機器學習
在吳恩達老師的課程中,有過對機器學習的定義:
ML:P T E>
P即performance,T即Task,E即Experience,機器學習是對一個Task,根據Experience,去提升Performance;
在機器學習中,神經網絡的地位越來越重要,實踐發現,非線性的激活函數有助于神經網絡擬合分布,效果明顯優于線性分類器:
y=Wx+b
常用激活函數有ReLU,sigmoid,tanh;
sigmoid將值映射到(0,1):

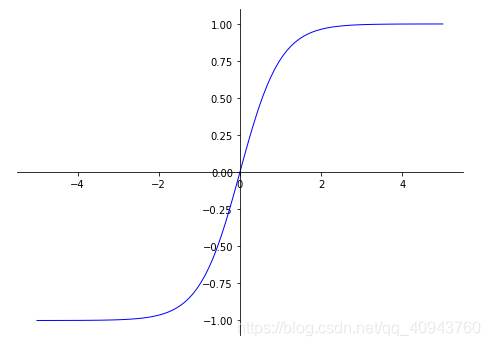
tanh會將輸入映射到(-1,1)區間:

#激活函數tanh
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
X=np.linspace(-5,5,100)
plt.figure(figsize=(8,6))
ax=plt.gca()#get current axis:獲取當前坐標系
#將該坐標系的右邊緣和上邊緣設為透明
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
#設置bottom是x軸
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
#設置left為y軸
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
ax.plot(X,tanh(X),color='blue',linewidth=1.0,linestyle="-")
plt.show()
開源框架
當神經網絡層數加深,可以加強捕捉分布的效果,可以簡單認為深度學習指深層神經網絡的學習;
當前有兩大主流的深度學習框架:Pytorch和Tensorflow;
Pytorch支持動態計算圖,使用起來更接近Python;
Tensorflow是靜態計算圖,使用起來就像一門新語言,據說簡單易用的keras已經無人維護,合并到tensorflow;
一個深度學習項目的運行流程一般是:
v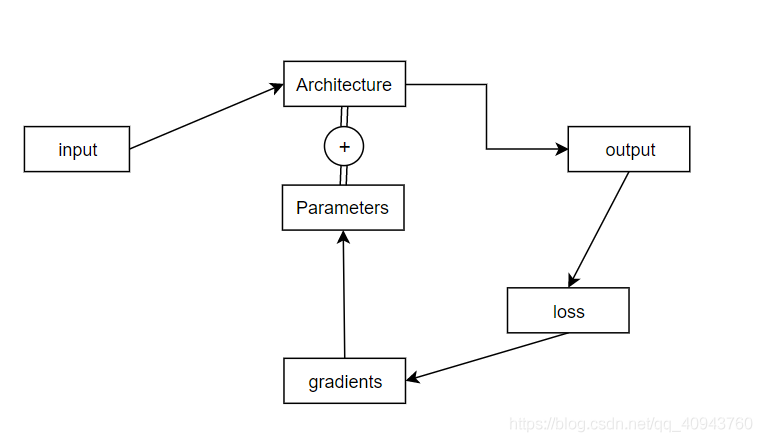
深度學習計算重復且體量巨大,所以需要將模型部署到GPU上,GPU的設計很適合加速深度學習計算,為了便于在GPU上開展深度學習實驗,人們開發了CUDA架構,現在大部分DL模型都是基于CUDA加速的
關于CUDA
1.什么是CUDA?
CUDA(ComputeUnified Device Architecture),是顯卡廠商NVIDIA推出的運算平臺。 CUDA是一種由NVIDIA推出的通用并行計算架構,該架構使GPU能夠解決復雜的計算問題。
2.什么是CUDNN?
NVIDIA cuDNN是用于深度神經網絡的GPU加速庫。它強調性能、易用性和低內存開銷。NVIDIA cuDNN可以集成到更高級別的機器學習框架中。
方向概覽
當前計算機視覺的發展相對于自然語言處理更加成熟,NLP的訓練比CV更耗費資源,CV模型相對較小;
在CV方向:
1.圖像分類(ResNet,DenseNet)
- 目標檢測ObjectDetection
- 風格遷移StyleTransfer
- CycleGAN:比如圖像中馬到斑馬,也可以從斑馬返回馬
- ImageCaptioning:從圖像生成描述文本,一般用CNN獲得feature,再輸入RNN獲得文本
2.在NLP方向
- 情感分析:分類影評數據
- QuestionAnswering:一段問題->給出答案
- Translation:可以用OpenNMT-py,OpenNMT-py是開源的seq->seq模型
- ChatBot聊天機器人,基于QuestionAnswering,目前剛起步
另外還有強化學習Deep Reinforcement Learning,從簡單的打磚塊游戲到著名的阿爾法Go;
以及預訓練語言模型:給一段話,讓機器繼續說下去,比如BERT,GPT2;
遷移學習
在CV中,NN的低層可以提取位置信息(邊,角等精細信息),高層提取抽象信息,所以低層的網絡可以反復使用,更改高層再訓練以適用其他任務
到此這篇關于深度學習簡介的文章就結束了,以后還會不斷更新深度學習的文章,更多相關深度學習文章請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章,希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 13個最常用的Python深度學習庫介紹
- python glom模塊的使用簡介
- Python 的lru_cache裝飾器使用簡介
- 深度學習詳解之初試機器學習
