聚簇,其實是相對于InnoDB這個數據庫引擎來說的,因此在將聚簇索引的時候,我們通過InnoDB和MyISAM這兩個MySQL的數據庫引擎展開。
InnoDB和MyISAM的數據分布對比
CREATE TABLE test (col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2));
首先通過以上SQL語句創建出一個表格,其中col1是主鍵,兩列數據均創建了索引。然后我們數據的主鍵取值為1-10000,按照隨機的順序插入數據庫中。
MyISAM的數據分布
MyISAM的數據存儲邏輯比較簡單,就是按照數據插入的順序創建出一個數據表格。直觀上來看如下圖:
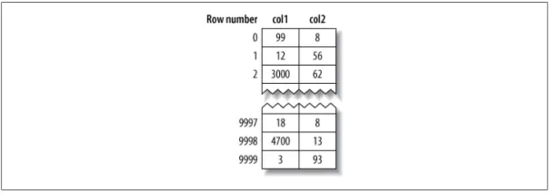
可以看出,數據就是按照插入的順序“一行一行”生成的。前面還會有一個行號的字段,用處就是在查找到索引的時候能夠快速地定位到該行索引的位置。
我們再來看一下具體的細節:
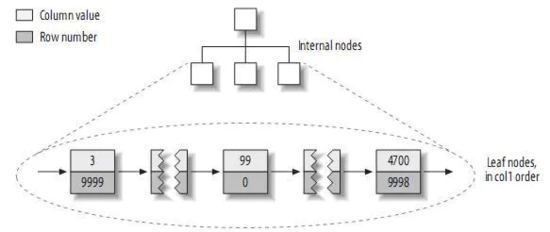
上圖展示的情況就是在MyISAM引擎下,按照主鍵建立的索引的具體實現。可以看出在主鍵按照順序排列在葉子結點上的同時,節點中還存儲著這個主鍵在數據庫表格中存在的具體的行號,正如我們上面所說的,這個行號可以幫助我們快速地定位到表中數據的位置,也可以把這個行號理解為一個指針,指向了這個主鍵所在的具體數據行。
那么如果我們按照col2建立索引呢?會有什么不同嗎?答案是不會的:
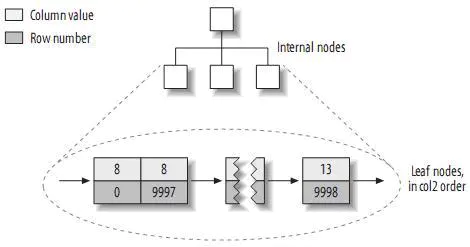
所以得到的結論就是在MyISAM中建立索引是否是主鍵索引其實是沒有區別的,唯一不同的就是這是一個“主鍵的索引”。
InnoDB的數據分布
因為InnoDB支持聚簇索引,所以會與MyISAM上的索引實現方式有所區別。
我們先看看基于主鍵的聚簇索引在InnoDB上的實現方式:

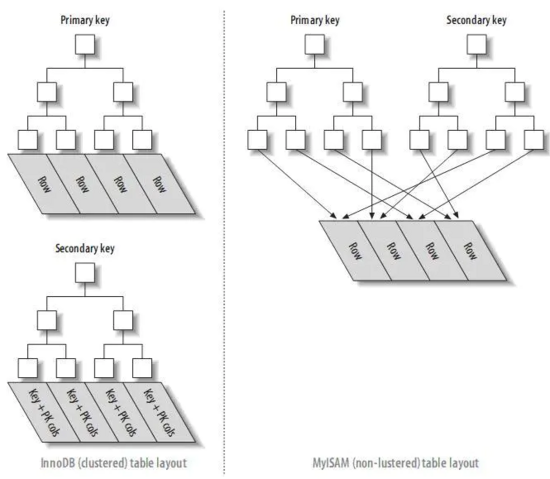
首先,和MyISAM上的主鍵索引一樣,這里的索引的葉子結點上同樣也是包括了主鍵的值,并且主鍵的值是按照順序排列的。不同的是,每一個葉子結點還包括了事務id,回滾指針和其他非主鍵列的值(這里指的col2)。所以我們可以理解為InnoDB上的聚簇索引,是將原來表格中的所有的行數據按照主鍵進行排列然后放在了索引的葉子節點上。這就是一個與MyISAM在主鍵索引上的一個不同。 MyISAM的主鍵索引在查找到對應的主鍵值之后需要通過指針(行號)再去表中找到相對應的數據行,而InnoDB的主鍵索引,將數據信息全部放在了索引里面,可以直接在索引中查找拿到。
再來看看InnoDB中的二級索引的情況:
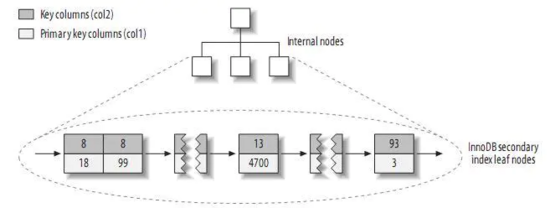
可以看到,和InnoDB中的主鍵索引不同,二級索引并沒有在葉子結點存儲所有的行數據信息,而是除了索引列的值外,只存儲了這個數據行所對應的主鍵的信息。我們知道在MyISAM中,二級索引和主鍵索引一樣,除了索引列的值外,只存儲了一個指針(行號)的信息。
對比一下兩個引擎上的二級索引。即存儲指針和存儲主鍵值的優劣。
首先存儲主鍵值會比只存儲一個指針帶來的空間開銷更大。但是當我們數據表在進行分裂或者其他改變結構的操作的時候,存儲主鍵值的索引并不會收到影響,而存儲指針的索引,可能就要重新進行更新維護。
用一個圖對兩個引擎中的兩種索引進行對比:
總結
到此這篇關于MySQL學習教程之聚簇索引的文章就介紹到這了,更多相關MySQL聚簇索引內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 詳解MySQL 聚簇索引與非聚簇索引
- mysql聚簇索引的頁分裂原理實例分析
- 一看就懂的MySQL的聚簇索引及聚簇索引是如何長高的
