一����、配置webdriver
下載谷歌瀏覽器驅動,并配置好
import time
import random
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
if __name__ == '__main__':
options = webdriver.ChromeOptions()
options.binary_location = r'C:\Users\hhh\AppData\Local\Google\Chrome\Application\谷歌瀏覽器.exe'
# driver=webdriver.Chrome(executable_path=r'D:\360Chrome\chromedriver\chromedriver.exe')
driver = webdriver.Chrome(options=options)
#以java模塊為例
driver.get('https://www.csdn.net/nav/java')
for i in range(1,20):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(2)
二�����、獲取URL
from bs4 import BeautifulSoup
from lxml import etree
html = etree.HTML(driver.page_source)
# soup = BeautifulSoup(html, 'lxml')
# soup_herf=soup.find_all("#feedlist_id > li:nth-child(1) > div > div > h2 > a")
# soup_herf
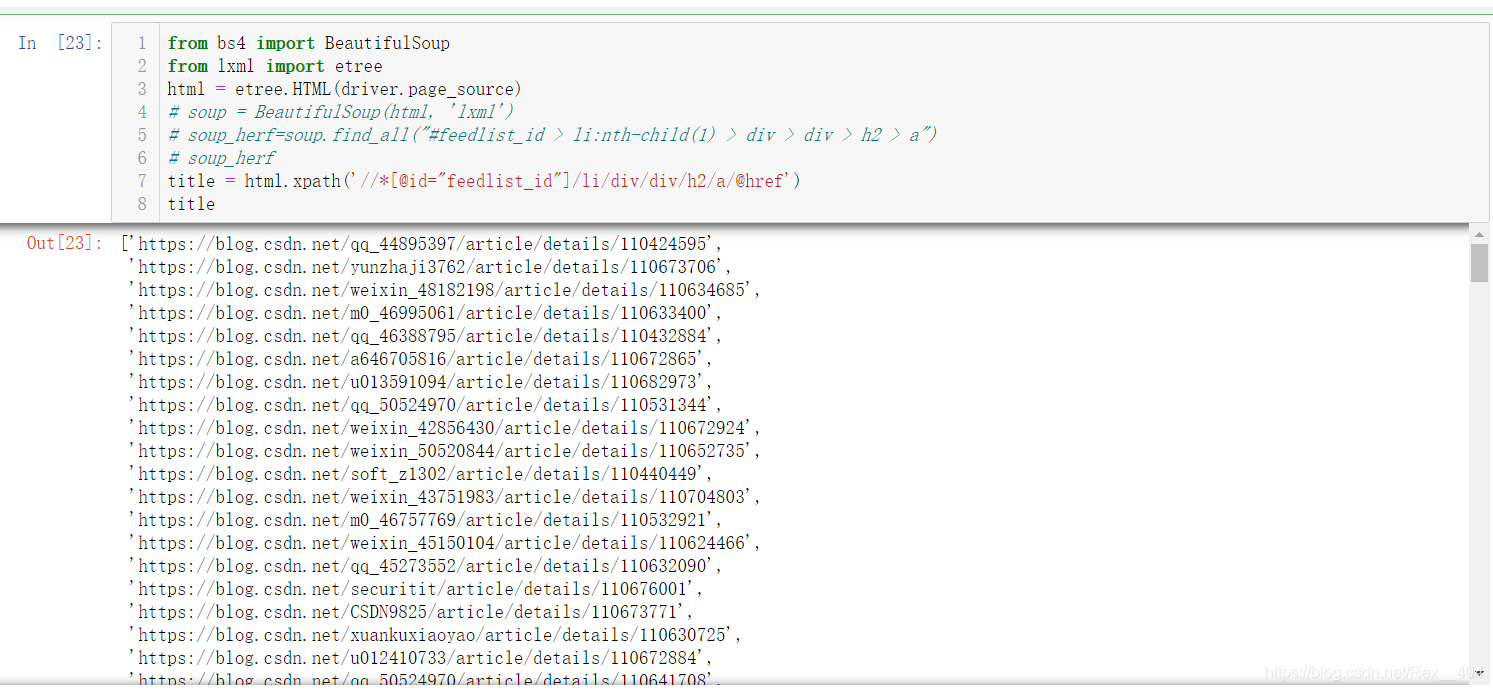
title = html.xpath('//*[@id="feedlist_id"]/li/div/div/h2/a/@href')
可以看到���,一下爬取了很多�����,速度非?���??br />
三�、寫入Redis
導入redis包后,配置redis端口和redis數據庫�����,用rpush函數寫入
打開redis
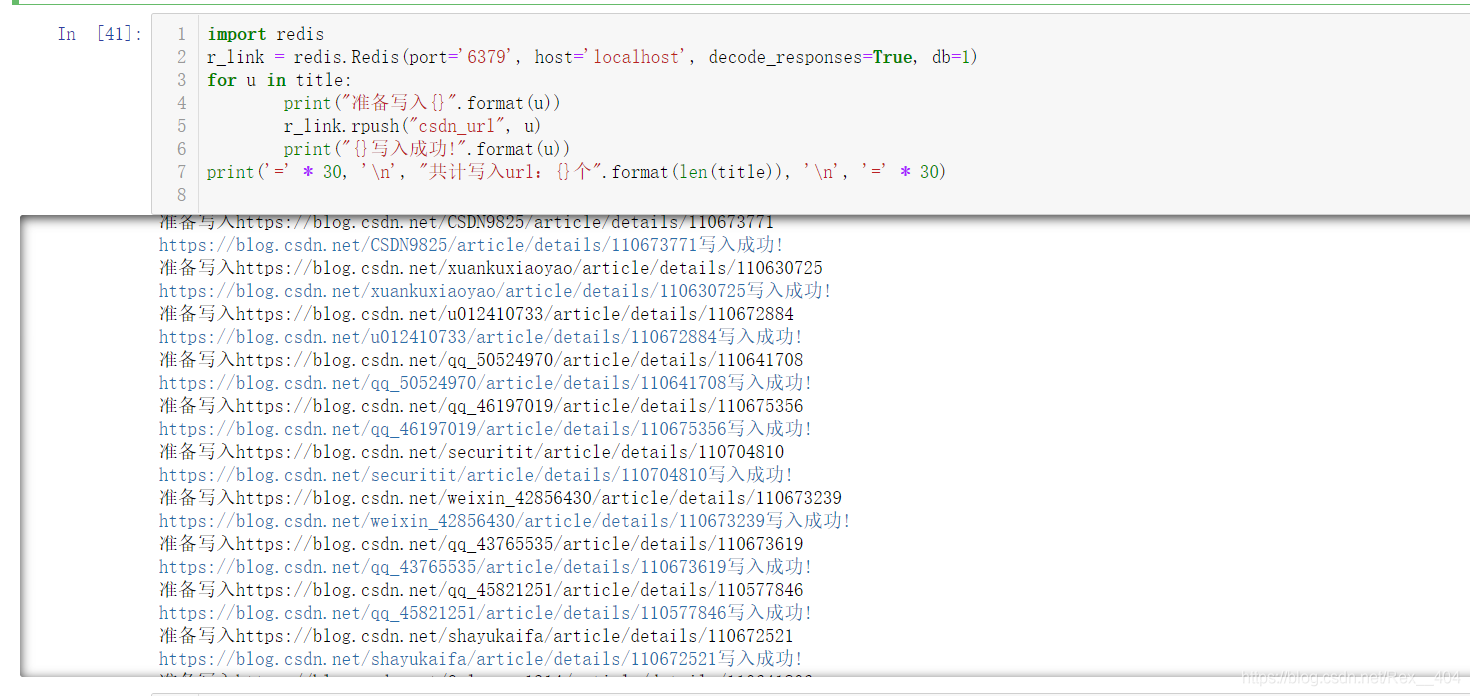
import redis
r_link = redis.Redis(port='6379', host='localhost', decode_responses=True, db=1)
for u in title:
print("準備寫入{}".format(u))
r_link.rpush("csdn_url", u)
print("{}寫入成功!".format(u))
print('=' * 30, '\n', "共計寫入url:{}個".format(len(title)), '\n', '=' * 30)
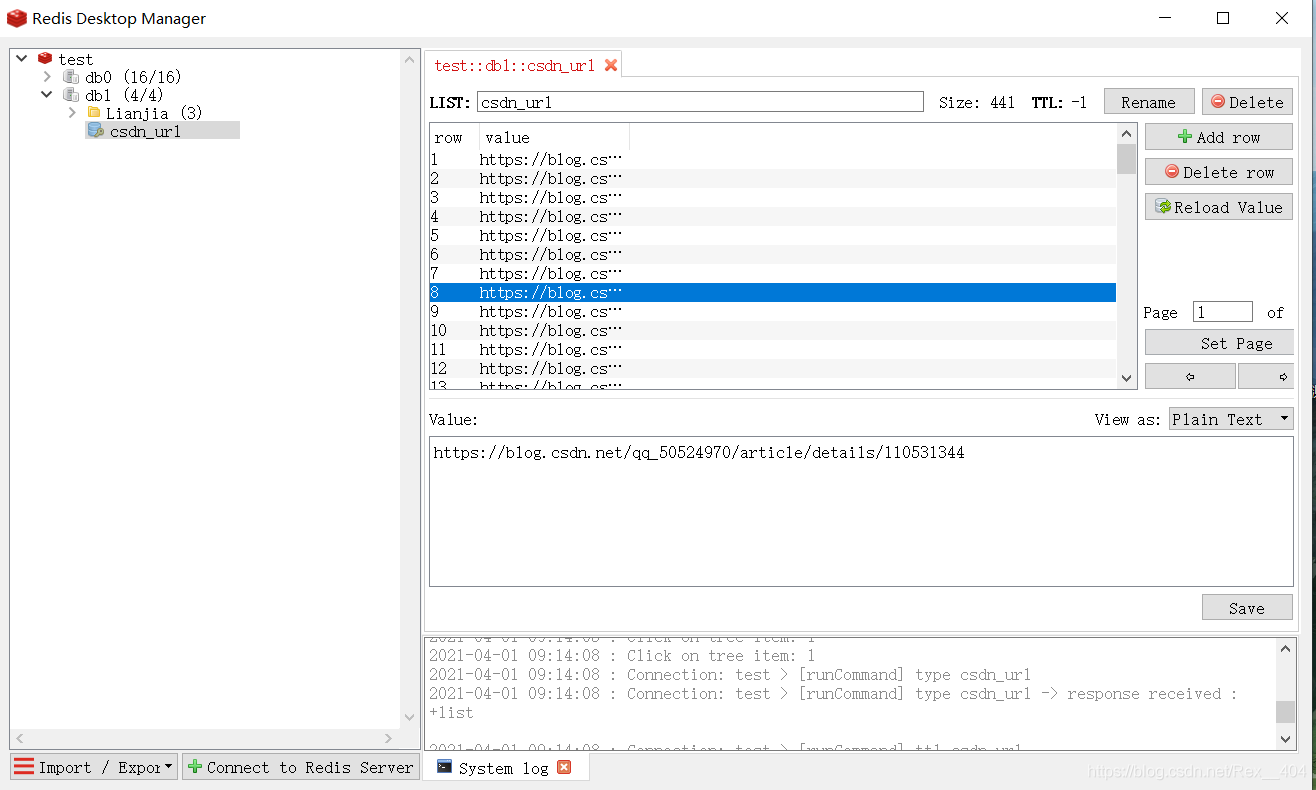
大功告成�����!
在Redis Desktop Manager中可以看到���,爬取和寫入都是非常的快���。
要使用只需用rpop出棧就OK
one_url = r_link.rpop("csdn_url)")
while one_url:
print("{}被彈出����!".format(one_url))
到此這篇關于詳解用python實現爬取CSDN熱門評論URL并存入redis的文章就介紹到這了,更多相關python爬取URL內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家���!
您可能感興趣的文章:- python 爬取京東指定商品評論并進行情感分析
- python爬取晉江文學城小說評論(情緒分析)
- 利用Python網絡爬蟲爬取各大音樂評論的代碼
- python 利用百度API進行淘寶評論關鍵詞提取
- python 爬取騰訊視頻評論的實現步驟
- python爬取微博評論的實例講解
- python實現模擬器爬取抖音評論數據的示例代碼
- 如何基于Python爬取隱秘的角落評論
- Python實現爬取并分析電商評論
- python 爬取馬蜂窩景點翻頁文字評論的實現
- 用Python爬取QQ音樂評論并制成詞云圖的實例
- python 爬取華為應用市場評論
