本集由一個主節點,多個副節點,0或多個仲裁節點組成。
主節點與副節點是數據節點。主節點提供數據的寫操作,數據寫到主節點后,會通過同步機制同步到副節點上。默認讀操作也由主節點提供,但是可以手動設置 read preference,優先從副節點讀取。
仲裁節點不是數據節點,不存儲數據,也不提供讀寫操作。仲裁節點是作為投票者存在,當主節點異常需要進行切換時,仲裁節點有投票權,但沒有被投票權。仲裁節點可以在資源有限的情況下,依然支持故障恢復。比如只有2個節點的硬盤資源,在這種情況下可以增加一個不占存儲的仲裁節點,組成“一主一副一仲裁”的副本集架構,當主節點宕掉時,副節點能夠自動切換。
節點間通過“心跳”進行溝通,以此知道彼此的狀態。當主節點異常不可用時,從其他有被投票權的節點中投票選出一個升級為主節點,繼續保持服務高可用。這里投票采取“大多數”原則,即需要多于總節點數一半的節點同意,才能被選舉成主節點。也因此不建議采用偶數個節點組成副本集,因為偶數情況下,如果發生半數節點網絡隔離,隔離的半數節點達不到“大多數”的要求,無法選舉產生新的主節點。
通過 rs.status() 可以查看副本集,參考《教你快速搭建 mongodb 集群》
分片集
分片就是將全部數據根據一定規則劃分成沒有交集的數據子集,每個子集就是一個分片,不同分片存放在不同節點上。這里有幾個問題:
- 劃分規則也就是分片策略是什么?
- 分片數據是如何存放的?
- 數據量越來越大,分片如何動態調整?
數據塊 Chunk
chunk 由多個文檔組成,一個分片中包含多個 chunk。chunk 是分片間數據遷移的最小單位。實際上,文檔是通過分片策略計算出應該存儲在哪個 chunk,而 chunk 存放在分片上。
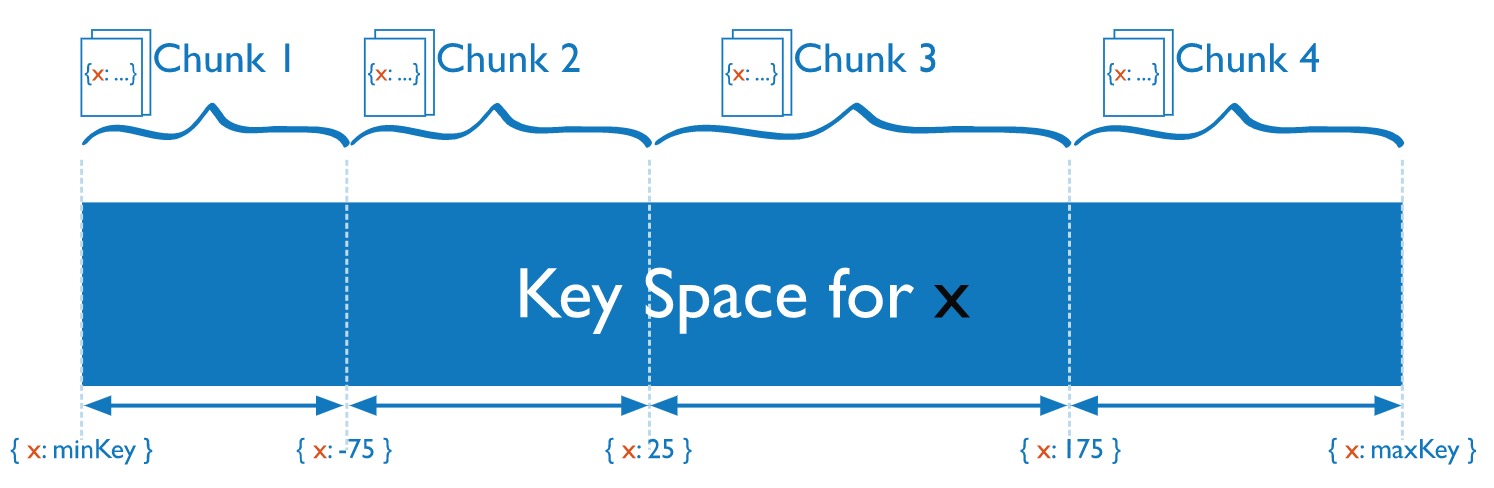
如圖,假設按照文檔的 x 字段值來進行分片,根據不同取值范圍存放在不同的數據塊,如25-175在 chunk 3上。
把書比作 mongodb 中的文檔,書柜比作數據塊,房間比作分片。每本書根據一定規則放到某書柜上,房間中有很多書柜。當某個房間的書柜太多,就需要以書柜為單位,遷移到相對比較寬松的房間。
chunk 的大小默認為 64MB,也可以自定義。chunk 的存在有兩個意義:
- 當某個 chunk 超過大小時,會觸發 chunk 分裂。
- 當分片間的 chunk 數不均衡時,會觸發 chunk 遷移。
chunk 遷移由 mongodb 的平衡器來操作,默認平衡器是開啟的,是運行在后臺的一個進程,也可以手動關閉。
可以通過下面命令來查看平衡器狀態:
chunk 的大小對集群的影響:
- 比較小時,chunk 數比較多,數據分布比較均勻,但會引起頻繁的數據塊分裂與遷移;
- 比較大時,chunk 數比較少,數據容易分散不均勻,遷移時網絡傳輸量大。
所以要自定義數據塊大小時,一定要考慮完備,否則將大大影響集群與應用程序的性能。
片鍵 Shard Key
mongodb 集群不會自動將數據進行分片,需要客戶端告知 mongodb 哪些數據需要進行分片,分片的規則是什么。
某個數據庫啟用分片:
mongos> sh.enableSharding(database>)
設置集合的分片規則:
mongos> sh.shardCollection(database.collection>,key>,unique>,options>)
# unique 與 options 為可選參數
例如,將數據庫 mustone 開啟分片,并設置庫中 myuser 集合的文檔根據 _id 字段的散列值來進行劃分分片。
sh.enableSharding("mustone")
sh.shardCollection("mustone.myuser",{_id: "hashed"})
這里劃分規則體現在 上, 定義了分片策略,分片策略由片鍵 Shard Key 與分片算法組成。片鍵就是文檔的某一個字段,也可以是復合字段。分片算法分為兩種:
- 基于范圍。如 設置為 id:1 表示基于字段 id 的升序進行分片,id:-1 表示基于字段 id 的倒序進行分片,字段 id 就是 shard key(片鍵)。當集合中文檔為空時,設置分片后,會初始化單個 chunk,chunk 的范圍為(-∞,+∞)。當不斷往其中插入數據到達 chunk 大小上限后,會進行 chunk 分裂與必要遷移。
- 基于hash。如上面的栗子, 設置為 _id:”hashed”,表示根據字段 _id 的哈希來分片,此時片鍵為 _id。初始化時會根據分片節點數初始化若干個 chunk,如3個分片節點會初始化6個 chunk,每個 shard 2個 chunk。
每個數據庫會分配一個 primary shard,初始化的 chunk 或者沒有開啟分片的集合都默認放在這個 primary shard 上。
分片策略的選擇至關重要,等數據量大了再更改分片策略將會很麻煩。分片策略的原則:
- 均勻分布原則。分片的目標就是讓數據在各個分片上均勻分布,數據的存取壓力也分解到各個分片上。比如以自增長的 id 升序為片鍵,會導致新數據永遠都寫在最后的 chunk 上,且 chunk 分裂與遷移也會落在該 chunk 所在分片上,造成該分片壓力過大。
- 大基數原則。集合的片鍵可能包含的不同值的個數,稱為基數。基數越大,數據就能劃分得更細。基數越小,chunk 的個數就有限。比如性別,只有男女,如果作為片鍵,最多兩個 chunk,等數據越來越大后,便無法橫向擴展。
- 就近原則。盡可能讓一次查詢的數據分布在同一個 chunk 上,這樣提升磁盤讀取性能。避免毫無意義的隨機片鍵,雖然分布均勻了,但每次查詢都要跨多個 chunk 才能完成,效率低下。
需要說明的是,mongodb 分片集群雖然比較完備,但是存在一些限制,如備份相對困難,分片集合無法做關聯查詢等。所以要根據實際業務來評估,如果副本集已經夠用了,不一定要進行分片存取。
以上就是深入了解MongoDB 分布式集群的詳細內容,更多關于MongoDB 分布式集群的資料請關注腳本之家其它相關文章!
您可能感興趣的文章:- MongoDB實現基于關鍵詞的文章檢索功能(C#版)
- 開源 5 款超好用的數據庫 GUI 帶你玩轉 MongoDB、Redis、SQL 數據庫(推薦)
- JAVA代碼實現MongoDB動態條件之分頁查詢
- MongoDB設計方法以及技巧示例詳解
- MongoDB數據庫基礎操作總結
- express+mongoose實現對mongodb增刪改查操作詳解
- win7平臺快速安裝、啟動mongodb的方法
- 使用Mongodb實現打卡簽到系統的實例代碼
- 淺析MongoDB 全文檢索
