前言
這一節我們還是繼續講講索引知識,前面我們聚集索引、非聚集索引以及覆蓋索引等,在這其中還有一個過濾索引,通過索引過濾我們也能提高查詢性能,簡短的內容,深入的理解。
過濾索引,在查詢條件上創建非聚集索引(1)
過濾索引是SQL 2008的新特性,被應用在表中的部分行,所以利用過濾索引能夠提高查詢,相對于全表掃描它能減少索引維護和索引存儲的代價。當我們在索引上應用WHERE條件時就是過濾索引。也就是滿足如下格式:
CREATE NONCLUSTERED INDEX index name>
ON table> (columns>)
WHERE criteria>;
GO
下面我們來看一個簡單的查詢
USE AdventureWorks2012
GO
SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail
WHERE UnitPrice > 2000
GO
上述列中未建立任何索引,當然除了SalesOrderDetailID默認創建的聚集索引,這種情況下我們能夠猜想到其執行的查詢計劃必然是主鍵創建的聚集索引掃描,如下

上述我們已經說過此時未在查詢條件上創建索引,所以此時必然走的是主鍵創建的聚集索引,接下來我們首先在UnitPrice列上創建非聚集索引來提高查詢性能,
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
此時我們再來比較二者查詢開銷
USE AdventureWorks2012
GO
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
SELECT SalesOrderDetailID, UnitPrice
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID]))
WHERE UnitPrice > 2000
GO
SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > 2000

此時在查詢條件上建立了非聚集索引之后,查詢開銷提升的非常明顯,提升達到了90%以上,因為非聚集索引也會引用了主鍵創建的聚集索引,所以這個時候不會導致Bookmark Lookup或者Key Lookup查找。接下來我們我們再添加一個帶有條件的非聚集索引即過濾索引
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
WHERE UnitPrice > 1000
此時我們再來看看創建了過濾索引之后和之前非聚集索引性能開銷差異:
USE AdventureWorks2012
GO
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
SELECT SalesOrderDetailID, UnitPrice
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > 2000
SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > 2000
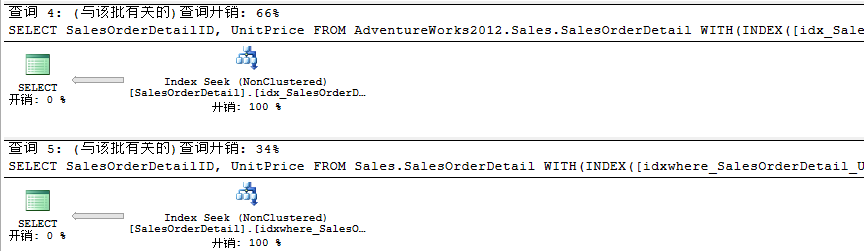
此時我們知道創建的非聚集過濾索引與傳統創建的非聚集索引相比,我們的查詢接近減少了一半。
唯一過濾索引
唯一過濾索引對于所有列必須唯一且不為空(只允許一個NULL存在)也是非常好的解決方案,所以此時在創建唯一過濾索引時需要將NULL值除外,比如如下:
CREATE UNIQUE NONCLUSTERED INDEX uq_fix_Customers_Email
ON Customers(Email)
WHERE Email IS NOT NULL
GO
過濾索引結合INCLUDE
當我們再添加一個額外列時,使用默認主鍵創建的聚集索引時,此時會走聚集索引掃描,然后我們在查詢條件上創建一個過濾索引,我們強制使用這個過濾索引時,此時由于添加額外列,會導致需要返回到基表中再去獲取數據,所以也就造成了Key Lookup查找,如下:
USE AdventureWorks2012
GO
SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail
WHERE UnitPrice > 2000
GO
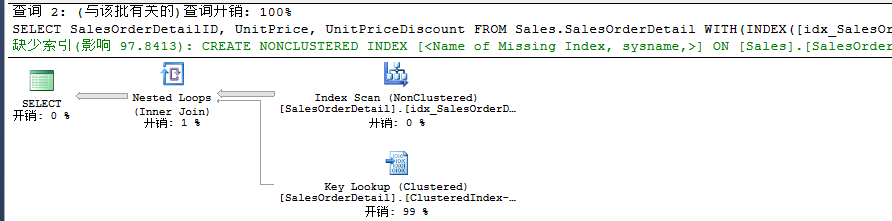
此時我們需要用INCLUDE來包含額外列。
CREATE NONCLUSTERED INDEX [idx_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount)
我們再創建一個過濾索引同時包括額外列
CREATE NONCLUSTERED INDEX [idxwhere_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount)
WHERE UnitPrice > 2000
接下來再來執行比較添加過濾索引和未添加過濾索引同時都包括了額外列的性能查詢差異。
SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > 2000
SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > 2000
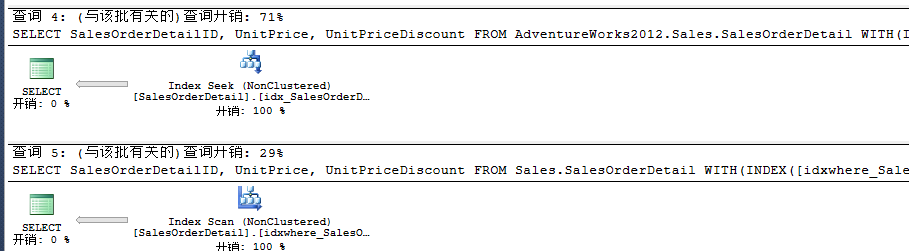
此時性能用INCLUDE來包含額外列性能也得到了一定的改善。
過濾索引,在主鍵上創建非聚集索引(2)
在第一個案列中,我們可以直接在查詢列上創建非聚集索引,因為其類型是數字類型,要是查詢條件是字符類型呢?首選現在我們先創建一個測試表
USE TSQL2012
GO
CREATE TABLE dbo.TestData
(
RowID integer IDENTITY NOT NULL,
SomeValue VARCHAR(max) NOT NULL,
StartDate date NOT NULL,
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
);
添加10萬條測試數據
USE TSQL2012
GO
INSERT dbo.TestData WITH (TABLOCKX)
(SomeValue, StartDate)
SELECT
CAST(N.n AS VARCHAR(max)) + 'JeffckyWang',
DATEADD(DAY, (N.n - 1) % 31, '20140101')
FROM dbo.Nums AS N
WHERE
N.n >= 1
AND N.n 100001;
如果我們需要獲取表TestData中SomeValue = 'JeffckyWang',此時我們想要在SomeValue上創建一個非聚集索引然后進行過濾,如下
USE TSQL2012
GO
CREATE NONCLUSTERED INDEX idx_noncls_somevalue
ON dbo.TestData(SomeValue)
WHERE SomeValue = 'JeffckyWang'

更新
SQL Server對創建索引大小有限制,最大是900字節,上述直接寫的VARCHAR(MAX),所以會出錯,切記,切記。
此時我們在主鍵上創建非聚集索引,我們在主鍵RowID上創建一個過濾索引且SomeValue = 'JeffckyWang',然后返回數據,如下:
CREATE NONCLUSTERED INDEX idxwhere_noncls_somevalue
ON dbo.TestData(RowID)
WHERE SomeValue = 'JeffckyWang'
下面我們來對比建立過濾索引前后查詢計劃結果:
USE TSQL2012
GO
SELECT RowID, SomeValue, StartDate
FROM dbo.TestData WITH(INDEX([idx_pk_rowid]))
WHERE SomeValue = 'JeffckyWang'
SELECT RowID, SomeValue, StartDate
FROM dbo.TestData WITH(INDEX([idxwhere_noncls_somevalue]))
WHERE SomeValue = 'JeffckyWang'
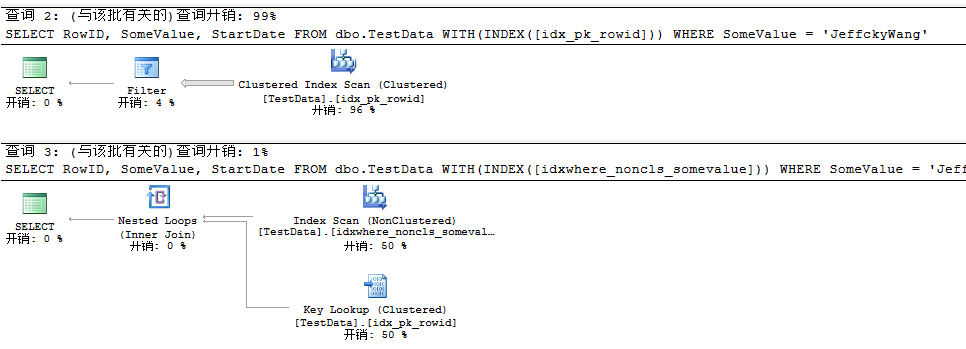
然后結合之前所學,移除Key Lookup,對創建的過濾索引進行INCLUDE。
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate)
WHERE SomeValue = 'JeffckyWang'
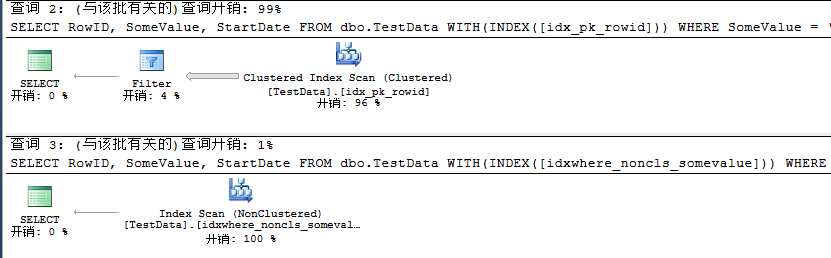
從這里看出,無論是對查詢條件創建過濾索引還是對主鍵創建過濾索引,我們都可以通過結合之前所學來提高查詢性能。
我們從開頭就一直在講創建過濾索引,那么創建過濾索引優點的條件到底是什么?
(1)只能通過非聚集索引進行創建。
(2)如果在視圖上創建過濾索引,此視圖必須是持久化視圖。
(3)不能在全文索引上創建過濾索引。
過濾索引的優點
(1)減少索引維護成本:對于增、刪、改等操作不需要代價沒有那么昂貴,因為一個過濾索引的重建不需要耗時太多時間。
(2)減少存儲成本:過濾索引的存儲占用空間很小。
(3)更精確的統計:通過在WHERE條件上創建過濾索引比全表統計結果更加精確。
(4)優化查詢性能:通過查詢計劃可以看出其高效性。
講到這里為止,一直陳述的是過濾索引的好處和優點,已經將其捧上天了,其實其缺點也是顯而易見。
過濾索引缺點
最大的缺點則是查詢條件的限制。其查詢條件僅限于
filter_predicate> ::=
conjunct> [ AND conjunct> ]
conjunct> ::=
disjunct> | comparison>
disjunct> ::=
column_name IN (constant ,...n)
過濾條件僅限于AND、|、IN。比較條件僅限于 { IS | IS NOT | = | > | != | > | >= | !> | | = | ! },所以如下利用LIKE不行
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate)
WHERE SomeValue LIKE 'JeffckyWang%'

如下可以
USE AdventureWorks2012
GO
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate
ON Sales.SalesOrderDetail(ModifiedDate)
WHERE ModifiedDate >= '2008-01-01' AND ModifiedDate = '2008-01-07'
GO
如下卻不行
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate
ON Sales.SalesOrderDetail(ModifiedDate)
WHERE ModifiedDate = GETDATE()
GO

變量對過濾索引影響
上述我們創建過濾索引在查詢條件上直接定義的字符串,如下:
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
WHERE UnitPrice > 1000
如果定義的是變量,利用變量來進行比較會如何呢?首先我們創建一個過濾索引
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ProductID
ON Sales.SalesOrderDetail (ProductID)
WHERE ProductID = 870
利用變量來和查詢條件比較,強制使用過濾索引(默認情況下走聚集索引)
USE AdventureWorks2012
GO
DECLARE @ProductID INT
SET @ProductID = 870
SELECT ProductID
FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_ProductID]))
WHERE ProductID = @ProductID

查看查詢執行計劃結果卻出錯了,此時我們需要添加OPTION重新編譯,如下:
USE AdventureWorks2012
GO
DECLARE @ProductID INT
SET @ProductID = 870
SELECT ProductID
FROM Sales.SalesOrderDetail
WHERE ProductID = @ProductID
OPTION(RECOMPILE)

上述利用變量來查詢最后通過OPTION重新編譯在SQL Server 2012中測試好使,至于其他版本未知,參考資料【The Pains of Filtered Indexes】。
總結
本節我們學習了通過過濾索引來提高查詢性能,同時也給出了其不同的場景以及其使用優點和明顯的缺點。簡短的內容,深入的理解,我們下節再會,good night。
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流,同時也希望多多支持腳本之家!
您可能感興趣的文章:- SQL Server 2005通用分頁存儲過程及多表聯接應用
- SQL設置SQL Server最大連接數及查詢語句
- 解析SQL Server聚焦移除(Bookmark Lookup、RID Lookup、Key Lookup)
- 淺述SQL Server的聚焦強制索引查詢條件和Columnstore Index
- 淺析SQL Server的分頁方式 ISNULL與COALESCE性能比較
- 詳解SQL Server中的數據類型
- 淺析SQL Server的聚焦使用索引和查詢執行計劃
- 淺析SQL Server 聚焦索引對非聚集索引的影響
- 如何快速刪掉SQL Server登錄時登錄名下拉列表框中的選項
- 淺談SQL Server交叉聯接 內部聯接
