目錄
- 一、創建一個進程
- 二、設置進程名
- 三、守護進程
- 四、join()
- 五、強制結束進程
- 六、進程退出狀態碼
- 七、日志
- 八、派生進程
一、創建一個進程
要創建一個進程,最簡單的方式是用一個目標函數實例化一個Process對象,然后與threading一樣調用start()函數讓它工作。示例如下:
import multiprocessing
def worker():
for i in range(3):
print(i)
if __name__=="__main__":
p = multiprocessing.Process(target=worker)
p.start()
運行之后,效果如下:

需要注意的是,multiprocessing庫在Windows創建進程必須在if __name__=="__main__":中,這是 Windows 上多進程的實現問題。在 Windows 上,子進程會自動 import 啟動它的這個文件,而在 import 的時候是會執行這些語句的。如果直接創建就會無限遞歸創建子進程報錯。所以必須把創建子進程的部分用那個 if 判斷保護起來,import 的時候 __name__ 不是 __main__ ,就不會遞歸運行了。
二、設置進程名
在threading線程中,我們可以通過其參數name設置線程名,同樣的我們也可以通過name參數設置其進程的名字。示例如下:
import multiprocessing
import time
def worker():
print(multiprocessing.current_process().name, "start")
time.sleep(2)
print(multiprocessing.current_process().name, "end")
if __name__ == "__main__":
p1 = multiprocessing.Process(name='p1', target=worker)
p2 = multiprocessing.Process(name='p2', target=worker)
p3 = multiprocessing.Process(name='p3', target=worker)
p1.start()
p2.start()
p3.start()
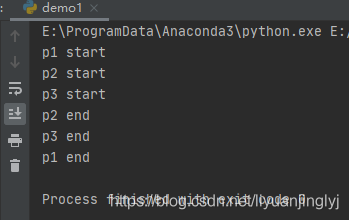
運行之后,效果如下:
三、守護進程
和線程一樣,在所有子進程沒有退出之前,主程序是不會退出的。有時候,我們可能需要啟動一個后臺進程,它可以一直運行而不阻塞主程序退出。
要標志一個守護進程,可以將其添加第3個參數daemon,設置為True。默認值為False,不作為守護進程。示例如下:
import multiprocessing
import time
def worker():
print(multiprocessing.current_process().name, "start")
time.sleep(1)
print(multiprocessing.current_process().name, "end")
def worker2():
print(multiprocessing.current_process().name, "start")
time.sleep(2)
print(multiprocessing.current_process().name, "end")
if __name__ == "__main__":
p1 = multiprocessing.Process(name='p1', target=worker)
p2 = multiprocessing.Process(name='p2', target=worker2, daemon=True)
p3 = multiprocessing.Process(name='p3', target=worker2, daemon=True)
p1.start()
p2.start()
p3.start()
運行之后,效果如下:
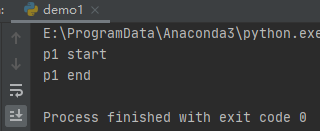
p2,p3為守護進程,但p1不是所以執行1秒之后,就退出主程序了,也就沒有打印p2p3的內容。但是其依舊在執行中,直到執行完成。
四、join()
同樣的,如果你期望強制等待一個守護進程的結束,可以增加join()函數。還是上面的代碼,示例如下:
import multiprocessing
import time
def worker():
print(multiprocessing.current_process().name, "start")
time.sleep(1)
print(multiprocessing.current_process().name, "end")
def worker2():
print(multiprocessing.current_process().name, "start")
time.sleep(2)
print(multiprocessing.current_process().name, "end")
if __name__ == "__main__":
p1 = multiprocessing.Process(name='p1', target=worker)
p2 = multiprocessing.Process(name='p2', target=worker2, daemon=True)
p3 = multiprocessing.Process(name='p3', target=worker2, daemon=True)
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
運行之后,和設置進程名的運行結果一樣,這里不在展示。唯一與守護進程代碼的區別就是最后三行join()函數代碼。當然,也可以像線程一樣,給join()函數傳入一個時間,超過這個時間,主進程不再等待。
五、強制結束進程
如果一個進程已經掛起或者不小心進入了死鎖狀態,那么這個時候,我們往往會強制的結束進程。對一個進程對象調用terminate()會結束子進程。示例如下:
import multiprocessing
import time
def worker():
print(multiprocessing.current_process().name, "start")
time.sleep(5)
print(multiprocessing.current_process().name, "end")
if __name__ == "__main__":
p1 = multiprocessing.Process(name='p1', target=worker)
p1.start()
print("是否還在運行", p1.is_alive())
p1.terminate()
print("是否還在運行", p1.is_alive())
p1.join()
print("是否還在運行", p1.is_alive())
運行之后,輸出如下:

終止進程后要使用join()函數等待進程的退出。使進程管理代碼有足夠的時間更新對象的狀態,以反應進程已經終止。
六、進程退出狀態碼
進程退出時,生成的狀態碼可以通過exitcode屬性訪問。下表就是其狀態碼的取值范圍以及其意義:
| 退出碼 |
含義 |
| 0 |
未生成任何錯誤 |
| >0 |
進程有一個錯誤,并以該錯誤碼退出 |
| 0 |
進程以一個-1*exitcodde信號結束 |
|
測試如下:
import multiprocessing
import time
def worker():
print(multiprocessing.current_process().name, "start")
time.sleep(5)
print(multiprocessing.current_process().name, "end")
if __name__ == "__main__":
p1 = multiprocessing.Process(name='p1', target=worker)
p2 = multiprocessing.Process(name='p2', target=worker)
p1.start()
p2.start()
print("是否還在運行", p1.is_alive())
p1.terminate()
print("是否還在運行", p1.is_alive())
print(p1.exitcode)
p1.join()
print("是否還在運行", p1.is_alive())
print(p1.exitcode)
time.sleep(5.5)
print(p2.exitcode)
運行之后,效果如下:

可以看到,強制退出的進程狀態碼為負數,正常退出的進程狀態碼為0。
七、日志
調試并發問題時,如果能夠訪問multiprocessing所提供對象的內部狀態,那么這會很有用。在實際的項目中,我們可以使用一個方便的模塊級函數啟用日志記錄,它使用logging建立一個日志記錄器對象,并增加一個處理器,使日志消息被發送到標準錯誤通道。
示例如下:
import multiprocessing
import logging
import sys
def worker():
print("運行工作進程")
sys.stdout.flush()
if __name__ == "__main__":
multiprocessing.log_to_stderr(logging.DEBUG)
p1 = multiprocessing.Process(name='p1', target=worker)
p1.start()
p1.join()
運行之后,效果如下:

八、派生進程
與線程一樣,我們可以自定義進程,而不必只是傳入一個函數進行進程的創建。
創建的進程的方式也是派生自進程類即可。示例如下:
import multiprocessing
class WorkerProcess(multiprocessing.Process):
def run(self):
print(self.name)
return
if __name__ == "__main__":
for i in range(5):
p = WorkerProcess()
p.start()
p.join()
運行之后,效果如下:
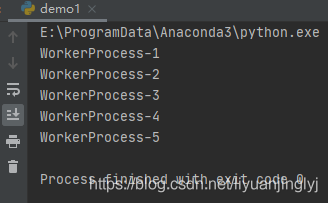
multiprocessing庫的進程知識與threading一樣長,因為本篇的內容已經夠長了,剩下的知識我們將在下一篇博文中接著講解。
到此這篇關于像線程一樣管理進程的Python multiprocessing庫的文章就介紹到這了,更多相關Python multiprocessing庫內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 分析Python感知線程狀態的解決方案之Event與信號量
- Python爬蟲之線程池的使用
- Python多線程編程之threading模塊詳解
- 深入理解python多線程編程
- Python一些線程的玩法總結
