目錄
- 背景
- LIMIT優化
- 優化方式
- 1、使用覆蓋索引
- 2、子查詢優化
- 3、延遲關聯
- 4、記錄上次查詢結束的位置
- 總結
背景
基本上只要是做后臺開發,都會接觸到分頁這個需求或者功能吧。基本上大家都是會用MySQL的LIMIT來處理,而且我現在負責的項目也是這樣寫的。但是一旦數據量起來了,其實LIMIT的效率會極其的低,這一篇文章就來講一下LIMIT子句優化的。
LIMIT優化
很多業務場景都需要用到分頁這個功能,基本上都是用LIMIT來實現。
建表并且插入200萬條數據:
# 新建一張t5表
CREATE TABLE `t5` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`text` varchar(100) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_name` (`name`),
KEY `ix_test` (`text`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 創建存儲過程插入200萬數據
CREATE PROCEDURE t5_insert_200w()
BEGIN
DECLARE i INT;
SET i=1000000;
WHILE i=3000000 DO
INSERT INTO t5(`name`,text) VALUES('god-jiang666',concat('text', i));
SET i=i+1;
END WHILE;
END;
# 調用存儲過程插入200萬數據
call t5_insert_200w();
在翻頁比較少的情況下,LIMIT是不會出現任何性能上的問題的。
但是如果用戶需要查到最后面的頁數呢?
通常情況下,我們要保證所有的頁面可以正常跳轉,因為不會使用order by xxx desc這樣的倒序SQL來查詢后面的頁數,而是采用正序順序來做分頁查詢:
select * from t5 order by text limit 100000, 10;
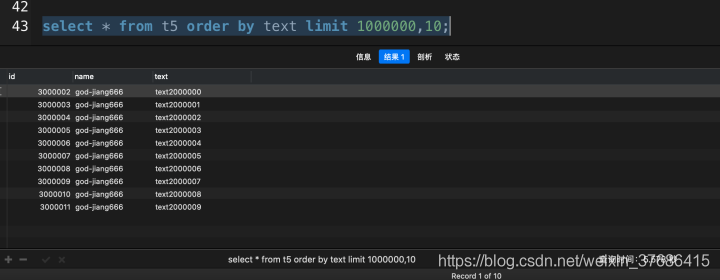
采用這種SQL查詢分頁的話,從200萬數據中取出這10行數據的代價是非常大的,需要先排序查出前1000010條記錄,然后拋棄前面1000000條。我的macbook pro跑出來花了5.578秒。
接下來我們來看一下,上面這條SQL語句的執行計劃:
explain select * from t5 order by text limit 1000000, 10;
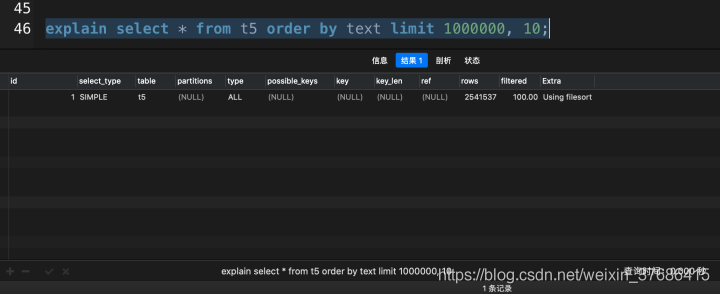
從執行計劃可以看出,在大分頁的情況下,MySQL沒有走索引掃描,即使text字段我已經加上了索引。
這是為什么呢?
回到MySQL索引(二)如何設計索引中有提及到,MySQL數據庫的查詢優化器是采用了基于代價的,而查詢代價的估算是基于CPU代價和IO代價。
如果MySQL在查詢代價估算中,認為全表掃描方式比走索引掃描的方式效率更高的話,就會放棄索引,直接全表掃描。
這就是為什么在大分頁的SQL查詢中,明明給該字段加了索引,但是MySQL卻走了全表掃描的原因。
然后我們繼續用上面的查詢SQL來驗證我的猜想:
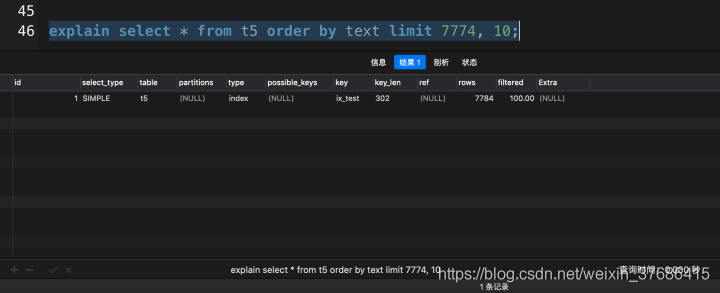
explain select * from t5 order by text limit 7774, 10;
explain select * from t5 order by text limit 7775, 10;
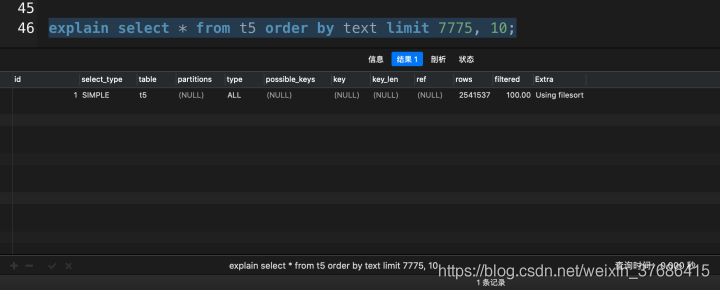
以上的實驗均在我的mbp上運行的,在7774這個臨界點上,MySQL分別采用了索引掃描和全表掃描的查詢優化方式。
所以可以認為MySQL會根據它自己的代價查詢優化器來判斷是否使用索引。
由于MySQL的查詢優化器的算法核心是我們無法人工干預的,所以我們的優化思路就要著手于如何讓分頁維持在最佳的的分頁臨界點。
優化方式
1、使用覆蓋索引
如果一條SQL語句,通過索引可以直接獲取查詢的結果,不再需要回表查詢,就稱這個索引為覆蓋索引。
在MySQL數據庫中使用explain關鍵字查看執行計劃,如果extra這一列顯示Using index,就表示這條SQL語句使用了覆蓋索引。
讓我們來對比一下使用了覆蓋索引,性能會提升多少吧。
# 沒有使用覆蓋索引
select * from t5 order by text limit 1000000, 10;
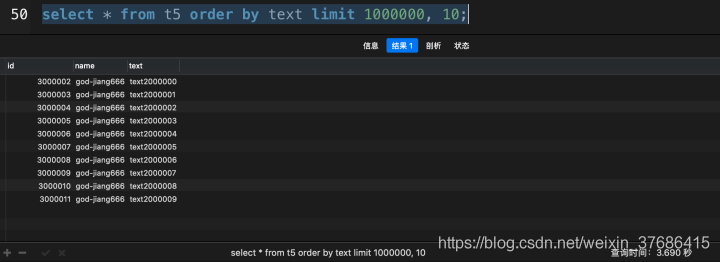

這次查詢花了3.690秒,讓我們看一下使用了覆蓋索引優化會提升多少性能吧。
# 使用了覆蓋索引
select id, `text` from t5 order by text limit 1000000, 10;
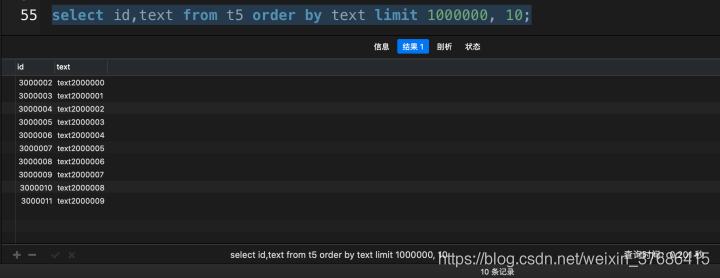
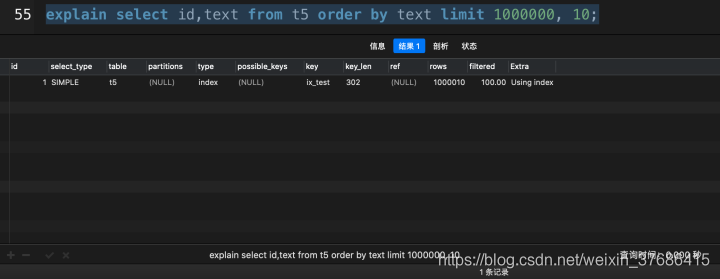
從上面的對比中,超大分頁查詢中,使用了覆蓋索引之后,花了0.201秒,而沒有使用覆蓋索引花了3.690秒,提高了18倍多,這在實際開發中,就是一個大的性能優化了。(該數據在我的mbp上運行得出)
2、子查詢優化
因為實際開發中,用SELECT查詢一兩列操作是非常少的,因此上述的覆蓋索引的適用范圍就比較有限。
所以我們可以通過把分頁的SQL語句改寫成子查詢的方法獲得性能上的提升。
select * from t5 where id>=(select id from t5 order by text limit 1000000, 1) limit 10;
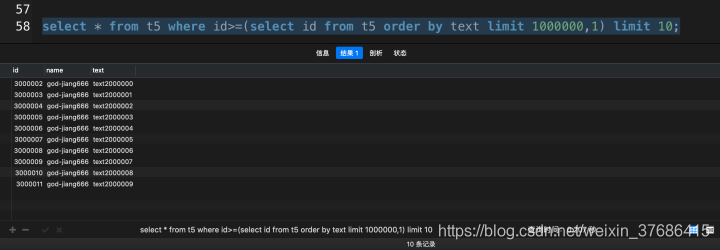
其實使用這種方法,提升的效率和上面使用了覆蓋索引基本一致。
但是這種優化方法也有局限性:
- 這種寫法,要求主鍵ID必須是連續的
- Where子句不允許再添加其他條件
3、延遲關聯
和上述的子查詢做法類似,我們可以使用JOIN,先在索引列上完成分頁操作,然后再回表獲取所需要的列。
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;
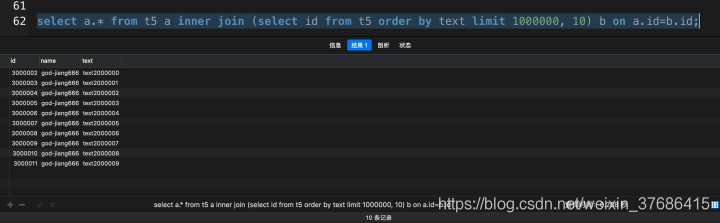
從實驗中可以得出,在采用JOIN改寫后,上面的兩個局限性都已經解除了,而且SQL的執行效率也沒有損失。
4、記錄上次查詢結束的位置
和上面使用的方法都不同,記錄上次結束位置優化思路是使用某種變量記錄上一次數據的位置,下次分頁時直接從這個變量的位置開始掃描,從而避免MySQL掃描大量的數據再拋棄的操作。
select * from t5 where id>=1000000 limit 10;
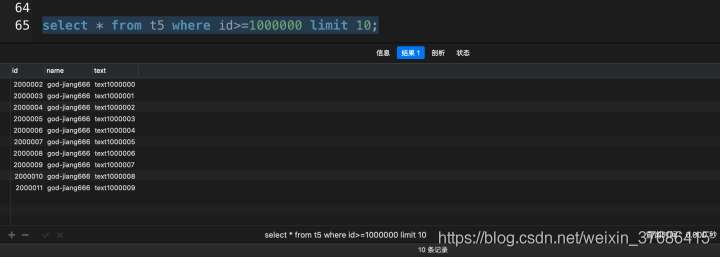
根據以上實驗,不難得出,由于使用了主鍵索引做分頁操作,SQL的性能是最快的。
總結
- 介紹了超大分頁查詢性能過差的原因,還有分享了幾個優化思路
- 超大分頁的優化思路就是讓分頁的SQL盡量在最佳的性能區間執行,不要觸發全表掃描即可
- 希望以上的分享,可以讓你們在MySQL這條路上少走彎路~~~
參考資料
- 《MySQL性能優化》第六章 查詢優化性能
- 《數據庫查詢優化器的藝術》
到此這篇關于MySQL優化教程之超大分頁查詢的文章就介紹到這了,更多相關MySQL超大分頁查詢內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- MySQL百萬級數據量分頁查詢方法及其優化建議
- MySQL百萬級數據分頁查詢優化方案
- mysql千萬級數據分頁查詢性能優化
- Mysql Limit 分頁查詢優化詳解
- MySQL中SQL分頁查詢的幾種實現方法及優缺點
- php分頁查詢mysql結果的base64處理方法示例
- 詳解MySQL的limit用法和分頁查詢語句的性能分析
- MySQL 分頁查詢的優化技巧
