目錄
- 一、MySQL通配符模糊查詢(%,_)
- 1-1. 通配符的分類
- 1-2. 通配符的使用
- 1-3. 技巧與建議:
- 二、MySQL內置函數檢索(locate,position,instr)
- 2-1. LOCATE()函數
- 2-2. POSITION()方法
- 2-3. INSTR()方法
- 三、MySQL基于regexp、rlike的正則匹配查詢
- 3-1. regexp中的 OR : |
- 3-2. REGEXP中的正則匹配 : []
- 3-3. 字符類匹配(posix)
- 3-4. [::]和[:>:]
- 四、總結
SELECT * from table where username like '%陳哈哈%' and hobby like '%牛逼'
這是一條我們在MySQL中常用到的模糊查詢方法,通過通配符%來進行匹配,其實,這只是冰山一角,在MySQL中,支持模糊匹配的方法有很多,且各有各的優點。好了,今天讓我帶大家一起掀起MySQL的小裙子,看一看模糊查詢下面還藏著多少鮮為人知的好東西。
一、MySQL通配符模糊查詢(%,_)
1-1. 通配符的分類
- "%" 百分號通配符: 表示任何字符出現任意次數 (可以是0次)。
- "_" 下劃線通配符:表示只能匹配單個字符,不能多也不能少,就是一個字符。當然,也可以like "陳____",數量不限。
- like操作符:LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配進行比較;但如果like后面沒出現通配符,則在SQL執行優化時將 like 默認為 “=”執行
注意: 如果在使用like操作符時,后面沒有使用通用匹配符(%或_),那么效果是和“=”一致的。在SQL執行優化時查詢優化器將 like 默認為 “=”執行,SELECT * FROM movies WHERE movie_name like '唐伯虎';只能匹配movie_name=“唐伯虎”的結果,而不能匹配像“唐伯虎點秋香”或“唐伯虎點香煙”這樣的結果.
1-2. 通配符的使用
1) % 通配符:
-- 模糊匹配含有“網”字的數據
SELECT * from app_info where appName like '%網%';
-- 模糊匹配以“網”字結尾的數據
SELECT * from app_info where appName like '%網';
-- 模糊匹配以“網”字開頭的數據
SELECT * from app_info where appName like '網%';

-- 精準匹配,appName like '網' 等同于:appName = '網'
SELECT * from app_info where appName = '網';
-- 等同于
SELECT * from app_info where appName like '網';
-- 模糊匹配含有“xxx網xxx車xxx”的數據,如:"途途網約車司機端、網絡約車平臺"
SELECT * from app_info where appName like '%網%車%';
2) _ 通配符:
-- 查詢以“網”為結尾的,長度為三個字的數據,如:"鏈家網",
SELECT * from app_info where appName like '__網';
注意:'%__網、__%網' 等同于 '%網'
-- 查詢前三個字符為XX網,后面任意匹配,如:"城通網盤、模具網平臺"
SELECT * from app_info where appName like '__網%';
-- 模糊匹配含有“xx網x車xxx”的數據,如:"攜程網約車客戶端"
SELECT * from app_info where appName like '__網_車%';
注意事項:
注意大小寫,在使用模糊匹配時,也就是匹配文本時,MySQL默認配置是不區分大小寫的。當你使用別人的MySQL數據庫時,要注意是否區分大小寫,是否區分大小寫取決于用戶對MySQL的配置方式.如果是區分大小寫,那么像Test12這樣記錄是不能被"test__"這樣的匹配條件匹配的。
注意尾部空格,"%test"是不能匹配"test "這樣的記錄的。
注意NULL,%通配符可以匹配任意字符,但是不能匹配NULL,也就是說SELECT * FROM blog where title_name like '%';是匹配不到title_name為NULL的的記錄。
1-3. 技巧與建議:
正如所見,MySQL的通配符很有用。但這種功能是有代價的:通配符搜索的處理一般要比前面討論的其他搜索所花時間更長,消耗更多的內存等資源。這里給出一些使用通配符要記住的技巧。
- 不要過度使用通配符。如果其他操作符能達到相同的目的,應該使用其他操作符。
- 在確實需要使用通配符時,除非絕對有必要,否則不要把它們用在搜索模式的開始處。因為MySQL在where后面的執行順序是從左往右執行的,如果把通配符置于搜索模式的開始處(最左側),搜索起來是最慢的(因為要對全庫進行掃描)。
- 仔細注意通配符的位置。如果放錯地方,可能不會返回想要的數據。
有細心地朋友會發現,如果數據中有“%”、“_”等符號,那豈不是和通配符沖突了?
SELECT * from app_info where appName LIKE '%%%';
SELECT * from app_info where appName LIKE '%_%';
確實如此,上面面兩條SQL語句查詢的都是全表數據,而不是帶有"%"和"_"的指定數據。這里需要加 ESCAPE 關鍵字進行轉義。
如下,ESCAPE 后面跟著一個字符,里面寫著什么,MySQL就把那個符號當做轉義符,一般我就寫成"/";然后就像 C語言中轉義字符一樣 例如 ‘\n','\t', 把這個字符寫在你需要轉義的那個%號前就可以了;
SELECT * from app_info where appName LIKE '%/_%' ESCAPE '/';
但是這種情況有沒有更高端點的解決辦法呢?能讓檢查你代碼的同事或領導對你刮目相看那種~~
當然,下面我們就來看看MySQL的第二類模糊匹配方式 --- 內置函數查詢
二、MySQL內置函數檢索(locate,position,instr)
話接上文,通過內置函數locate,position,instr進行匹配,相當于Java中的str.contains()方法,返回的是匹配內容在字符串中的位置,效率和可用性上都優于通配符匹配。
SELECT * from app_info where INSTR(`appName`, '%') > 0;
SELECT * from app_info where LOCATE('%', `appName`) > 0;
SELECT * from app_info where POSITION( '%' IN `appName`) > 0;
如上,三種內置函數默認都是:> 0,所以下列 > 0 可加可不加,加上可讀性更好。
OK,下面一起來看看這三種內置函數的使用方法吧。
先明確一下,MySQL中的角標從左往右是從1開始的,不像java最左邊第一位角標是0,因此在MySQL中角標為0時說明不存在。
2-1. LOCATE()函數
語法: LOCATE(substr,str)
返回 substr 在 str 中第一次出現的位置。如果 substr 在 str 中不存在,返回值為 0,如果substr 在 str 中存在,返回值為:substr 在 str中第一次出現的位置。
注意:LOCATE(substr,str)與 POSITION(substr IN str)是同義詞,功能相同。
語法: LOCATE(substr, str, [pos])
從位置pos開始的字符串str中第一次出現子字符串substr的位置。 如果substr不在str中,則返回0。 如果substr或str為NULL,則返回NULL。
SELECT locate('a', 'banana'); -- 2
SELECT locate('a', 'banana', 3); -- 4
SELECT locate('z', 'banana'); -- 0
SELECT locate(10, 'banana'); -- 0
SELECT locate(NULL , 'banana'); -- null
SELECT locate('a' , NULL ); -- null
實例:
-- 用LOCATE關鍵字進行模糊匹配,等同于:"like '%網%'"
SELECT * from app_info where LOCATE('網', `appName`) > 0;
-- 用LOCATE關鍵字進行模糊匹配, 從第二個字符開始匹配"網",則"網易云游戲、網來商家"等數據就被過濾了
SELECT * from app_info where LOCATE('網', `appName`, 2) > 0;
2-2. POSITION()方法
語法:POSITION(substr IN substr)
這個方法可以理解為locate(substr,str)方法的別名,因為它和locate(substr,str)方法的作用是一樣的。
實例:
-- 用POSITION關鍵字進行模糊匹配,等同于:"like '%網%'"
SELECT * from app_info where POSITION( '網' IN `appName`);
2-3. INSTR()方法
語法: INSTR(str,substr)
返回字符串str中第一次出現子字符串substr的位置。INSTR()與LOCATE()的雙參數形式相同,只是參數的順序相反。
實例:
-- 用INSTR關鍵字進行模糊匹配,功能跟like一樣 ,等同于:"like '%網%'"
SELECT * from app_info where INSTR(`appName`, '網');
-- instr函數作用,一般用于檢索某字符在某字符串中的位置,等同于:"like '%網%'"
SELECT * from app_info where INSTR(`appName`, '網') > 0;
三、MySQL基于regexp、rlike的正則匹配查詢
MySQL中的regexp和rlike關鍵字屬于同義詞,功能相同。本文以regexp為準。
REGEXP 不支持通配符"%、_",支持正則匹配規則,是一種更細力度且優雅的匹配方式,一起來看看吧
-- 這里給出regexp包含的參數類型
| 參數類型 |
作用 |
| (^) |
匹配字符串的開始位置,如“^a”表示以字母a開頭的字符串。 |
| ($) |
匹配字符串的結束位置,如“X^”表示以字母X結尾的字符串。 |
| (.) |
這個字符就是英文下的點,它匹配任何一個字符,包括回車、換行等。 |
| (*) |
星號匹配0個或多個字符,在它之前必須有內容。如:select * from table where name regexp 'ba*'(可以命中“baaa”) |
| (+) |
加號匹配1個或多個字符,在它之前也必須有內容。加號跟星號的用法類似,只是星號允許出現0次,加號則必須至少出現一次。
|
| (?) |
問號匹配0次或1次。 |
| {n} |
匹配指定n個 |
| {n,} |
匹配不少于n個 |
| {n,m} |
匹配n-m個 |
-- REGEXP '網' 等同于 like '%網%'
SELECT * from app_info where appName REGEXP '網';
-- 等同于
SELECT * from app_info where appName like '%網%';
3-1. regexp中的 OR : |
功能:可以搜索多個字符串之一,相當于 or
-- 支持 "|" ‘或'符號,匹配包含“中國”或“互聯網”或“大學”的數據,支持疊加多個
SELECT * from app_info where appName REGEXP '中國|互聯網|大學';

-- 匹配同時命中“中國”、“網”的數據可以用".+"連接,代表中國xxxx網,中間允許有任意個字符,順序不能反。
SELECT * from app_info where appName REGEXP '中國.+網';
3-2. REGEXP中的正則匹配 : []
功能:匹配[]符號中幾個字符之一,支持解析正則表達式
-- 匹配包含英文字符的數據,默認不區分大小寫情況下
SELECT * from app_info where appName REGEXP '[a-z]';
-- 跟like一樣,取反集加 "not REGEXP" 即可,下面不再贅述
SELECT * from app_info where appName not REGEXP '[a-z]';
-- 匹配包含大寫英文字符的數據,默認忽略大小寫,需要加上"BINARY"關鍵字。如where appName REGEXP BINARY 'Hello'
-- 關于大小寫的區分:MySQL中正則表達式匹配(從版本3.23.4后)不區分大小寫 。
SELECT * from app_info where appName REGEXP BINARY '[A-Z]';
-- 匹配包含數字的數據
SELECT * from app_info where appName REGEXP '[0-9]';
-- 匹配包含數字或英文的數據,
SELECT * from app_info where appName REGEXP '[a-z0-9]';
a-z、0-9都認定為一個單位,不要加多余符號,前兩天就發現了一個特殊情況,很有意思的bug,跟他家分享一下
-- 之前寫查詢語句時多加了"|"符號,以為是"或",沒有在意,但萬萬沒想到,查出數量竟不同
SELECT * from app_info where appName REGEXP '[567]'; -- 87條
SELECT * from app_info where appName REGEXP '[5|6|7]'; -- 88條
一頭霧水,趕快看看差得是哪一條
-- 原來"|"符號也參與到了匹配中,認定為一個單位。巧的是有一個數據為:“無線調音臺 | Wireless Mixer” 這個正好匹配上。臥槽了個DJ
SELECT * from app_info where appName REGEXP '[5|6|7]' and pid not in (SELECT pid from app_info where appName REGEXP '[567]');

-- 查詢以5、6、7其中一個為開頭的數據
SELECT * from app_info where appName REGEXP '^[5|6|7]';
-- 查詢以5、6、7其中一個為結尾的數據
SELECT * from app_info where appName REGEXP '[5|6|7]$';
溫馨提示:MySQL中,UTF-8的中文=3個字節;GBK的中文=2個字節
-- 查詢appName字節長度為10,任意內容的數據
SELECT * from app_info where appName REGEXP '^.{10}$';
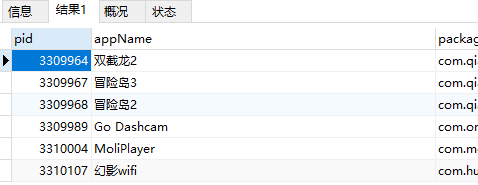
-- 查詢appName字節長度為10,且都為英文的數據
SELECT * from app_info where appName REGEXP '^[a-z]{10}$' ;
-- 查詢appName字節長度為10,且都為大寫英文的數據,加上BINARY即可
SELECT * from app_info where appName REGEXP BINARY '^[A-Z]{10}$';

-- 查詢version_name字節長度為6,且都為數字或"." 的數據
SELECT * from app_info where version_name REGEXP '^[0-9.]{6}$';
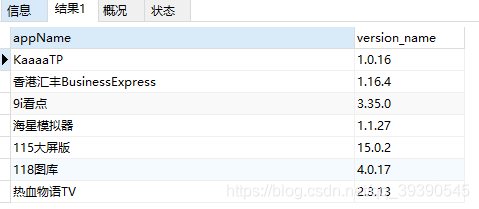
-- 查詢version_name字節長度為6,且都為數字或"." 的數據;要求首位為1
SELECT * from app_info where version_name REGEXP '^1[0-9.]{5}$' ;
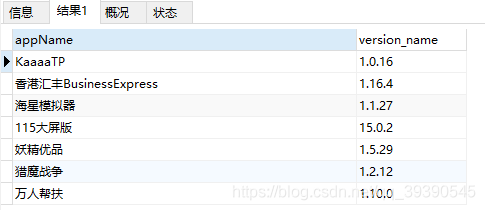
-- 查詢version_name字節長度為6,且都為數字或"." 的數據;要求首位為1,末位為7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4}7$' ;
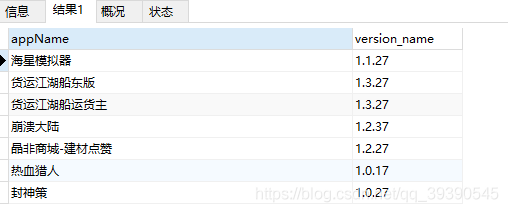
-- 查詢version_name字節長度為6位以上,且都為數字或"." 的數據;要求首位為1,末位為7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,}7$' ;
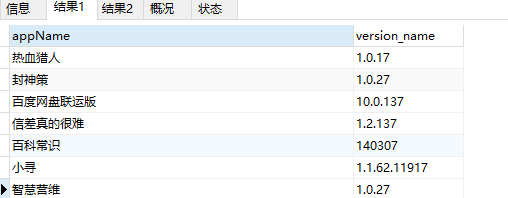
-- 查詢version_name字節長度為 6 - 8 位,且都為數字或"." 的數據;要求首位為1,末位為7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,6}7$' ;
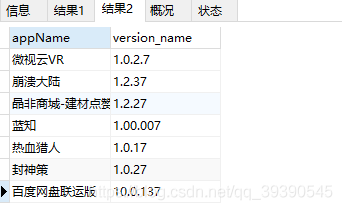
-- 首位字符不是中文的
SELECT * from app_info where appName REGEXP '^[ -~]';
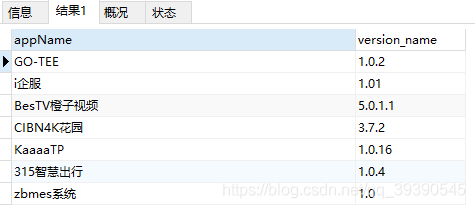
-- 首位字符是中文的
SELECT * from app_info where appName REGEXP '^[^ -~]';
-- 查詢不包含中文的數據
SELECT * from app_info where appName REGEXP '^([a-z]|[0-9]|[A-Z])+$';
-- 以5或F開頭的,且包含英文的數據
SELECT * from app_info where appName REGEXP BINARY '^[5F][a-zA-Z].';
特殊符號的匹配,例如.,需要加\\(注意是兩個斜杠),但是如果在[]中可以不加:
-- 匹配name中含有.的
select * from app_info where appName regexp '\\.';
-- 匹配name中含有.的
select * from app_info where appName regexp '[.]';
3-3. 字符類匹配(posix)
mysql中有一些特殊含義的符號,可以代表不同類型的匹配:
-- 匹配name中含有數字的
select * from app_info where appName regexp '[[:digit:]]';
其他的這種字符類還有:
| 字符類 |
作用 |
| [:alnum:] |
匹配字面和數字字符。(等同于[A~Za~z0~9]) |
| [:alpha:] |
匹配字母字符。(等同于[A~Za~z]) |
| [:blank:] |
匹配空格或制表符(同[\\\t]) |
| [:cntrl:] |
匹配控制字符(ASCII0到37和127) |
| [:digit:] |
匹配十進制數字。(等同于[0-9]) |
| [:graph:] |
匹配ASCII碼值范圍33~126的字符。與[:print:]相似,但不包括空格字符 |
| [:print:] |
任何可打印字符 |
| [:lower:] |
匹配小寫字母,等同于[a-z] |
| [:upper:] |
匹配大寫字母,等同于[A-Z] |
| [:space:] |
匹配空白字符(同[\\f\\n\\r\\t\\v]) |
| [:xdigit:] |
匹配十六進制數字。等同于[0-9A-Fa-f] |
這種字符類需要主要的外層要加一層[]。
3-4. [::]和[:>:]
上面的字符類中有兩個比較特殊的,這兩個是關于位置的,[::]匹配詞的開始,[:>:]匹配詞的結束,它們和 ^、$ 不同。
后者是匹配整個整體的開頭和結束,而前者是匹配一個單詞的開始和結束。
-- 只能匹配整體以a開頭的,例如abcd
select * from app_info where appName regexp '^a';
-- 能匹配整體以a開頭的,也能匹配中間的單詞以a開頭,如:dance after。
select * from app_info where appName regexp '[[::]]a';

[[::]] 、 [[:>:]] 分別匹配一個單詞開頭和結尾的空的字符串,這個單詞開頭和結尾都不是包含在alnum中的字符也不能是下劃線。
select "a word a" REGEXP "[[::]]word[[:>:]]"; -- 1(表示匹配)
select "a xword a" REGEXP "[[::]]word[[:>:]]"; -- 0(表示不匹配)
select "weeknights" REGEXP "^(wee|week)(knights|nights)$"; -- 1(表示匹配)
四、總結
好啦,本篇文章就到這里了,能看到這里的都是有緣人,希望本文能幫助到你對MySQL的理解更進一步。更多相關MySQL模糊查詢內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- mysql中模糊查詢的四種用法介紹
- MySql like模糊查詢通配符使用詳細介紹
- 淺談MySQL模糊查詢中通配符的轉義
- mysql中使用instr進行模糊查詢方法介紹
- PHP+MySQL實現模糊查詢員工信息功能示例
- PHP MYSQL實現登陸和模糊查詢兩大功能
- mysql模糊查詢like與REGEXP的使用詳細介紹
- MySQL Like模糊查詢速度太慢如何解決
- MySQL模糊查詢語句整理集合
- Mysql| 使用通配符進行模糊查詢詳解(like,%,_)
