目錄
- 一、要求
- 二、原理
- 三、信息增益的計算方法
- 四、實現過程
- 五、程序
- 六、遇到的問題
一、要求

二、原理
決策樹是一種類似于流程圖的結構,其中每個內部節點代表一個屬性上的“測試”,每個分支代表測試的結果,每個葉節點代表一個測試結果。類標簽(在計算所有屬性后做出的決定)。從根到葉的路徑代表分類規則。
決策樹學習的目的是為了產生一棵泛化能力強,即處理未見示例能力強的決策樹。因此如何構建決策樹,是后續預測的關鍵!而構建決策樹,就需要確定類標簽判斷的先后,其決定了構建的決策樹的性能。決策樹的分支節點應該盡可能的屬于同一類別,即節點的“純度”要越來越高,只有這樣,才能最佳決策。
經典的屬性劃分方法:
本次實驗采用了信息增益,因此下面只對信息增益進行介紹。
三、信息增益的計算方法

其中D為樣本集合,a為樣本集合中的屬性,Dv表示D樣本集合中a屬性為v的樣本集合。
Ent(x)函數是計算信息熵,表示的是樣本集合的純度信息,信息熵的計算方法如下:
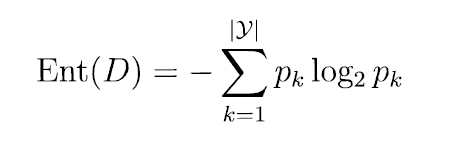
其中pk表示樣本中最終結果種類中其中一個類別所占的比例,比如有10個樣本,其中5個好,5個不好,則其中p1 = 5/10, p2 = 5/10。
一般而言,信息增益越大,則意味著使用屬性α來進行劃分所獲得的“純度提升”越大,因此在選擇屬性節點的時候優先選擇信息增益高的屬性!
四、實現過程
本次設計用到了pandas和numpy庫,主要利用它們來對數據進行快速的處理和使用。
首先將數據讀入:
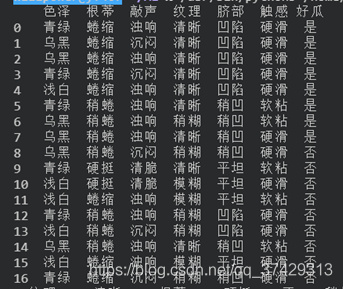
可以看到數據集的標簽是瓜的不同的屬性,而表格中的數據就是不同屬性下的不同的值等。
if(len(set(D.好瓜)) == 1):
#標記返回
return D.好瓜.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#選擇D中結果最多的為標記
cnt = D.groupby('好瓜').size()
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return tree
TreeGen函數是生成樹主函數,通過對它的遞歸調用,返回下一級樹結構(字典)來完成生成決策樹。
在生成樹過程中,有二個終止迭代的條件,第一個就是當輸入數據源D的所有情況結果都相同,那么將這個結果作為葉節點返回;第二個就是當沒有屬性可以再往下分,或者D中的樣本在A所有屬性下面的值都相同,那么就將D的所有情況中結果最多的作為葉節點返回。
其中Choose(D:pd.DataFrame, A:list)函數是選擇標簽的函數,其根據輸入數據源和剩下的屬性列表算出對應標簽信息增益,選擇能使信息增益最大的標簽返回
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
最后是結果:

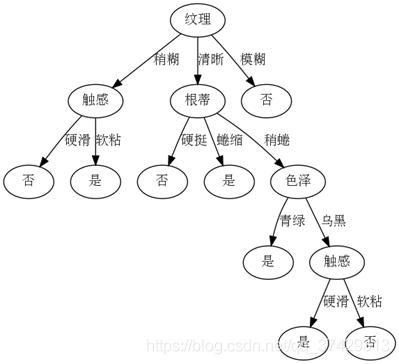
{‘紋理': {‘稍糊': {‘觸感': {‘硬滑': ‘否', ‘軟粘': ‘是'}}, ‘清晰': {‘根蒂': {‘硬挺': ‘否', ‘蜷縮': ‘是', ‘稍蜷': {‘色澤': {‘青綠': ‘是', ‘烏黑': {‘觸感': {‘硬滑': ‘是', ‘軟粘': ‘否'}}}}}}, ‘模糊': ‘否'}}
繪圖如下:
五、程序
主程序
#!/usr/bin/python3
# -*- encoding: utf-8 -*-
'''
@Description:決策樹:
@Date :2021/04/25 15:57:14
@Author :willpower
@version :1.0
'''
import pandas as pd
import numpy as np
import treeplot
import copy
import math
"""
@description :計算熵值
---------
@param :輸入為基本pandas類型dataFrame,其中輸入最后一行為實際結果
-------
@Returns :返回熵值,類型為浮點型
-------
"""
def CalcShang(D:pd.DataFrame):
setCnt = D.shape[0]
result = 0.0
# for i in D.groupby(D.columns[-1]).size().index:
#遍歷每一個值
for i in set(D[D.columns[-1]]):
#獲取該屬性下的某個值的次數
cnt = D.iloc[:,-1].value_counts()[i]
result = result + (cnt/setCnt)*math.log(cnt/setCnt, 2)
return (-1*result)
"""
@description :計算增益
---------
@param :輸入為DataFrame數據源,然后是需要計算增益的屬性值
-------
@Returns :返回增益值,浮點型
-------
"""
def CalcZengYi(D:pd.DataFrame, attr:str):
sumShang = CalcShang(D)
setCnt = D.shape[0]
result = 0.0
valus = D.groupby(attr).size()
for subVal in valus.index:
result = result + (valus[subVal]/setCnt)*CalcShang(D[D[attr] == subVal])
return sumShang - result
"""
@description :選擇最佳的屬性
---------
@param :輸入為數據源,以及還剩下的屬性列表
-------
@Returns :返回最佳屬性
-------
"""
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
"""
@description :檢查數據在每一個屬性下面的值是否相同
---------
@param :輸入為DataFrame以及剩下的屬性列表
-------
@Returns :返回bool值,相同返回1,不同返回0
-------
"""
def Check(D:pd.DataFrame, A:list):
for i in A:
if(len(set(D[i])) != 1):
return 0
return 1
"""
@description :生成樹主函數
---------
@param :數據源DataFrame以及所有類型
-------
@Returns :返回生成的字典樹
-------
"""
def TreeGen(D:pd.DataFrame, A:list):
if(len(set(D.好瓜)) == 1):
#標記返回
return D.好瓜.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#選擇D中結果最多的為標記
cnt = D.groupby('好瓜').size()
#找到結果最多的結果
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return tree
"""
@description :驗證集
---------
@param :輸入為待驗證的數據(最后一列為真實結果)以及決策樹模型
-------
@Returns :無
-------
"""
def Test(D:pd.DataFrame, model:dict):
for i in range(D.shape[0]):
data = D.iloc[i]
subModel = model
while(1):
attr = list(subModel)[0]
subModel = subModel[attr][data[attr]]
if(type(subModel).__name__ != 'dict'):
print(subModel, end='')
break
print('')
name = ['色澤', '根蒂', '敲聲', '紋理', '臍部', '觸感', '好瓜']
df = pd.read_csv('./savedata.txt', names=name)
# CalcZengYi(df, '色澤')
resultTree = TreeGen(df, name)
print(resultTree)
# print(df[name[:-1]])
Test(df[name[:-1]], resultTree)
treeplot.plot_model(resultTree,"resultTree.gv")
繪圖程序
from graphviz import Digraph
def plot_model(tree, name):
g = Digraph("G", filename=name, format='png', strict=False)
first_label = list(tree.keys())[0]
g.node("0", first_label)
_sub_plot(g, tree, "0")
g.view()
root = "0"
def _sub_plot(g, tree, inc):
global root
first_label = list(tree.keys())[0]
ts = tree[first_label]
for i in ts.keys():
if isinstance(tree[first_label][i], dict):
root = str(int(root) + 1)
g.node(root, list(tree[first_label][i].keys())[0])
g.edge(inc, root, str(i))
_sub_plot(g, tree[first_label][i], root)
else:
root = str(int(root) + 1)
g.node(root, tree[first_label][i])
g.edge(inc, root, str(i))
./savedata.txt
青綠,蜷縮,濁響,清晰,凹陷,硬滑,是
烏黑,蜷縮,沉悶,清晰,凹陷,硬滑,是
烏黑,蜷縮,濁響,清晰,凹陷,硬滑,是
青綠,蜷縮,沉悶,清晰,凹陷,硬滑,是
淺白,蜷縮,濁響,清晰,凹陷,硬滑,是
青綠,稍蜷,濁響,清晰,稍凹,軟粘,是
烏黑,稍蜷,濁響,稍糊,稍凹,軟粘,是
烏黑,稍蜷,濁響,清晰,稍凹,硬滑,是
烏黑,稍蜷,沉悶,稍糊,稍凹,硬滑,否
青綠,硬挺,清脆,清晰,平坦,軟粘,否
淺白,硬挺,清脆,模糊,平坦,硬滑,否
淺白,蜷縮,濁響,模糊,平坦,軟粘,否
青綠,稍蜷,濁響,稍糊,凹陷,硬滑,否
淺白,稍蜷,沉悶,稍糊,凹陷,硬滑,否
烏黑,稍蜷,濁響,清晰,稍凹,軟粘,否
淺白,蜷縮,濁響,模糊,平坦,硬滑,否
青綠,蜷縮,沉悶,稍糊,稍凹,硬滑,否
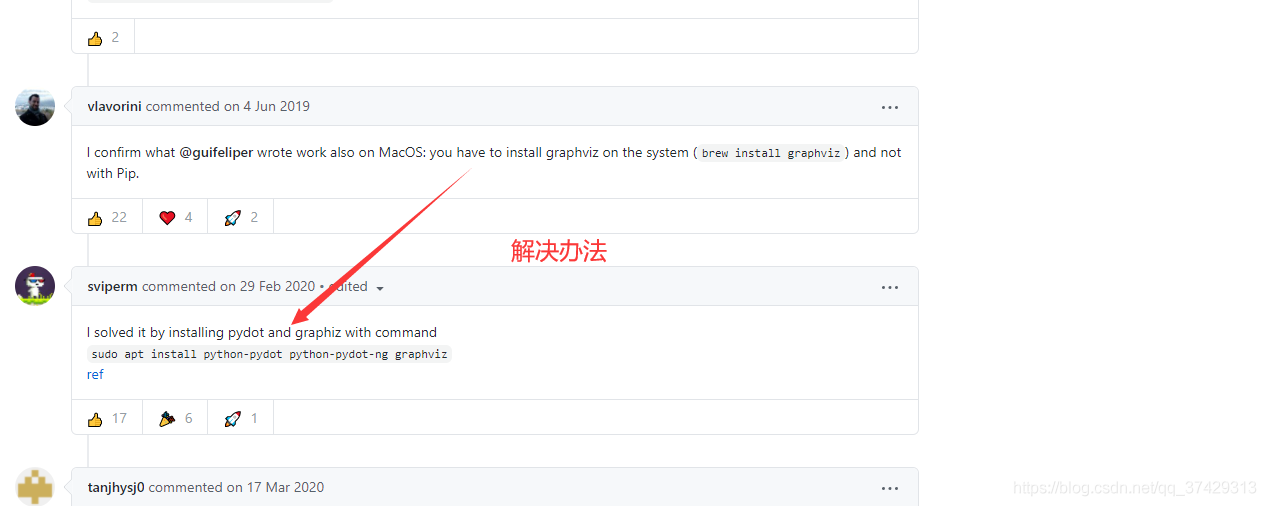
六、遇到的問題
graphviz Not a directory: ‘dot'
解決辦法
到此這篇關于Python機器學習之決策樹的文章就介紹到這了,更多相關Python決策樹內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python機器學習算法之決策樹算法的實現與優缺點
- python機器學習實現決策樹
- Python機器學習算法庫scikit-learn學習之決策樹實現方法詳解
- python機器學習理論與實戰(二)決策樹
- Python機器學習之決策樹算法
- python機器學習之決策樹分類詳解
- Python機器學習之決策樹算法實例詳解
- 機器學習python實戰之決策樹
- 分析機器學習之決策樹Python實現
