前言:最近在構建網絡的時候����,有一些層參數一樣,于是就沒有定義新的層��,直接重復使用了原來已經有的層,發現效果和模型大小都沒有什么變化��,心中產生了疑問:定義的網絡結構層能否重復使用�?因此接下來利用了一個小模型網絡實驗了一下。
一�、網絡結構一:(連續使用相同的層)
1����、網絡結構如下所示:
class Cnn(nn.Module):
def __init__(self):
super(Cnn, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels = 3, #(, 64, 64, 3)
out_channels = 16,
kernel_size = 3,
stride = 1,
padding = 1
), ##( , 64, 64, 16)
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2)
) ##( , 32, 32, 16)
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(32,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv4 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.out = nn.Linear(64*8*8, 6)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
定義了一個卷積層conv4�,接下來圍繞著這個conv4做一些變化。打印一下網絡結構:
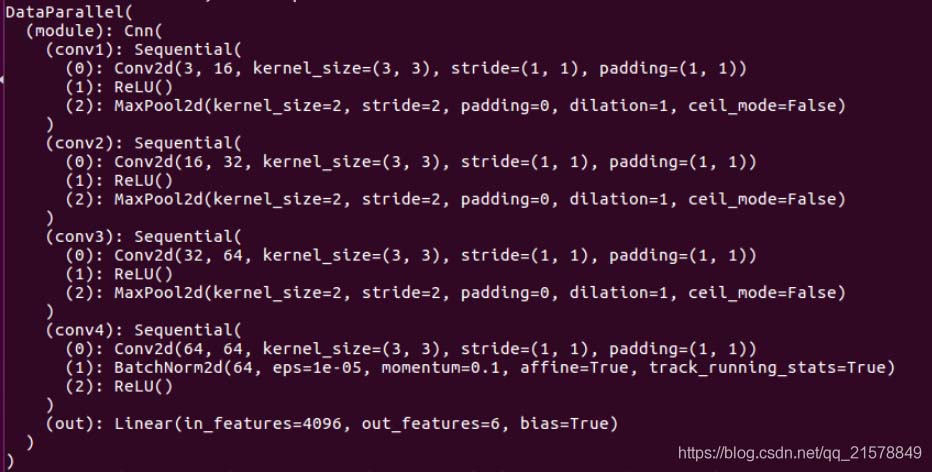
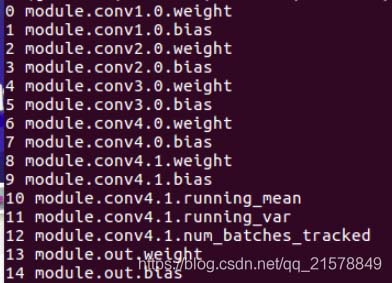
和想象中的一樣�����,其中
nn.BatchNorm2d # 對應上面的 module.conv4.1.*
激活層沒有參數所以直接跳過
2���、改變一下forward():
連續使用兩個conv4層:
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
打印網絡結構:
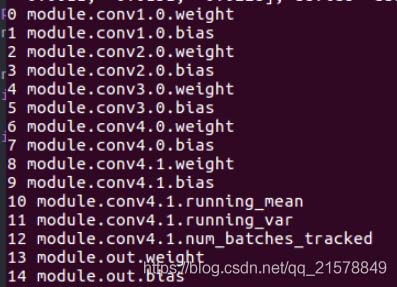
和1.1中的結構一樣�����,conv4沒有生效。
二�����、網絡結構二:(間斷使用相同的層)
網絡結構多定義一個和conv4一樣的層conv5��,同時間斷使用conv4:
self.conv4 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv5 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.out = nn.Linear(64*8*8, 6)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
打印網絡結構:
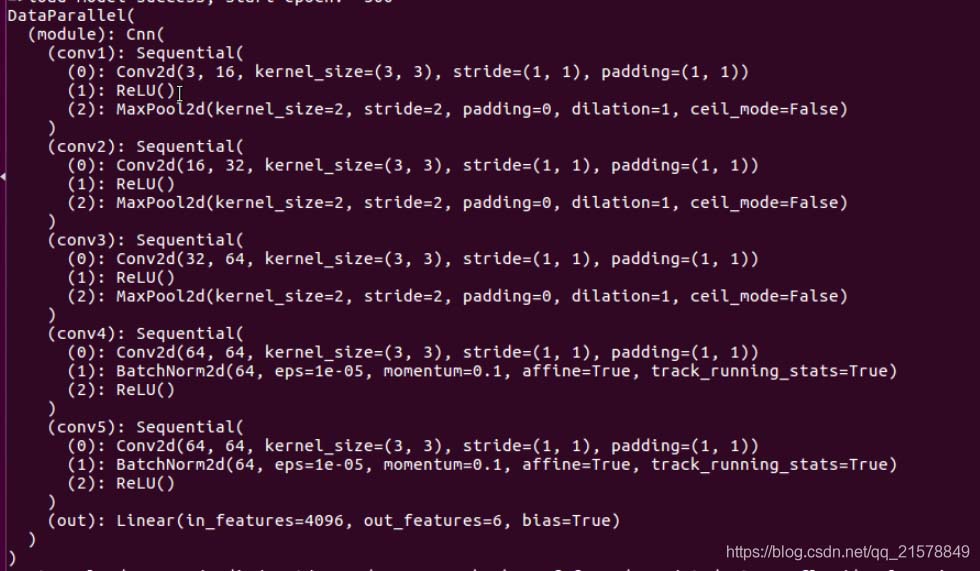

果不其然����,新定義的conv5有效���,conv4還是沒有生效�����。
本來以為���,使用重復定義的層會像conv4.0,conv4.1,…這樣下去��,看樣子是不能重復使用定義的層。
Pytorch_5.7 使用重復元素的網絡--VGG
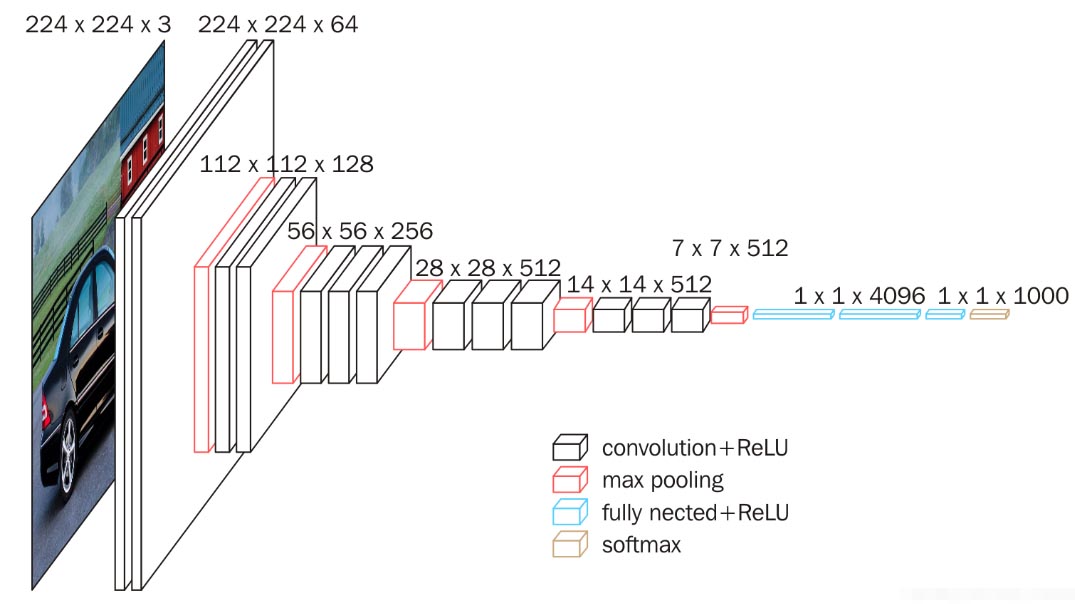
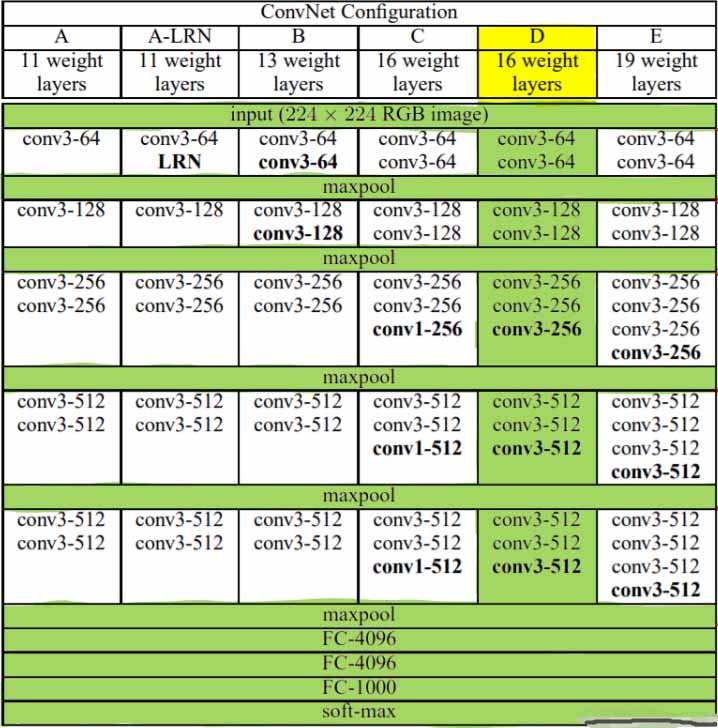
5.7.1 VGG塊
VGG引入了Block的概念 作為模型的基礎模塊
import time
import torch
from torch import nn, optim
import pytorch_deep as pyd
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels,kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 這⾥會使寬⾼減半
return nn.Sequential(*blk)
實現VGG_11網絡
8個卷積層和3個全連接
def vgg_11(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷積層部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每經過⼀個vgg_block都會使寬⾼減半
net.add_module("vgg_block_" + str(i+1),vgg_block(num_convs, in_channels, out_channels))
# 全連接層部分
net.add_module("fc", nn.Sequential(
pyd.FlattenLayer(),
nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
ratio = 8
small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio),(2, 128//ratio, 256//ratio),(2, 256//ratio, 512//ratio), (2, 512//ratio,512//ratio)]
fc_features = 512 * 7 * 7 # c *
fc_hidden_units = 4096 # 任意
net = vgg_11(small_conv_arch, fc_features // ratio, fc_hidden_units //ratio)
print(net)
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
訓練數據
batch_size = 32
# 如出現“out of memory”的報錯信息,可減⼩batch_size或resize
train_iter, test_iter = pyd.load_data_fashion_mnist(batch_size,resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
pyd.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
training on cuda
epoch 1, loss 0.5166, train acc 0.810, test acc 0.872,time 57.6 sec
epoch 2, loss 0.1557, train acc 0.887, test acc 0.902,time 57.9 sec
epoch 3, loss 0.0916, train acc 0.900, test acc 0.907,time 57.7 sec
epoch 4, loss 0.0609, train acc 0.912, test acc 0.915,time 57.6 sec
epoch 5, loss 0.0449, train acc 0.919, test acc 0.914,time 57.4 sec
以上為個人經驗���,希望能給大家一個參考,也希望大家多多支持腳本之家���。
您可能感興趣的文章:- 淺談PyTorch的可重復性問題(如何使實驗結果可復現)
- 對pytorch網絡層結構的數組化詳解
- pytorch構建網絡模型的4種方法
- pytorch 更改預訓練模型網絡結構的方法
