Why Pool
go自從出生就身帶“高并發”的標簽,其并發編程就是由groutine實現的,因其消耗資源低,性能高效,開發成本低的特性而被廣泛應用到各種場景,例如服務端開發中使用的HTTP服務,在golang net/http包中,每一個被監聽到的tcp鏈接都是由一個groutine去完成處理其上下文的,由此使得其擁有極其優秀的并發量吞吐量
for {
// 監聽tcp
rw, e := l.Accept()
if e != nil {
.......
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
// 啟動協程處理上下文
go c.serve(ctx)
}
雖然創建一個groutine占用的內存極小(大約2KB左右,線程通常2M左右),但是在實際生產環境無限制的開啟協程顯然是不科學的,比如上圖的邏輯,如果來幾千萬個請求就會開啟幾千萬個groutine,當沒有更多內存可用時,go的調度器就會阻塞groutine最終導致內存溢出乃至嚴重的崩潰,所以本文將通過實現一個簡單的協程池,以及剖析幾個開源的協程池源碼來探討一下對groutine的并發控制以及多路復用的設計和實現。
一個簡單的協程池
過年前做過一波小需求,是將主播管理系統中信息不完整的主播找出來然后再到其相對應的直播平臺爬取完整信息并補全,當時考慮到每一個主播的數據都要訪問一次直播平臺所以就用應對每一個主播開啟一個groutine去抓取數據,雖然這個業務量還遠遠遠遠達不到能造成groutine性能瓶頸的地步,但是心里總是不舒服,于是放假回來后將其優化成從協程池中控制groutine數量再開啟爬蟲進行數據抓取。思路其實非常簡單,用一個channel當做任務隊列,初始化groutine池時確定好并發量,然后以設置好的并發量開啟groutine同時讀取channel中的任務并執行, 模型如下圖
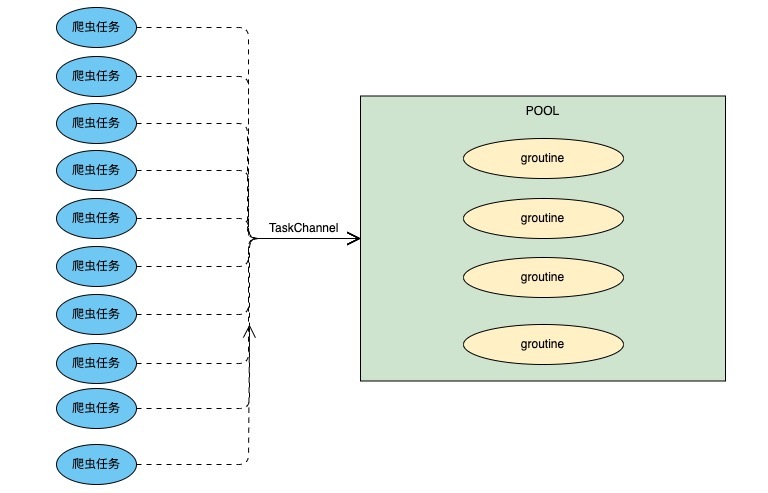
實現
type SimplePool struct {
wg sync.WaitGroup
work chan func() //任務隊列
}
func NewSimplePoll(workers int) *SimplePool {
p := SimplePool{
wg: sync.WaitGroup{},
work: make(chan func()),
}
p.wg.Add(workers)
//根據指定的并發量去讀取管道并執行
for i := 0; i workers; i++ {
go func() {
defer func() {
// 捕獲異常 防止waitGroup阻塞
if err := recover(); err != nil {
fmt.Println(err)
p.wg.Done()
}
}()
// 從workChannel中取出任務執行
for fn := range p.work {
fn()
}
p.wg.Done()
}()
}
return p
}
// 添加任務
func (p *SimplePool) Add(fn func()) {
p.work - fn
}
// 執行
func (p *SimplePool) Run() {
close(p.work)
p.wg.Wait()
}
測試
測試設定為在并發數量為20的協程池中并發抓取一百個人的信息, 因為代碼包含較多業務邏輯所以sleep 1秒模擬爬蟲過程,理論上執行時間為5秒
func TestSimplePool(t *testing.T) {
p := NewSimplePoll(20)
for i := 0; i 100; i++ {
p.Add(parseTask(i))
}
p.Run()
}
func parseTask(i int) func() {
return func() {
// 模擬抓取數據的過程
time.Sleep(time.Second * 1)
fmt.Println("finish parse ", i)
}
}
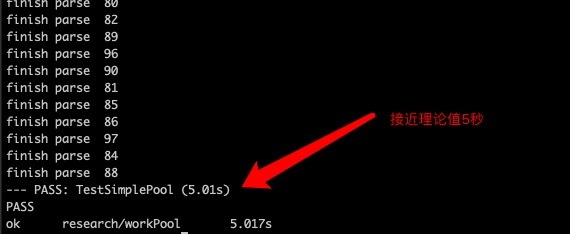
這樣一來最簡單的一個groutine池就完成了
go-playground/pool
上面的groutine池雖然簡單,但是對于每一個并發任務的狀態,pool的狀態缺少控制,所以又去看了一下go-playground/pool的源碼實現,先從每一個需要執行的任務入手,該庫中對并發單元做了如下的結構體,可以看到除工作單元的值,錯誤,執行函數等,還用了三個分別表示,取消,取消中,寫 的三個并發安全的原子操作值來標識其運行狀態。
// 需要加入pool 中執行的任務
type WorkFunc func(wu WorkUnit) (interface{}, error)
// 工作單元
type workUnit struct {
value interface{} // 任務結果
err error // 任務的報錯
done chan struct{} // 通知任務完成
fn WorkFunc
cancelled atomic.Value // 任務是否被取消
cancelling atomic.Value // 是否正在取消任務
writing atomic.Value // 任務是否正在執行
}
接下來看Pool的結構
type limitedPool struct {
workers uint // 并發量
work chan *workUnit // 任務channel
cancel chan struct{} // 用于通知結束的channel
closed bool // 是否關閉
m sync.RWMutex // 讀寫鎖,主要用來保證 closed值的并發安全
}
初始化groutine池, 以及啟動設定好數量的groutine
// 初始化pool,設定并發量
func NewLimited(workers uint) Pool {
if workers == 0 {
panic("invalid workers '0'")
}
p := limitedPool{
workers: workers,
}
p.initialize()
return p
}
func (p *limitedPool) initialize() {
p.work = make(chan *workUnit, p.workers*2)
p.cancel = make(chan struct{})
p.closed = false
for i := 0; i int(p.workers); i++ {
// 初始化并發單元
p.newWorker(p.work, p.cancel)
}
}
// passing work and cancel channels to newWorker() to avoid any potential race condition
// betweeen p.work read write
func (p *limitedPool) newWorker(work chan *workUnit, cancel chan struct{}) {
go func(p *limitedPool) {
var wu *workUnit
defer func(p *limitedPool) {
// 捕獲異常,結束掉異常的工作單元,并將其再次作為新的任務啟動
if err := recover(); err != nil {
trace := make([]byte, 116)
n := runtime.Stack(trace, true)
s := fmt.Sprintf(errRecovery, err, string(trace[:int(math.Min(float64(n), float64(7000)))]))
iwu := wu
iwu.err = ErrRecovery{s: s}
close(iwu.done)
// need to fire up new worker to replace this one as this one is exiting
p.newWorker(p.work, p.cancel)
}
}(p)
var value interface{}
var err error
for {
select {
// workChannel中讀取任務
case wu = -work:
// 防止channel 被關閉后讀取到零值
if wu == nil {
continue
}
// 先判斷任務是否被取消
if wu.cancelled.Load() == nil {
// 執行任務
value, err = wu.fn(wu)
wu.writing.Store(struct{}{})
// 任務執行完在寫入結果時需要再次檢查工作單元是否被取消,防止產生競爭條件
if wu.cancelled.Load() == nil wu.cancelling.Load() == nil {
wu.value, wu.err = value, err
close(wu.done)
}
}
// pool是否被停止
case -cancel:
return
}
}
}(p)
}
往POOL中添加任務,并檢查pool是否關閉
func (p *limitedPool) Queue(fn WorkFunc) WorkUnit {
w := workUnit{
done: make(chan struct{}),
fn: fn,
}
go func() {
p.m.RLock()
if p.closed {
w.err = ErrPoolClosed{s: errClosed}
if w.cancelled.Load() == nil {
close(w.done)
}
p.m.RUnlock()
return
}
// 將工作單元寫入workChannel, pool啟動后將由上面newWorker函數中讀取執行
p.work - w
p.m.RUnlock()
}()
return w
}
在go-playground/pool包中, limitedPool的批量并發執行還需要借助batch.go來完成
// batch contains all information for a batch run of WorkUnits
type batch struct {
pool Pool // 上面的limitedPool實現了Pool interface
m sync.Mutex // 互斥鎖,用來判斷closed
units []WorkUnit // 工作單元的slice, 這個主要用在不設并發限制的場景,這里忽略
results chan WorkUnit // 結果集,執行完后的workUnit會更新其value,error,可以從結果集channel中讀取
done chan struct{} // 通知batch是否完成
closed bool
wg *sync.WaitGroup
}
// go-playground/pool 中有設置并發量和不設并發量的批量任務,都實現Pool interface,初始化batch批量任務時會將之前創建好的Pool傳入newBatch
func newBatch(p Pool) Batch {
return batch{
pool: p,
units: make([]WorkUnit, 0, 4), // capacity it to 4 so it doesn't grow and allocate too many times.
results: make(chan WorkUnit),
done: make(chan struct{}),
wg: new(sync.WaitGroup),
}
}
// 往批量任務中添加workFunc任務
func (b *batch) Queue(fn WorkFunc) {
b.m.Lock()
if b.closed {
b.m.Unlock()
return
}
//往上述的limitPool中添加workFunc
wu := b.pool.Queue(fn)
b.units = append(b.units, wu) // keeping a reference for cancellation purposes
b.wg.Add(1)
b.m.Unlock()
// 執行完后將workUnit寫入結果集channel
go func(b *batch, wu WorkUnit) {
wu.Wait()
b.results - wu
b.wg.Done()
}(b, wu)
}
// 通知批量任務不再接受新的workFunc, 如果添加完workFunc不執行改方法的話將導致取結果集時done channel一直阻塞
func (b *batch) QueueComplete() {
b.m.Lock()
b.closed = true
close(b.done)
b.m.Unlock()
}
// 獲取批量任務結果集
func (b *batch) Results() -chan WorkUnit {
go func(b *batch) {
-b.done
b.m.Lock()
b.wg.Wait()
b.m.Unlock()
close(b.results)
}(b)
return b.results
}
測試
func SendMail(int int) pool.WorkFunc {
fn := func(wu pool.WorkUnit) (interface{}, error) {
// sleep 1s 模擬發郵件過程
time.Sleep(time.Second * 1)
// 模擬異常任務需要取消
if int == 17 {
wu.Cancel()
}
if wu.IsCancelled() {
return false, nil
}
fmt.Println("send to", int)
return true, nil
}
return fn
}
func TestBatchWork(t *testing.T) {
// 初始化groutine數量為20的pool
p := pool.NewLimited(20)
defer p.Close()
batch := p.Batch()
// 設置一個批量任務的過期超時時間
t := time.After(10 * time.Second)
go func() {
for i := 0; i 100; i++ {
batch.Queue(SendMail(i))
}
batch.QueueComplete()
}()
// 因為 batch.Results 中要close results channel 所以不能將其放在LOOP中執行
r := batch.Results()
LOOP:
for {
select {
case -t:
// 登臺超時通知
fmt.Println("recived timeout")
break LOOP
case email, ok := -r:
// 讀取結果集
if ok {
if err := email.Error(); err != nil {
fmt.Println("err", err.Error())
}
fmt.Println(email.Value())
} else {
fmt.Println("finish")
break LOOP
}
}
}
}

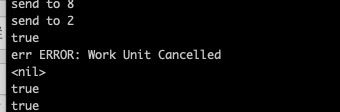
接近理論值5s, 通知模擬被取消的work也正常取消
go-playground/pool在比起之前簡單的協程池的基礎上, 對pool, worker的狀態有了很好的管理。但是,但是問題來了,在第一個實現的簡單groutine池和go-playground/pool中,都是先啟動預定好的groutine來完成任務執行,在并發量遠小于任務量的情況下確實能夠做到groutine的復用,如果任務量不多則會導致任務分配到每個groutine不均勻,甚至可能出現啟動的groutine根本不會執行任務從而導致浪費,而且對于協程池也沒有動態的擴容和縮小。所以我又去看了一下ants的設計和實現。
ants
ants是一個受fasthttp啟發的高性能協程池, fasthttp號稱是比go原生的net/http快10倍,其快速高性能的原因之一就是采用了各種池化技術(這個日后再開新坑去讀源碼), ants相比之前兩種協程池,其模型更像是之前接觸到的數據庫連接池,需要從空余的worker中取出一個來執行任務, 當無可用空余worker的時候再去創建,而當pool的容量達到上線之后,剩余的任務阻塞等待當前進行中的worker執行完畢將worker放回pool, 直至pool中有空閑worker。 ants在內存的管理上做得很好,除了定期清除過期worker(一定時間內沒有分配到任務的worker),ants還實現了一種適用于大批量相同任務的pool, 這種pool與一個需要大批量重復執行的函數鎖綁定,避免了調用方不停的創建,更加節省內存。
先看一下ants的pool 結構體 (pool.go)
type Pool struct {
// 協程池的容量 (groutine數量的上限)
capacity int32
// 正在執行中的groutine
running int32
// 過期清理間隔時間
expiryDuration time.Duration
// 當前可用空閑的groutine
workers []*Worker
// 表示pool是否關閉
release int32
// lock for synchronous operation.
lock sync.Mutex
// 用于控制pool等待獲取可用的groutine
cond *sync.Cond
// 確保pool只被關閉一次
once sync.Once
// worker臨時對象池,在復用worker時減少新對象的創建并加速worker從pool中的獲取速度
workerCache sync.Pool
// pool引發panic時的執行函數
PanicHandler func(interface{})
}
接下來看pool的工作單元 worker (worker.go)
type Worker struct {
// worker 所屬的poo;
pool *Pool
// 任務隊列
task chan func()
// 回收時間,即該worker的最后一次結束運行的時間
recycleTime time.Time
}
執行worker的代碼 (worker.go)
func (w *Worker) run() {
// pool中正在執行的worker數+1
w.pool.incRunning()
go func() {
defer func() {
if p := recover(); p != nil {
//若worker因各種問題引發panic,
//pool中正在執行的worker數 -1,
//如果設置了Pool中的PanicHandler,此時會被調用
w.pool.decRunning()
if w.pool.PanicHandler != nil {
w.pool.PanicHandler(p)
} else {
log.Printf("worker exits from a panic: %v", p)
}
}
}()
// worker 執行任務隊列
for f := range w.task {
//任務隊列中的函數全部被執行完后,
//pool中正在執行的worker數 -1,
//將worker 放回對象池
if f == nil {
w.pool.decRunning()
w.pool.workerCache.Put(w)
return
}
f()
//worker 執行完任務后放回Pool
//使得其余正在阻塞的任務可以獲取worker
w.pool.revertWorker(w)
}
}()
}
了解了工作單元worker如何執行任務以及與pool交互后,回到pool中查看其實現, pool的核心就是取出可用worker提供給任務執行 (pool.go)
// 向pool提交任務
func (p *Pool) Submit(task func()) error {
if 1 == atomic.LoadInt32(p.release) {
return ErrPoolClosed
}
// 獲取pool中的可用worker并向其任務隊列中寫入任務
p.retrieveWorker().task - task
return nil
}
// **核心代碼** 獲取可用worker
func (p *Pool) retrieveWorker() *Worker {
var w *Worker
p.lock.Lock()
idleWorkers := p.workers
n := len(idleWorkers) - 1
// 當前pool中有可用worker, 取出(隊尾)worker并執行
if n >= 0 {
w = idleWorkers[n]
idleWorkers[n] = nil
p.workers = idleWorkers[:n]
p.lock.Unlock()
} else if p.Running() p.Cap() {
p.lock.Unlock()
// 當前pool中無空閑worker,且pool數量未達到上線
// pool會先從臨時對象池中尋找是否有已完成任務的worker,
// 若臨時對象池中不存在,則重新創建一個worker并將其啟動
if cacheWorker := p.workerCache.Get(); cacheWorker != nil {
w = cacheWorker.(*Worker)
} else {
w = Worker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
w.run()
} else {
// pool中沒有空余worker且達到并發上限
// 任務會阻塞等待當前運行的worker完成任務釋放會pool
for {
p.cond.Wait() // 等待通知, 暫時阻塞
l := len(p.workers) - 1
if l 0 {
continue
}
// 當有可用worker釋放回pool之后, 取出
w = p.workers[l]
p.workers[l] = nil
p.workers = p.workers[:l]
break
}
p.lock.Unlock()
}
return w
}
// 釋放worker回pool
func (p *Pool) revertWorker(worker *Worker) {
worker.recycleTime = time.Now()
p.lock.Lock()
p.workers = append(p.workers, worker)
// 通知pool中已經獲取鎖的groutine, 有一個worker已完成任務
p.cond.Signal()
p.lock.Unlock()
}
在批量并發任務的執行過程中, 如果有超過5納秒(ants中默認worker過期時間為5ns)的worker未被分配新的任務,則將其作為過期worker清理掉,從而保證pool中可用的worker都能發揮出最大的作用以及將任務分配得更均勻
(pool.go)
// 該函數會在pool初始化后在協程中啟動
func (p *Pool) periodicallyPurge() {
// 創建一個5ns定時的心跳
heartbeat := time.NewTicker(p.expiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
currentTime := time.Now()
p.lock.Lock()
idleWorkers := p.workers
if len(idleWorkers) == 0 p.Running() == 0 atomic.LoadInt32(p.release) == 1 {
p.lock.Unlock()
return
}
n := -1
for i, w := range idleWorkers {
// 因為pool 的worker隊列是先進后出的,所以正序遍歷可用worker時前面的往往里當前時間越久
if currentTime.Sub(w.recycleTime) = p.expiryDuration {
break
}
// 如果worker最后一次運行時間距現在超過5納秒,視為過期,worker收到nil, 執行上述worker.go中 if n == nil 的操作
n = i
w.task - nil
idleWorkers[i] = nil
}
if n > -1 {
// 全部過期
if n >= len(idleWorkers)-1 {
p.workers = idleWorkers[:0]
} else {
// 部分過期
p.workers = idleWorkers[n+1:]
}
}
p.lock.Unlock()
}
}
測試
func TestAnts(t *testing.T) {
wg := sync.WaitGroup{}
pool, _ := ants.NewPool(20)
defer pool.Release()
for i := 0; i 100; i++ {
wg.Add(1)
pool.Submit(sendMail(i, wg))
}
wg.Wait()
}
func sendMail(i int, wg *sync.WaitGroup) func() {
return func() {
time.Sleep(time.Second * 1)
fmt.Println("send mail to ", i)
wg.Done()
}
}
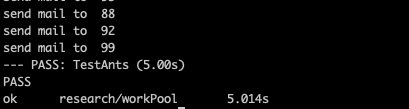
這里雖只簡單的測試批量并發任務的場景, 如果大家有興趣可以去看看ants的壓力測試, ants的吞吐量能夠比原生groutine高出N倍,內存節省10到20倍, 可謂是協程池中的神器。
借用ants作者的原話來說:
然而又有多少場景是單臺機器需要扛100w甚至1000w同步任務的?基本沒有啊!結果就是造出了屠龍刀,可是世界上沒有龍啊!也是無情…
Over
一口氣從簡單到復雜總結了三個協程池的實現,受益匪淺, 感謝各開源庫的作者, 雖然世界上沒有龍,但是屠龍技是必須練的,因為它就像存款,不一定要全部都用了,但是一定不能沒有!
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持腳本之家。
您可能感興趣的文章:- golang協程池模擬實現群發郵件功能
- golang 40行代碼實現通用協程池
- GO實現協程池管理的方法
