1.GPU 占用率,利用率
輸入nvidia-smi來觀察顯卡的GPU內存占用率(Memory-Usage),顯卡的GPU利用率(GPU-util)
GPU內存占用率(Memory-Usage) 往往是由于模型的大小以及batch size的大小,來影響這個指標 顯卡的GPU利用率(GPU-util) 往往跟代碼有關,有更多的io運算,cpu運算就會導致利用率變低。
比如打印loss, 輸出圖像,等等
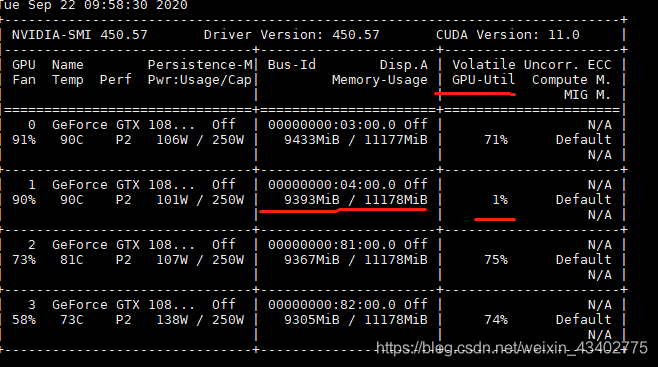
這個時候發現,有一塊卡的利用率經常跳到1%,而其他三塊卡經常維持在70%以上
2.原因分析
當沒有設置好CPU的線程數時,Volatile GPU-Util參數是在反復的跳動的,0%,20%,70%,95%,0%。
這樣停息1-2 秒然后又重復起來。其實是GPU在等待數據從CPU傳輸過來,當從總線傳輸到GPU之后,GPU逐漸起計算來,利用率會突然升高,但是GPU的算力很強大,0.5秒就基本能處理完數據,所以利用率接下來又會降下去,等待下一個batch的傳入。
因此,這個GPU利用率瓶頸在內存帶寬和內存介質上以及CPU的性能上面。
最好當然就是換更好的四代或者更強大的內存條,配合更好的CPU。
3.解決方法:
(1)為了提高利用率,首先要將num_workers(線程數)設置得體,4,8,16是幾個常選的幾個參數。本人測試過,將num_workers設置的非常大,例如,24,32,等,其效率反而降低,因為模型需要將數據平均分配到幾個子線程去進行預處理,分發等數據操作,設高了反而影響效率。當然,線程數設置為1,是單個CPU來進行數據的預處理和傳輸給GPU,效率也會低。其次,當你的服務器或者電腦的內存較大,性能較好的時候,建議打開pin_memory打開,就省掉了將數據從CPU傳入到緩存RAM里面,再給傳輸到GPU上;為True時是直接映射到GPU的相關內存塊上,省掉了一點數據傳輸時間。
(2) 另外的一個方法是,在PyTorch這個框架里面,數據加載Dataloader上做更改和優化,包括num_workers(線程數),pin_memory,會提升速度。解決好數據傳輸的帶寬瓶頸和GPU的運算效率低的問題。在TensorFlow下面,也有這個加載數據的設置。
(3) 修改代碼(我遇到的問題)
每個iteration 都寫文件了,這個就會導致cpu 一直運算,GPU 等待

造成GPU利用率低還有其他原因
1. CPU數據讀取更不上:讀到內存+多線程+二進制文件(比如tf record)
2. GPU溫度過高,使用功率太大:每次少用幾個GPU,降低功耗(但是多卡的作用何在?)
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- 解決pytorch GPU 計算過程中出現內存耗盡的問題
- pytorch 限制GPU使用效率詳解(計算效率)
- Pytorch GPU顯存充足卻顯示out of memory的解決方式
