目錄
- 向量空間模型VSM:
- TF-IDF權重計算:
- 余弦相似度的計算:
- 文本比較實例:
- 余弦相似度代碼實現:
向量空間模型VSM:
VSM的介紹:
一個文檔可以由文檔中的一系列關鍵詞組成,而VSM則是用這些關鍵詞的向量組成一篇文檔,其中的每個分量代表詞項在文檔中的相對重要性。
VSM的例子:
比如說,一個文檔有分詞和去停用詞之后,有N個關鍵詞(或許去重后就有M個關鍵詞),文檔關鍵詞相應的表示為(d1,d2,d3,...,dn),而每個關鍵詞都有一個對應的權重(w1,w1,...,wn)。對于一篇文檔來說,或許所含的關鍵詞項比較少,文檔向量化后的向量維度可能不是很大。而對于多個文檔(2篇文檔或兩篇文檔以上),則需要合并所有文檔的關鍵詞(關鍵詞不能重復),形成一個不重復的關鍵詞集合,這個關鍵詞集合的個數就是每個文檔向量化后的向量的維度。打個比方說,總共有2篇文檔A和B,其中A有5個不重復的關鍵詞(a1,a2,a3,a4,a5),B有6個關鍵詞(b1,b2,b3,b4,b5,b6),而且假設b1和a3重復,則可以形成一個簡單的關鍵詞集(a1,a2,a3,a4,a5,,b2,b3,b4,b5,b6),則A文檔的向量可以表示為(ta1,ta2,ta3,ta4,ta5,0,0,0,0,0),B文檔可以表示為(0,0,tb1,0,0,tb2,tb3,tb4,tb5,tb6),其中的tb表示的對應的詞匯的權重。
最后,關鍵詞的權重一般都是有TF-IDF來表示,這樣的表示更加科學,更能反映出關鍵詞在文檔中的重要性,而如果僅僅是為數不大的文檔進行比較并且關鍵詞集也不是特別大,則可以采用詞項的詞頻來表示其權重(這種表示方法其實不怎么科學)。
TF-IDF權重計算:
TF的由來:
以前在文檔搜索的時候,我們只考慮詞項在不在文檔中,在就是1,不在就是0。其實這并不科學,因為那些出現了很多次的詞項和只出現了一次的詞項會處于等同的地位,就是大家都是1.按照常理來說,文檔中詞項出現的頻率越高,那么就意味著這個詞項在文檔中的地位就越高,相應的權重就越大。而這個權重就是詞項出現的次數,這樣的權重計算結果被稱為詞頻(term frequency),用TF來表示。
IDF的出現:
在用TF來表示權重的時候,會出現一個嚴重的問題:就是所有 的詞項都被認為是一樣重要的。但在實際中,某些詞項對文本相關性的計算來說毫無意義,舉個例子,所有的文檔都含有汽車這個詞匯,那么這個詞匯就沒有區分能力。解決這個問題的直接辦法就是讓那些在文檔集合中出現頻率較高的詞項獲得一個比較低的權重,而那些文檔出現頻率較低的詞項應該獲得一個較高的權重。
為了獲得出現詞項T的所有的文檔的數目,我們需要引進一個文檔頻率df。由于df一般都比較大,為了便于計算,需要把它映射成一個較小的范圍。我們假設一個文檔集里的所有的文檔的數目是N,而詞項的逆文檔頻率(IDF)。計算的表達式如下所示:
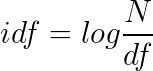
通過這個idf,我們就可以實現罕見詞的idf比較高,高頻詞的idf比較低。
TF-IDF的計算:
TF-IDF = TF * IDF
有了這個公式,我們就可以對文檔向量化后的每個詞給予一個權重,若不含這個詞,則權重為0。
余弦相似度的計算:
有了上面的基礎知識,我們可以將每個分好詞和去停用詞的文檔進行文檔向量化,并計算出每一個詞項的權重,而且每個文檔的向量的維度都是一樣的,我們比較兩篇文檔的相似性就可以通過計算這兩個向量之間的cos夾角來得出。下面給出cos的計算公式:

分母是每篇文檔向量的模的乘積,分子是兩個向量的乘積,cos值越趨向于1,則說明兩篇文檔越相似,反之越不相似。
文本比較實例:
對文本進行去停用詞和分詞:
文本未分詞前,如下圖所示:
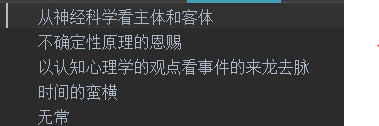
文本分詞和去停用詞后,如下圖所示:

詞頻統計和文檔向量化
對經過上一步處理過的文檔,我們可以統計每個文檔中的詞項的詞頻,并且將其向量化,下面我直接給出文檔向量化之后的結果。注意:在這里由于只是比較兩篇文檔的相似性,所以我只用了tf來作為詞項的權重,并未使用tf-idf:

向量化后的結果是:
[1,1,1,1,1,1,1,1,1,1,1,1,1,1]
- 兩篇文檔進行相似度的計算,我會給出兩篇文檔的原文和最終計算的相似度:
文檔原文如下所示:

文檔A的內容

文檔B的內容

余弦相似度代碼實現:
import math
# 兩篇待比較的文檔的路徑
sourcefile = '1.txt'
s2 = '2.txt'
# 關鍵詞統計和詞頻統計,以列表形式返回
def Count(resfile):
t = {}
infile = open(resfile, 'r', encoding='utf-8')
f = infile.readlines()
count = len(f)
# print(count)
infile.close()
s = open(resfile, 'r', encoding='utf-8')
i = 0
while i count:
line = s.readline()
# 去換行符
line = line.rstrip('\n')
# print(line)
words = line.split(" ")
# print(words)
for word in words:
if word != "" and t.__contains__(word):
num = t[word]
t[word] = num + 1
elif word != "":
t[word] = 1
i = i + 1
# 字典按鍵值降序
dic = sorted(t.items(), key=lambda t: t[1], reverse=True)
# print(dic)
# print()
s.close()
return (dic)
def MergeWord(T1,T2):
MergeWord = []
duplicateWord = 0
for ch in range(len(T1)):
MergeWord.append(T1[ch][0])
for ch in range(len(T2)):
if T2[ch][0] in MergeWord:
duplicateWord = duplicateWord + 1
else:
MergeWord.append(T2[ch][0])
# print('重復次數 = ' + str(duplicateWord))
# 打印合并關鍵詞
# print(MergeWord)
return MergeWord
# 得出文檔向量
def CalVector(T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in range(len(T1)):
TermFrequence = T1[ch][1]
word = T1[ch][0]
i = 0
while i len(MergeWord):
if word == MergeWord[i]:
TF1[i] = TermFrequence
break
else:
i = i + 1
# print(TF1)
return TF1
def CalConDis(v1,v2,lengthVector):
# 計算出兩個向量的乘積
B = 0
i = 0
while i lengthVector:
B = v1[i] * v2[i] + B
i = i + 1
# print('乘積 = ' + str(B))
# 計算兩個向量的模的乘積
A = 0
A1 = 0
A2 = 0
i = 0
while i lengthVector:
A1 = A1 + v1[i] * v1[i]
i = i + 1
# print('A1 = ' + str(A1))
i = 0
while i lengthVector:
A2 = A2 + v2[i] * v2[i]
i = i + 1
# print('A2 = ' + str(A2))
A = math.sqrt(A1) * math.sqrt(A2)
print('兩篇文章的相似度 = ' + format(float(B) / A,".3f"))
T1 = Count(sourcefile)
print("文檔1的詞頻統計如下:")
print(T1)
print()
T2 = Count(s2)
print("文檔2的詞頻統計如下:")
print(T2)
print()
# 合并兩篇文檔的關鍵詞
mergeword = MergeWord(T1,T2)
# print(mergeword)
# print(len(mergeword))
# 得出文檔向量
v1 = CalVector(T1,mergeword)
print("文檔1向量化得到的向量如下:")
print(v1)
print()
v2 = CalVector(T2,mergeword)
print("文檔2向量化得到的向量如下:")
print(v2)
print()
# 計算余弦距離
CalConDis(v1,v2,len(v1))
到此這篇關于python實現余弦相似度文本比較的文章就介紹到這了,更多相關python余弦相似度內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python 余弦相似度與皮爾遜相關系數 計算實例
- Python 求向量的余弦值操作
- python代碼如何實現余弦相似性計算
- 余弦相似性計算及python代碼實現過程解析
- Python繪制正余弦函數圖像的方法
- Python使用matplotlib繪制余弦的散點圖示例
- Python使用matplotlib繪制正弦和余弦曲線的方法示例
