我們在使用Django的models查詢數據庫時,可以看到有這種寫法:
form app.models import XXX
query = XXX.objects.all()
query = query.filter(name=123, age=456).filter(salary=999)
在這種寫法里面,query對象有一個filter方法�,這個方法的返回數據還可以繼續調用filter方法����,可以這樣無限制地調用下去����。
這種寫法是怎么實現的呢?
如果我們直接寫一個類的方法����,看看能不能這樣調用:
class Query:
def filter(self):
pass
query = Query()
query.filter().filter()
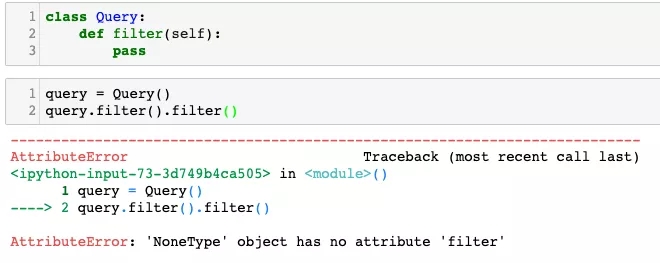
直接對query.filter()返回的結果再調用一次filter����,就會導致報錯了���。這是因為在沒有顯式寫return語句的時候���,方法會返回None,而None對象是沒有所謂的filter方法的����。
那么什么東西有filter方法呢�����?顯然我們的query對象有filter方法��。那么如何讓這個方法返回自身這個對象呢�?
這個時候�,我們就要看看我們在定義類方法的時候,總會寫的的第一個參數self了。幾乎每個類方法里面都會有它。大家只知道在類里面調用類方法的時候可以用self.xxx(),在調用類屬性的時候可以用self.yy����,那么有沒有思考過�����,這個東西如果單獨使用會怎么樣呢?
實際上�,self指的就是這個類實例化成一個對象以后����,這個對象自身���。而這個對象顯然是有filter方法的�。所以我們修改一下filter方法,讓它返回self:
class Query:
def filter(self):
return self
query = Query()
query.filter().filter()
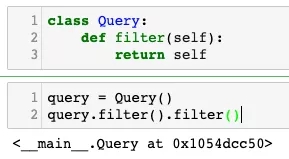
從圖中可以看出,現在已經不會報錯了��。那么回到最開始的問題���,Django里面的鏈式調用傳入查詢參數是如何實現的呢�����?
實際上這里涉及到一個惰性查詢的問題���。
當我們不停調用.filter()方法的時候����,Django會把這些查詢條件全部緩存起來���,只有當我們需要獲取結果�,或者查詢滿足條件的數據有多少條時�,它才會真正地連接數據庫去查詢。
所以我們這里要模擬這個環境�����,把查詢條件緩存起來���。
那么為了獲取調用方法時傳入的參數名����,我們就要使用**kwargs參數。這個參數可以接受所有的key=value形式的參數:
class Query():
def __init__(self):
self.query_condition = {}
def filter(self, **kwargs):
self.query_condition.update(kwargs)
return self
query = Query()
a = query.filter(name='kingname').filter(age__gt=15, address='yyyyyy').filter(salary=99999)
print(query.query_condition)
運行效果如下圖所示:
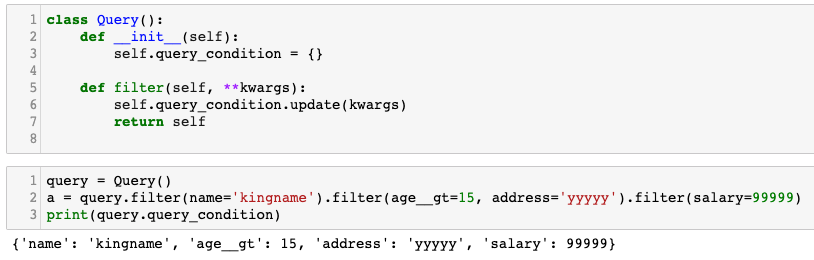
在真正需要輸出結果的時候����,再使用這些緩存的條件�����,去數據庫中查詢結果即可。
以上就是python中如何實現鏈式調用的詳細內容��,更多關于python 實現鏈式調用的資料請關注腳本之家其它相關文章�����!
您可能感興趣的文章:- Python實現類似jQuery使用中的鏈式調用的示例
- 解決python調用matlab時的一些常見問題
- Python調用R語言實例講解
- python程序調用遠程服務的步驟詳解
- 使用pycallgraph分析python代碼函數調用流程以及框架解析
- Python與C/C++的相互調用案例
- python調用百度AI接口實現人流量統計
- 詳解Python調用系統命令的六種方法
- 安裝python依賴包psycopg2來調用postgresql的操作
- Python調用系統命令os.system()和os.popen()的實現
- 詳解如何在VS2019和VScode中配置C++調用python接口
